Private Cloud Planning Guide for Systems Management
Infrastructure as a Service (IaaS) refers to an environment that offers dynamically scalable, virtualized computing power and storage resources as a service. This http://blogs.technet.com/cfs-file.ashx/__key/communityserver-blogs-components-weblogfiles/00-00-00-85-24-metablogapi/5658.image_5F00_64BCDD48.pngservice abstracts low-level hardware, such as servers and storage devices, reducing organizations’ investment in such equipment.
{kind=link}
Note:
This document is part of a collection of documents that comprise the Reference Architecture for Private Cloud document set. The Reference Architecture for Private Cloud documentation is a community collaboration project. Please feel free to edit this document to improve its quality. If you would like to be recognized for your work on improving this article, please include your name and any contact information you wish to share at the bottom of this page.
This article is no longer being updated by the Microsoft team that originally published it. It remains online for the community to update, if desired. Current documents from Microsoft that help you plan for cloud solutions with Microsoft products are found at the TechNet Library Solutions or Cloud and Datacenter Solutions pages.
The purpose of this document is to define how Private Cloud Infrastructure as a Service patterns affect Systems Management design.

This guide should be used as an aid to operations, architects, and consultants who are designing processes, procedures, and best practices for a private cloud. The reader should already be familiar with the Microsoft Operations Framework (MOF) and Information Technology Infrastructure Library (ITIL) models as well as the Private Cloud Principles, Concepts, and Patterns described in this documentation.
1 Private Cloud Systems Management Capabilities
The Private Cloud Reference Model is shown here with the Management Layer highlighted. Within the Management Layer are the nine Systems Management Capabilities a private cloud must provide to support Infrastructure as a Service; Service Reporting, Service Management System, Service Health Monitoring, Configuration Management System, Fabric Management, Deployment and Provisioning Management, Data Protection, Network Management, and Security Management.
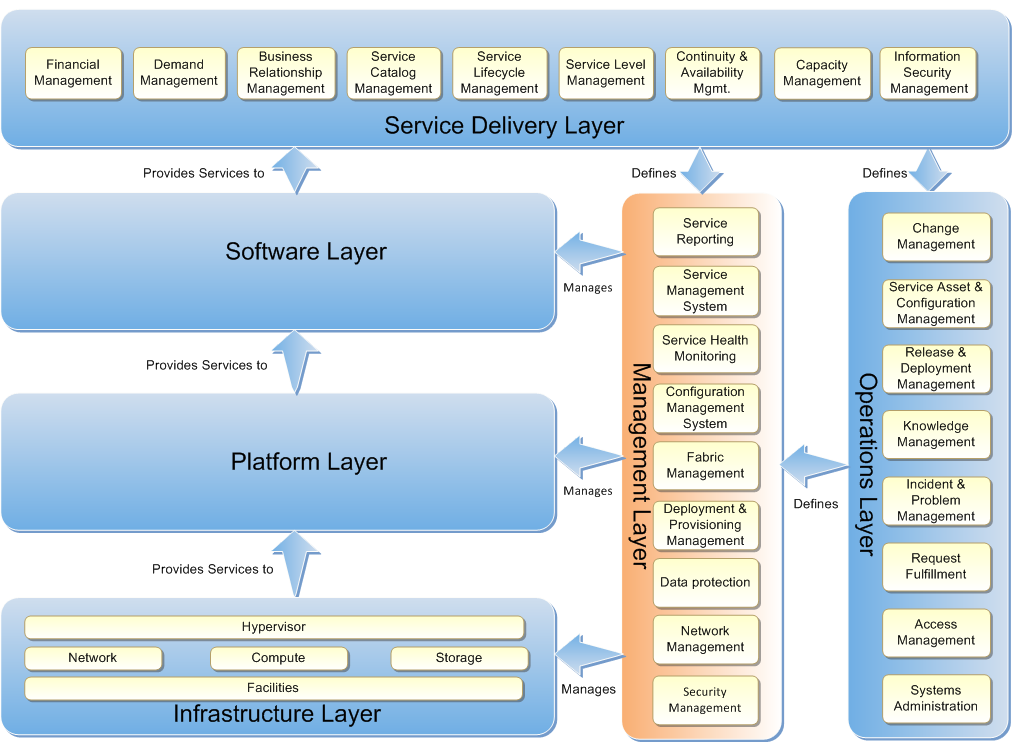
Figure 1: Private Cloud Reference Model
This document describes these nine Management Layer capabilities and the impact of private cloud IaaS patterns on their planning and design. The patterns are defined in the Private Cloud Principles, Concepts, and Patterns document and are summarized here:
- Resource Pooling: Divides resources into partitions for management purposes.
- Physical Fault Domain: The group of physical resources dependent on a single point of failure such as an uninterruptible power supply (UPS).
- Upgrade Domain: A group of resources upgraded as a single unit.
- Reserve Capacity: Unallocated resources, which take over service in the event of a failed Physical Fault Domain.
- Scale Unit: A collection of resources treated as a single unit of additional capacity.
- Capacity Plan: A model that enables a private cloud to deliver the perception of infinite capacity.
- Health Model: Defines how service or system may remain healthy.
- Service Class: Defines services that are delivered by IaaS.
- Cost Model: The financial breakdown of a private cloud infrastructure and its services.
1.1 Service Reporting
Service Reporting supports many domains in a private cloud, as it is the way information is delivered to IT and business. These domains must provide the raw data to Service Reporting.
1.1.1 Generic Requirements
Effective management of a private cloud is dependent on its Key Performance Indicators (KPIs). These general Service-Level Management reports are typically relevant:
- Availability of each Service Class
- Availability of each individual compute instance
This list omits other typical reporting requirements (for example, Service Desk response time and Change Request response time) that are not specific to a private cloud.
1.1.2 Resource Pooling
Resource Pools are logical collections of servers, network switches, and storage. The Service Delivery, Operations, and Infrastructure teams need reports in order to manage the life cycle of a Resource Pool. Here is a list of typical Systems Management activities where Resource Pool reporting is needed:
Capacity Management
- Allocation of Resource Pool capacity
- Utilization of Resource Pool capacity
- Creation of a Resource Pool
- Free Resource Pool capacity
- Resource Pool Reserve Capacity
Hardware
- Resource Decay
Configuration Management
- Patching status on a Resource Pool basis
- Software versions running in Resource Pools
To support these requirements, the Systems Management tools must understand Resource Pools and keep track of resources in each Resource Pool.
This list omits typical reports produced in mature Information Technology (IT) organization that are not specific to a private cloud; for example, audit reports for compliance or security.
1.1.3 Physical Fault Domain
The Systems Management tools must understand and represent Physical Fault Domains and keep track of resources that are hosted in a Fault Domain. The following reports will help in the management of Fault Domains:
- Physical Fault Domain resources
- Physical Fault Domain availability
- Running workloads
1.1.4 Upgrade Domain
The Systems Management tools must understand and represent Upgrade Domains and maintain a list of resources within an Upgrade Domain. The following reports will help in the management of Upgrade Domains:
- Relationship between the Physical Fault and the Upgrade Domains
- Resources in the Upgrade Domain
- Version of resources in the Upgrade Domain (targeting for patches)
- Scheduled maintenance window for each Upgrade Domain
- Consumers, Workloads, and machine instances affected by the Upgrade Domain (that is, the consumers, workloads, and machine instances that need migration for fabric maintenance)
1.1.5 Reserve Capacity
Reserve Capacity is likely to be relatively static in each Resource Pool, which means reporting is less critical for Reserve Capacity as compared to some of the other private cloud patterns. A report on Current Reserve Capacity per Resource Pool serves as a baseline.
1.1.6 Capacity Plan
The Capacity Plan is highly dependent on correct reporting. The following list of reports is a baseline and should be reviewed based on each customer’s approach to capacity planning:
- Allocation of capacity in total, and per Resource Pool
- Utilization of capacity in total, and per Resource Pool
- Free capacity in total, and per Resource Pool
- Reserve Capacity in total, and per Resource Pool
- Historic speed at which resources are consumed
- Projected point when additional Scale Units need to be ordered
- Scale Unit estimated lead time versus actual lead time per vendor
- Scale Unit reliability (hardware reliability rollup) by vendor
While these requirements could be satisfied through manual collection and manipulation of capacity data (for example, listing capacity and consumption in Microsoft Excel®), the manual approach increases the risk of running out of capacity, violating the Private Cloud principle of perceived unlimited capacity.
The Systems Management tools should ideally report capacity data in real time.
1.1.7 Health Model
The Health Dashboard information for the various consumers of Health Model should include the following:
CIO and Service Delivery
- Service-level reporting
- Overall current system health
- Current major incidents
- Scheduled maintenance
Service Delivery
- Service-level reporting
- Overall current system health
- Current major incidents
- Scheduled maintenance
- State of Resource Decay
- State of Physical Fault Domains
Operations
- Overall current system health
- Current incidents
- Health state of resources
- Outstanding tickets
User
- Current system health of all users’ systems
- Outstanding tickets for the user
1.1.8 Service Class
The Service Delivery team will want to understand how they can improve the services for the business. The following reports can help in this respect:
- Service Class Pivot (which classes are popular or unpopular)
- Number of machines per Service Class
- Percent of Resource Consumption by Service Class
- Resource Utilization (for example, CPU load) per Service Class
- Number of Incidents per Service Class
1.1.9 Cost Model
Reporting in a private cloud may be integral to any billing or cost allocation process. Reporting requirements may define information needed from the infrastructure; for example, information on tenant-based consumption of resources.
The architect must make sure any service reporting capability is multi-tenant aware from the perspectives of both content (reports on tenant consumption) and user (reporting must honor tenant separation).
1.2 Service Management System
The Service Management System should be capable of integrating data generated from the entire suite of tools found in the Management Layer. It should also be capable of processing and presenting this data as needed.
At a minimum, the Service Management System should be linked to the Configuration Management System (CMS), which consists of one or more Configuration Management Databases (CMDBs), and should be able to log and track incidents, problems, and changes. It is also preferred that the Service Management System be integrated with the Service Health Modeling system so incident tickets can be auto-generated as needed.
Compared to traditional infrastructure, a private cloud is highly automated, but this does not eliminate the need to raise a ticket against a change. Adding a machine in response to a load or moving a machine instance to another physical host are automated activities, yet a ticket must be created. The same applies to automated incident response: an incident ticket still needs to be logged.
The Service Reporting section above defined many Systems Management activities that need to be reported. All these activities also require automatic ticketing. Some important private cloud specific ticketing triggers are:
- Resource Decay threshold has been met or exceeded
- Reserve Capacity threshold has been met or exceeded
- Movement of a Virtual Machine between hosts
- Deployment of a new machine
- Removal or suspension of a Virtual Machine
- Failure of a Physical Fault Domain
- Activation of an Upgrade Domain (that is, removal of running services from the resource)
The Service Management System should understand the concept of Capacity Management and create a ticket when resources are depleted to the defined level. The ticket is used to indicate that the procurement process has been triggered.
The Service Management System should also track Resource Decay and trigger maintenance when the appropriate Resource Decay threshold is met. The Service Management System needs to raise a ticket when a Resource Decay threshold is met because it is now an incident. If maintenance occurs on a regular schedule instead of when a threshold is met, the Service Management System should create a ticket listing all maintenance work to be undertaken at the next scheduled window. Even when maintenance is regularly scheduled, the Service Management System still needs to raise a ticket when a resource decay threshold is met.
1.3 Heath Model and Health Monitoring
For resiliency, a private cloud must be able to automatically detect a hardware component failure or diminished capacity. This requires an understanding of all the hardware components that work together to deliver a Service, and the relationships between these components. Monitoring these relationships allows a private cloud to see which machines are affected by a hardware component failure; it allows the private cloud management system to determine if an automated response action is needed to prevent an outage or restore a failed instance on another system.
From a broader perspective, the management system needs to classify a failure as an incident, as Resource Decay, a Physical Fault Domain failure, or a broad failure that requires the system to trigger the disaster recovery response.
When creating the Health Model, it is important to consider the connections between systems. This includes connections to power, network, and storage. The Architect also needs to consider data access, for example, server connections to the correct logical unit number (LUN). Finally, the architect must understand how diminished performance may impact the system. For example, if the network is saturated, performance may be affected to the point that the management system moves workloads to new hosts. It is important to know how to determine both healthy and failed states in a predictable manner.
1.3.1 Physical Fault Domain
Physical Fault Domains play a significant role in the Health Model. The monitoring and management systems must understand Fault Domains and the resources that are hosted in each Fault Domain.
The next diagram shows a typical case of systems interconnections. In this case, power is a single point of failure as all servers are connected to one of two UPSs. Here each UPS represents a Physical Fault Domain as its failure leads to server failure. Network connections and Fiber Channel connections to the SAN are also Fault Domains, but these connections are redundant.
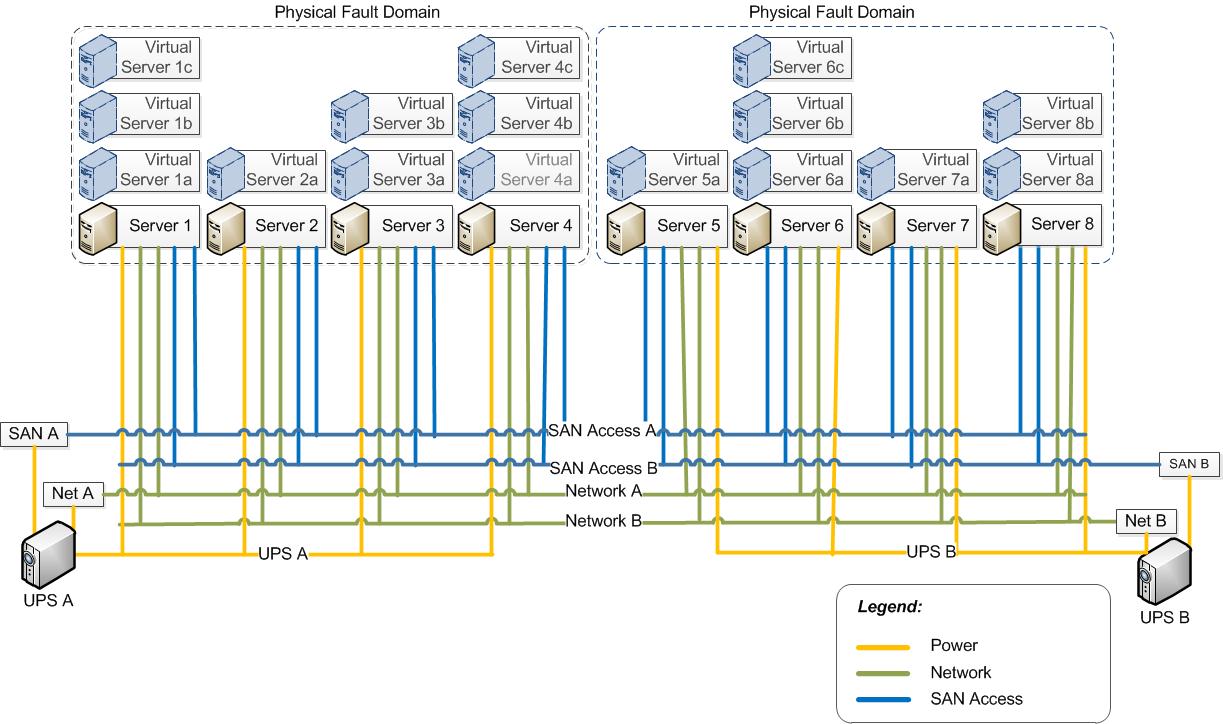
Figure 2: Connection Diagram with Physical Fault Domains
When “UPS A” fails, it causes a loss of power to Servers 1-4. It also causes a loss of power to “Network A” and “Fiber Channel A”, but because the network and Fiber Channel are redundant, only one Fault Domain fails. The others (UPS B, Network B, and FC B) are diminished, as they lose their redundancy.
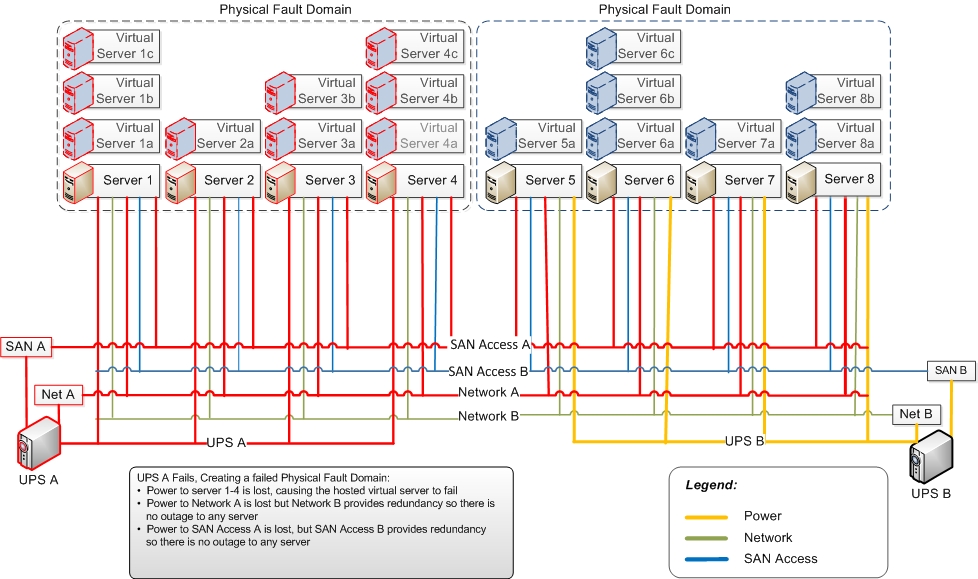
Figure 3: UPS A Fails Causing a Physical Fault Domain Failure
The management system needs to detect the Fault Domain failure (UPS failure in this example) and migrate or restart workloads on functioning Physical Fault Domains – Fault Domain UPS B.
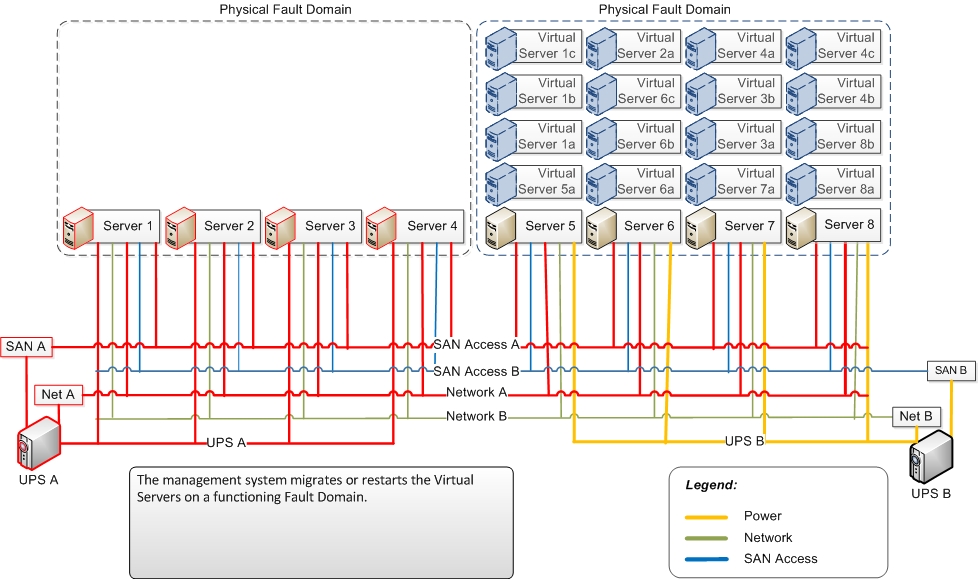
Figure 4: Management System Relocates Workloads around the Failure
The monitoring system must be able to tell when resources are being taken out of operation for an upgrade, so it can suppress alerts from the resources during the upgrade process. A private cloud achieves this by defining and placing resources in Upgrade Domains.
The Private Cloud Principles, Concepts, and Patterns document provides a method for calculating the level of Reserve Capacity in each Resource Pool. If this formula is adopted, there will always be sufficient capacity in a Resource Pool to handle all running machine instances. In theory, the health monitoring system shouldn't need to understand or trigger alerts on lowered Reserve Capacity. But architects and operations teams are likely to be uncomfortable with this. The monitoring system needs to trigger an incident when resources are overcommitted, Resource Decay exceeds the defined figure used in the formula, or more than one Fault Domain fails simultaneously. Therefore, it is recommended that the health monitoring system understand Reserve Capacity and issue alerts when it is nearly consumed.
1.3.2 Capacity Plan
The monitoring systems and Health Model aid capacity planning by recording resource consumption trends and alerting operators when capacity triggers are reached.
1.3.3 Health Model
A private cloud depends on three types of Health Model:
- Fabric Health Model: Defines the dependency tree (or Service Map) of resources that make up Fault Domains; defines the monitoring rules used to confirm the health of each resource. Failures will trigger Fabric Management to move or restart the machines. Some alerts may indicate a pending failure; in these instances, Fabric Management can proactively move the machines to avoid an outage.
- Service Class Health Model: Defines the health of a Service Class, which is a specification of machines running atop a private cloud fabric. This type of Health Model is concerned with the performance and availability of a class of machine; for example, have the machines in a class met their availability Service-Level Agreement (SLA)?
- Workload Health Model: Defined by the consumer, this health model consists of triggers that cause Fabric Management to add or remove machines from a workload. These triggers are defined in more detail in the Fabric Management section later in this document. This type of health model may not be implemented in all cases.
1.3.4 Service Class
From a health perspective, there are likely to be two categories of Service Classes: stateful and stateless. These two classes of service must be managed differently. For example, a stateless class of virtual machine could be restarted automatically on a different physical server in the Resource Pool should its host fail. A stateful class may provide clustering support to avoid outages during planned maintenance.
Understanding the long-term health and utilization of Service Classes helps Service Management improve service quality. A Health Model needs to be constructed for each Service Class. This enables Systems Management tools to measure the performance, availability, and utilization of each Service Class. The same Health Model supports the user views; however, the scope in this instance is limited to the users’ instances of that particular Service Class.
Fabric Management, detailed later in this document, uses the Service Class Health Model in conjunction with defined Resource Pools and Physical Fault Domains.
1.3.5 Cost Model
The Health Monitoring System contributes to the private cloud cost model in a number of ways:
- Keeping track of the resources allocated to each consumer to facilitate reporting or billing (or metering)
- Utilization reports showing abandoned resources
- Recording how physical resources are utilized, hardware failure rates, and more. Since these inputs to the Cost Model are not unique to a private cloud, common practice should be sufficient.
1.4 Configuration Management System
The principle of IT departments taking a “service provider” approach to delivering a private cloud suggests that the CMS and CMDB used for the infrastructure should be separate from the CMS and CMDB used by the consumers. But practical adoption of this approach depends on such factors as cost (manpower available to manage another CMS, plus software licensing and physical infrastructure costs) and portability (the ability to transfer capabilities to an external supplier).
The CMS will handle two broad categories of changes; those focused on the private cloud infrastructure and those focused on the private cloud service(s). It is likely there will be different people involved in these two types of changes; most infrastructure changes should be invisible to consumers, to support the principle of continuous availability, but service changes are likely to be in response to consumer requests. Common infrastructure and service changes are:
Infrastructure Change
- Addition of a Scale Unit
- Patching of software or firmware
- Resource failure
- Creation of a Physical Fault Domain
- Creation of a Resource Pool
Service Change
- Addition of a machine
- Movement of a machine
- Definition of a new Service Class
- Creation of a new Workload
Because of the high level of automation and the dynamic nature of a private cloud, its change rate is likely to be considerably higher than a traditional infrastructure. Much of the automation will depend on the CMDB; therefore the CMS as well as CMDB should be designed with these requirements in mind.
The CMS must handle the test-and-release management process for the private cloud infrastructure. Versioning is very important to the reliability of private cloud automation; a release should encompass the private cloud infrastructure and systems management functions such as the Fabric Management rules and automation scripts.
Some changes can be rolled across the private cloud infrastructure incrementally; for example, patches and firmware updates. Significant upgrades such as operating system version changes should be done as a version release where thorough testing of the systems management functions (Fabric Management and automation scripts) can occur. Many standard changes will be automated and the CMS should track these changes.
The CMS needs to have Configuration Items (CIs) for patterns such as Resource Pools, Fault Domains, Upgrade Domains, Service Classes, workloads, and consumer or tenant (owner).
The Resource Pool, Fault Domain, and Upgrade Domain CIs will contain physical hosts, VMs, switches, and storage CIs.
The Upgrade Domain pattern will be used extensively by the CMS. The forward schedule of change can use Upgrade Domains as the scope of change. The definition of Upgrade Domains will vary depending on the resource and the infrastructure design. But Upgrade Domains should observe these basic rules:
- Should be small enough not to threaten service delivery. For compute, this means a subset of a Resource Pool. Refer to Private Cloud Principles, Concepts, and Patterns document that defines the relationship between Resource Pools, Reserve Capacity, Resource Decay, and Upgrade Domain.
- Should contain resources common to the change or upgrade being applied. For example, an Upgrade Domain should contain identical physical hosts that receive the same firmware updates.
- Define separate Upgrade Domains for compute, network, and storage resource types.
The Upgrade Domains should be defined jointly by the infrastructure specialist (for example, network manager) and the service manager to make sure an appropriate balance among size, risk, and change window.
1.5 Fabric Management
In traditional IT, servers, network, and storage are managed separately, often on a project-by-project basis. In dynamic IT, and private cloud system management, these resources can be thought of as the fabric upon which compute instances run. They therefore need to be managed as a unit. In the same way that virtualization abstracts physical hardware, Fabric Management abstracts a service from specific hypervisors and network switches.
Fabric Management can be thought of as an “orchestration engine” responsible for:
- Managing the life cycle of a consumer’s workload
- Responding to Operations requests, systems management events, and service-level policies.
The term “orchestration” is fitting because Fabric Management may use other Systems Management tools and scripts to execute changes initiated by Fabric Management.
A traditional virtualized infrastructure focuses on individual VMs, whereas a private cloud focuses on groups of VMs that collectively make up a solution. Take Microsoft Exchange, for example. The private cloud groups the VMs that collectively provide Exchange (Client Access Server, Hub, and Mailbox) into a workload. Workloads have configurable attributes, among them a scale-up attribute that defines when Fabric Management should automatically add additional VMs to the workload.
Fabric Management has two primary activities:
- Determine the Resource Pool and physical host to deploy or move a VM.
- Add VMs based on workload policies.
The VM placement process would be simple if it was simply based on the available capacity. However, Fabric Management also uses Service Classes (defined in Private Cloud Planning Guide for Service Delivery document) to determine VM placement. Service classifications define when VMs must be deployed into separate Physical Fault Domains. The combination of defining workloads and service classification enables solutions to be deployed in a resilient fashion. For example, a workload could contain two Exchange CAS servers that use a service classification that forces deployment of each VM into separate Physical Fault Domains.
In a traditional infrastructure, this process is handled manually. Fabric Management does it automatically in a private cloud, and ensures that separation is maintained even after the failure of a Physical Fault Domain. Existing VM management tools do not provide this level of intelligence and are therefore unable to manage VM placement or movement in a private cloud.
To determine VM placement, Fabric Management must keep track of available resources, their quantity, and the quantity of resource allocated to Reserve Capacity. Policies should define if Fabric Management can exceed the Reserve Capacity threshold on a Resource Pool.
Taking this holistic view of the infrastructure, Fabric Management can respond to the failure of a Physical Fault Domain or an individual server by automatically moving or restarting VMs on working Fault Domains or servers. Note that a movement will trigger the decision-making process to determine where a VM can be placed based on the workload and service classification.
To be able to move VMs around and still deliver a consistent service to consumers, Fabric Management depends upon pools of resources. Ideally, every server in a Resource Pool is identical, so any VM can be hosted on any server in the pool and perform the same way. Fabric Management must understand the concept of Upgrade Domains, so it can move VMs off hosts when an Upgrade Domain is activated.
It should be obvious that Fabric Management is highly dependent on the Fabric Health Model. The richer the health information provided by monitoring systems, the greater the effectiveness of Fabric Management. For example, if systems monitoring detects impending failures, Fabric Management can proactively move affected VMs to avoid an outage.
Fabric Management is also responsible for the dynamic scaling of workloads. Attributes defined in Service Classification or Workload Configuration are used to determine when to add or remove Scale and by how much. Triggers can be based on load or time; for example, increase scale whenever CPU exceeds a certain threshold, or at 2100 Coordinated Universal Time (UTC) every Friday. This capability allows a private cloud to respond to business needs rapidly or on a schedule, allocating more resources to compute-intensive workloads when needed.
The architect must determine if and how to support dynamic scaling, because the choice impacts systems monitoring, service classification, and Fabric Management.
Upgrades in a traditional infrastructure are largely manual. The resources to be upgraded are identified and taken out of service before an upgrade is implemented. Fabric Management orchestrates this process by understanding what physical resources are allocated to an Upgrade Domain.
A homogenized fabric enables one set of scripts to be used on all resources of the same type and avoids the need for complex calculations and dependence on hypervisor configuration to determine how much CPU is allocated to individual VMs. Over the life, however, it is perhaps unrealistic to assume that the fabric will remain homogenous. The architect must consider this when designing Fabric Management and the lower-level Systems Management automation. One solution is to partition a private cloud into Resource Pools, each of which has a homogenous fabric.
1.6 Deployment and Provisioning Management
Deployment and Provisioning Management is the toolset used to carry out the processes defined by Release and Deployment Management in the Operations Layer.
Deployment and Provisioning Management is responsible for bare metal deployment of the hypervisor and the provisioning of VMs with service-specific, instance-specific, workload-specific configuration. It is also responsible for deployment of patches and system updates to the fabric.
Deployment can be deployed as the installation and configuration of the software which makes up the fabric, and provisioning as the creation of VMs and making the necessary configuration changes to the fabric for these new VMs to function. As stated earlier, Fabric Management initiates and orchestrates these fabric changes; the provisioning activities are relatively simple and straightforward: create, move, start, or stop a VM, create a virtual IP in a load balancer, add or remove hosts from load-balanced farm, and add or expand a LUN. Most provisioning activities will be orchestrated by Fabric Management.
All these activities must be mechanized (scripted), otherwise a private cloud will not be able to scale or meet future agility needs.
Because the provisioning tools are called by Fabric Management, they do not need to know Resource Pools, Upgrade Domains, or Physical Fault Domains. The deployment tools must understand both Resource Pools and Physical Fault Domains to be able to identify which Resource Pool and Physical Fault Domain the server is being deployed into. Consequently, the deployment and provisioning process must be integrated with the CMDB (though not necessarily the tools; they can simply execute instructions issued by Fabric Management).
Deployment and Provisioning Management tools must be integrated with the Health Model because any deployment or provisioning failure must be exposed to the health monitoring tools.
The provisioning process (not necessarily the tools) must understand each Service Class, as this information defines the VM configuration.
1.7 Data Protection
Data Protection provides the capability to backup and restore data, hosts, infrastructure, and service components. As a private cloud considers machines to be black boxes, the architect has a choice to make the consumer responsible for backup or provide Data Protection capability as part of the Service Classification.
For the purposes of this document, it is assumed that a private cloud will not provide a backup of machines as this capability is tightly coupled with workloads. This section defines Data Protection for the private cloud itself. Private cloud is highly dependent on its systems management functions; therefore, these functions should be highly available to make sure that a failure doesn’t cause the private cloud itself to fail. Consequently, Data Protection as defined here is designed to protect against a disaster, rather than provide a snapshot of the private cloud at a point in time.
The fabric in a virtualized environment, that is, the hosts running the hypervisor or parent partition, should not need Data Protection as they don't host data and can be rebuilt automatically through bare metal deployment.
Data Protection for a private cloud focuses on fabric configuration and systems management functions, all of which need protection. The particular method for backing up these management functions will be defined by the management tools vendor; however, a good principle is to back up the primary instance of each management server and its corresponding database. These backups should be kept offsite to enable recovery to a different facility.
Network switch configuration and storage array configuration both need protection through their respective management software, again utilizing offsite storage.
The data protection infrastructure, like any backup infrastructure, needs to be monitored to make sure it is healthy.
1.8 Network Management
The private cloud depends on network switches, a virtual local area network (VLAN), and, optionally, load balancers to deliver a service. Management of these resources must be integrated with the private cloud in such a way that “business as usual” changes are mechanized, allowing Fabric Management to make automated infrastructure changes.
Each switch should be allocated to a Resource Pool along with compute resources. When defining Service Classes, the architect must decide whether separate VLANs are defined for each consumer and workload. This decision also impacts whether VLANs exist globally in all switches, or are deployed only to the switch which hosts the consumer or the workload.
When defining Service Classes, the architect may choose to create a category of service based on a network characteristic such as high throughput. In such a case, the architect could choose a lower machine density per switch, or create one or more dedicated Resource Pools with high-speed network interconnects. High-end network switches and network adaptors must be factored into the Service Class Cost Model.
The Upgrade Domain pattern applies to network hardware. Switches and load balancers need patching and operating system upgrades. The network should be fully redundant; therefore, network upgrades could be accomplished by placing one switch from each redundant pair into an Upgrade Domain. For example, switch Upgrade Domain A may contain all (or a subset of) primary network switches while Upgrade Domain B contains all (or a subset of) secondary switches.
Network capacity planning is concerned with physical capacity (ports) and logical capacity (throughput, number of VLANs supported, and spanning tree support). Physical capacity is planned through Scale Units. Defining the number of servers and corresponding network ports in each Scale Unit makes it easy to plan the physical capacity of the physical network. Logical capacity can also be defined as a part of the Scale Unit. However, network management tools should monitor switch utilization and trigger some health alert if a machine or machines saturate the switch. Further, the switches or the Network Management tools should display health information as part of the overall Health Model.
1.9 Security Management
Security Management provides the capabilities needed to make sure both the private cloud infrastructure and the services it provides are secure.
In addition to many of the standard security requirements such as authentication, access control, monitoring, and reporting, a private cloud introduces the following new requirements:
Multi-tenancy: This may demand that each tenant is separated. Such a requirement drives the security design; for example, are VLANs and VMs sufficient or is physical separation needed?
Private cloud could provide services which are differentiated by their security design, for example, shared (multi-tenant) or dedicated infrastructure. Each of these will result in separate service classifications and are likely to be implemented as separate Resource Pools.
Compliance in a Dynamic Infrastructure: Compliance is a challenging area because it lacks prescriptive guidance. For example, one auditor may be happy with designs that show virtual separation between tenants or workloads, whereas others demand physical separation. The Private Cloud Systems Management design faces similar issues. Separation of the Private Cloud Systems Management from that of the workload means there is no information spillage; however, an auditor may not accept this.
Most auditors are likely to want VM movements logged so they can see on which physical host a VM was resident at any point in time. Further, they may want to see what other VMs were sharing the host.
The security requirements facing the business should be considered early in the design. Security requirements, if they drive physical separation, have the potential to compromise some private cloud concepts of optimized resource usage. A private cloud is designed to provide a limited set of standard services and security should influence but not drive the design of these services. Applications which have strict or unique security requirements are better implemented on a traditional infrastructure.
ACKNOWLEDGEMENTS LIST:
If you edit this page and would like acknowledgement of your participation in the v1 version of this document set, please include your name below:
*[Enter your name here and include any contact information you would like to share]
*