Processing Analysis Services Objects Dynamically by using Integration Services
Users often ask how you can use the Analysis Services Processing task in Integration Services to process new objects. The problem is that the task UI forces you to choose the items to process, so if they don't exist, you can't choose them.
This demo (originally part of a longer white paper, available from the Microsoft Download Center), shows you how you can use package variables to get a list of available Analysis Services objects and then pass the names in the list to a Foreach Loop for processing.
In the original walkthrough, we created and processed [[data mining]] models, but you could just as easily use a query that returns a list of unprocessed dimensions, or a list of the tabular models that have not been updated recently, and then process just the target objects.
The key takeaway in this demo is that Integration Services provides a component that lets you run all kinds of useful and interesting queries against an Analysis Services database: the Execute Data Mining Query task.
Surprised? That's right; the Data Mining Query task in the SSIS control flow can execute many different kinds of DMX statements, not just prediction queries in "pure DMX". And, because the MDX parser and the DMX parser are the same, you can execute queries using the DMVs provided in SQL Server 2008, and get all kinds of information about the objects on an Analysis Services instance.
The diagram below shows the overall task flow.
Notice that this package saves the results of the Data Mining Query task to a table in the relational engine. That way, you can work with the list of objects that is returned more easily. (You could probably keep the results in a variable in memory as well, but writing the results to a table makes it a bit easier to debug.)
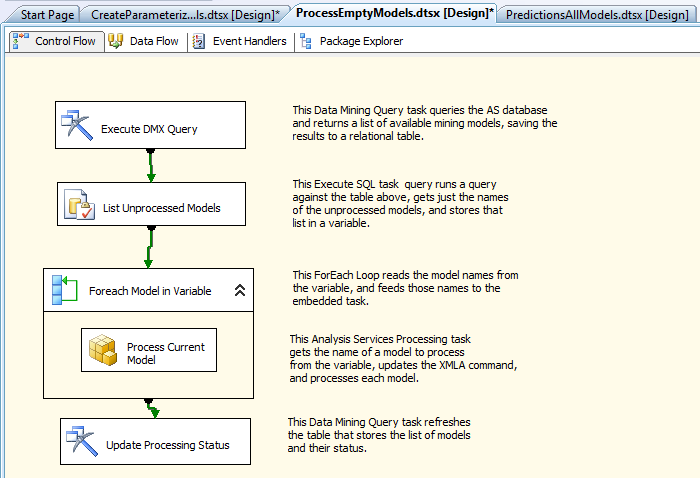
The actual processing of SSAS objects takes part within a Foreach Loop container. We use an Execute SQL task to retrieve the list of unprocessed objects from the relational table, and puts the object list in an ADO.NET rowset variable. The Foreach Loop container takes the rowset variable contents as input, and processes each model serially, using the embedded Analysis Services Processing task. Finally you update the status of the models in the relational database, so you can use the information for reporting..
Create package and package variables
- Create a new Integration Services package and name it ProcessEmptyModels.dtsx.
- With the package background selected, add a user variable, objModelsList. This variable will have package scope and will be used to store the list of models that are available on the server.
Add a Data Mining Query task that gets a list of objects
- Create a new Data Mining Query task, and name it Execute DMX Query.
- In the Data Mining Query Task Editor, on the Mining Model tab, specify the Analysis Services database that contains the objects you want to process.
- Choose a mining structure. Note that you don't need to actually *use* this mining structure, or the models based on it; you just need to choose a valid combination of mining structure and model to ensure that the task validates. If you don't have a valid mining structure or mining model, you could turn validation off, but we recommend creating a small sample mining structure and model. Mining models are not like cubes; they are surprisingly small, just metadata and a collection of statistics. Unless you are trying to train a model on millions of rows of data, you won't notice any impact from having an unused mining structure and model in your solution.
- Click the Query tab. Here, instead of creating an actual prediction query, you will create a query against one of the DMVs provided by Analysis Services. In the original walkthrough, we got a list of the existing mining models, including a column that indicates when the model was last processed.
SELECT MODEL_NAME, IS_POPULATED, LAST_PROCESSED, TRAINING_SET_SIZE
FROM $system.DM_SCHEMA_MINING_MODELSHowever, if you wanted to check the status of cubes (or tabular models) on an AS instance, you could use a query like this one:
SELECT [CATALOG_NAME], LAST_DATA_UPDATE
FROM $system.MDSCHEMA_CUBES
- On the Output tab, for Connection, select the relational database where you will store the results. For this solution, we used <local server name>/DM_Reporting.
- For Output table, type a table name. For our solution, we used the table, tmpProcessingStatus. Select the option, Drop and re-create the output table.
Create an Execute SQL task that gets just the unprocessed objects
- Add a new Execute SQL Task, and name it List Unprocessed Models.
- Connect it to the previous task.
- In the Execute SQL Task Editor, for Connection, use an OLEDB connection, and choose the server name: for example, <local server name>/DM_Reporting.
- For Result set, select Full result set.
- For SQLSourceType, select Direct input.
- For SQL Statement, type the following query text:
SELECT MODEL_NAME from tmpProcessingStatus
- On the Result Set tab, assign the columns in the result set to variables. There is only one column in the result set, so you assign the variable, User::objModelList to ResultSet 0 (zero).
Create a Foreach Loop container to iterate over object list
Use the combination of an Execute SQL task and a Foreach Loop container to load the name of an Analysis Services object into the variable, and insert the variable contents into the processing command template..
- Create a new Foreach Loop container and name it Foreach Model in Variable.
- Connect it to the previous task.
- With the Foreach Loop container selected, open the SSIS Variables window, and add three variables. They should all be scoped to the Foreach Loop container:
strModelName1 String
strXMLAProcess1 String
strXMLAProcess2 StringYou store the template for the processing command in strXMLAProcess1, and then use an SSIS expression to alter the command and save the changes to strXMLAProcess2.
- In the Foreach Loop Editor, set the enumerator type to Foreach ADO enumerator.
- In the Enumerator configuration pane, set ADO object source variable to User::objModelList.
- Set Enumeration mode to Rows in first table only.
- In the Variables mapping pane, assign the variable, User::strModelName1 to Index 1. This means that each row of the single-column table returned by the query will be fed into the variable.
Add an Analysis Services Processing task to the Foreach Loop
Here's the fun part.
Remember, the problem with the editor for this task is that you have to connect to an Analysis Services database, and then choose from a list of objects that can be processed. However, your objects don't exist yet, therefore you can’t use the UI to choose the objects. So how can you specify which objects to process?
The solution is to use an expression to alter the contents of the property, ProcessingCommand. Remember that you used the variable, strXMLAProcess1, to store the basic XMLA syntax for processing a model (or a cube, dimension, etc.) Instead of the actual model name, you insert a placeholder (“ModelNameHere”) that can be modified later when you read the variable.
You alter the command using an expression, and write the new XMLA out to a second variable, strXMLAProcess2.
- Drag a new Analysis Services Processing task into the Foreach Loop container you just created. Name it Process Current Model.
- With the Foreach Loop selected, open the SSIS Variables pane, and select this variable:
User::strXMLAProcess2
- In the Properties pane, select Evaluate as expression and set it to True.
- Now, for the value of the variable, type or build this expression:
REPLACE( @[User::strXMLAProcess1] , "ModelNameHere", @[User::strModelName1] )
- In the Analysis Services Processing Task Editor, click Expressions, and expand the list of expressions.
- Select ProcessingCommand and type the variable name as follows:
@[User::strXMLAProcess2]
You might ask, why not create the model and then process it, within the same Foreach Loop? That's one way to do it, but if you are creating multiple models it's better to isolate the processes of creating models (metadata) from the process of populating the models with training data.
For one thing, processing can take a long time. Processing can also fail for various reasons -- data sources might not be available, a data type might be wrong for the algorithm, etc. It is much easier to audit and debug such issues if you keep model creation and model processing in separate packages.
Add a Data Mining Query task after the Foreach Loop to Update Status
Finally, you add one task to update the status of your mining models and save that information to the relational database for reporting. Obviously status will not be real-time, but our scenario assumes that you are going to processing the models infrequently, perhaps once a week or even daily, so this should suffice.
- Right-click the Data Mining Query task, and select Copy.
- Paste the task after the Foreach loop and connect it to the loop.
- Rename the task Update Processing Status.
- Open the Data Mining Query task Editor, click the Output tab, and verify that the option, Drop and re-create the output table is selected.
This completes the package. You can now execute the package and watch the models being processed. The actual processing of each model (or cube) could take a while, so you can add logging to the package to track the time used for processing each model.
Conclusion
This demo shows how easy it is to dynamically process Analysis Services objects using Integration Services variables in a Foreach Loop container.
For the full walkthrough, which also demonstrates how to dynamically build models using parameters stored in a SQL Server table, see the white paper on the Download Center.