SQL-Server- C# Find duplicate record with identity

Introduction

New Solutions (application) with a database setup for the solution involving data are commonly read and written to outside of the solution. When these databases are not properly setup with constraints at the database level and with proper constraints in the solution there can be the possibility of duplicate records generated. New solutions (applications) written to read and write from existing databases that have not been setup with constraints and perhaps older solutions without proper constraints may have duplicate records.
A database without a solution is not immune from having duplicate records.
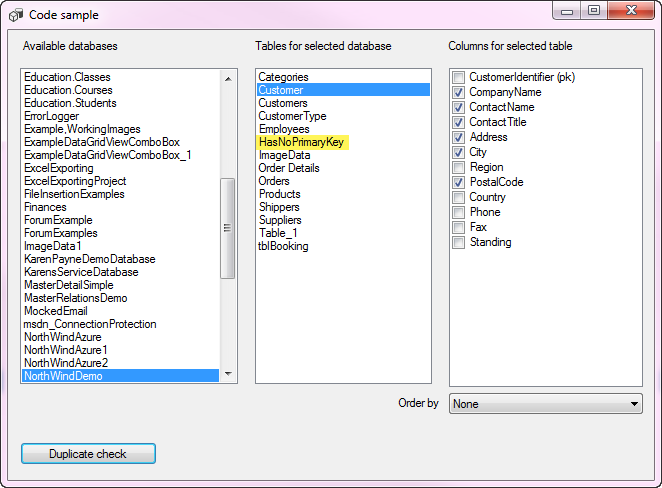
This article will provide a user interface which displays a databases, their tables and columns for the tables in a specific database were the user can select a table, check off columns to determine if there are duplicate records that provide the primary key (all tables should have a primary key) so that a DELETE FROM statement can be generated to removed records. The user is presented with duplicate records in a DataGridView with a DataGridViewCheckBox column. Check one or more records, press a button and a SELECT FROM statement is generated.
The reason for presenting records is because there may be one or more columns that may be different between the duplicate records. For example, a customer table is checked to see if the following columns are duplicates.
CompanyName, ContactName , ContactTitle , Address , City , PostalCode
And you want to see if a field name Country or Standings is different between the duplicates. Here it would be wise to have a modified date column to which when comparing records the must currently added or updated record is known when sorting on the modify date. Additionally, a user name (LastModifiedBy) column may assist with figuring out which record needs to be removed. Another possibility is two or more records need to be merged. A developer can expand on the base code to provide this functionality which is not included here as it moves passed the core concept of learning how to display duplicate records with the primary key.
Breaking down the code
There is a class project, UtilityLibrary which contains several concrete classes and a string language extension method which are used in other projects in the solution and can be used in other projects outside of this solution.
The class project SQL_Library contains all database operations to obtain databases in a SQL-Server, table names and column names in the tables.
In the class SqlDatabases, in the constructor, there is an assertion to check if the server and catalog are not set to the author’s computer and if so will throw a runtime exception which means you need to place your server name and catalog. This could be done dynamically using SMO (SQL-Server Objects) classes.
Special note: SMO is capable of performing all operations in this class project but is dependent on the version of SQL-Server installed. If this class referenced SMO version 12 and on your machine version 14 was installed the project would fail to build as the references are in a different location plus one of the references is handled differently between version 12 and version 14. This is why SMO is not used in this code sample.
DuplicateRecordsProject project is responsible for generating the SQL statement to show duplicate records. Since the SQL is fairly complicated a builder pattern was used to build the SELECT statement is parts.
Testing
To test the code presented, either use the “Customer” table included within the script (which has several duplicate records, see figure 1) or create your own table with a primary key and duplicate records.
In the customer table from the included script, each of the customer records shown below are duplicates, there is also one other record for each. Consider the following done by accident or perhaps bad coding or no constraints. The field/column Standing is different so the task to determine which to remove and which ones not to remove gets us to the point of; business may need to intervene which means having a utility to show the records is one option or another option is to export the results (that the utility created) to Microsoft Excel or CSV file which is easy enough to do (see the following TechNet article).
Figure 1

Run the utility, select the table, select the columns representing a duplicate and press “Duplicate check” button.
Builder Pattern
*The Builder Pattern is a common software design pattern that's used to encapsulate the construction logic for an object. This pattern is often used when the construction process of an object is complex. It's also well suited for constructing multiple representations of the same class. [VisualStudio Magazine]
*
Core Concepts
The Builder Pattern is comprised of four components: a builder interface, a concrete builder, a director and a product. The builder interface defines a template for the steps to construct the product. The concrete builder implements the builder interface and provides an interface for getting the product. The director actually constructs the object through the builder interface. The product is the end object that's constructed. [VisualStudio Magazine]
First there is a class which defines the builder parts
namespace DuplicateRecordsProject.Classes
{
/// <summary>
/// This class defines methods for constructing a sql statement
/// for locating duplicate records in a SQL-Server table.
/// </summary>
public abstract class SqlDuplicateBuilder
{
public abstract void CreateA();
public abstract void CreateSelectPart();
public abstract void CreateGroupPart();
public abstract void CreateHavingPart();
public abstract void CreateB();
public abstract void OrderBy();
public abstract DuplicateStatement GetResult();
}
}
The above class is implemented as follows
public class DuplicateDirector
{
public void Construct(SqlDuplicateBuilder builder)
{
builder.CreateA();
builder.CreateSelectPart();
builder.CreateGroupPart();
builder.CreateHavingPart();
builder.CreateB();
builder.OrderBy();
}
}
Which is called from a manager class which is invoked from a calling form which takes the selected table and columns to generate the SQL statement for duplicate records. An important note is if the primary key is selected there is logic to remove the identity column from the column list but used for presentation.
public class DuplicateManager
{
public string Statement { get; }
public DuplicateManager(DuplicateItemContainer container)
{
var director = new DuplicateDirector();
SqlDuplicateBuilder builder = new ConcreteSqlDuplicateBuilder(container);
director.Construct(builder);
DuplicateStatement duplicateStatement = builder.GetResult();
duplicateStatement.FinishedStatement();
Statement = duplicateStatement.Statement;
}
}
The following class is responsible for taking columns and building the SQL statement.
using System.Collections.Generic;
using System.Linq;
using UtilityLibrary;
namespace DuplicateRecordsProject.Classes
{
public class ConcreteSqlDuplicateBuilder : SqlDuplicateBuilder
{
private readonly DuplicateStatement _item = new DuplicateStatement();
private readonly List<SqlColumn> _sqlColumnList;
private string _tableName;
private string _orderBy;
public ConcreteSqlDuplicateBuilder(DuplicateItemContainer pColumnsInformation)
{
_sqlColumnList = pColumnsInformation.Columns;
_tableName = _sqlColumnList.First().TableName;
_orderBy = pColumnsInformation.OrderBy;
}
public override void CreateA()
{
_item.Add($"SELECT A.* FROM {_tableName} A INNER JOIN (SELECT ");
}
public override void CreateSelectPart()
{
_item.Add(string.Join(",", _sqlColumnList.Select(col => col.ColumnName).ToArray()) +
$" FROM {_tableName} ");
}
public override void CreateGroupPart()
{
_item.Add("GROUP BY " + string.Join(",", _sqlColumnList.Select(col => col.ColumnName).ToArray()) + " ");
}
public override void CreateHavingPart()
{
_item.Add("HAVING COUNT(*) > 1");
}
public override void CreateB()
{
var joined = _sqlColumnList.Select(item => $"A.{item.ColumnName} = " +
"B.{item.ColumnName}")
.ToArray()
.JoinCondition();
_item.Add(") B ON " + joined);
}
public override void OrderBy()
{
if (!string.IsNullOrWhiteSpace(_orderBy))
{
if (_orderBy != "None")
{
_item.Add($" ORDER BY {_orderBy}");
}
}
}
public override DuplicateStatement GetResult()
{
return _item;
}
}
}
The following code collects (in the calling form) columns to generate the SQL statement with a few assertions and checks. If there are no duplicates the operator is indicated there are no duplicates, otherwise, a secondary modal form is presented with the duplicate records. In the image above, note the table highlighted, this table has no primary key so selecting this table (which is included in the database script included in SQL_Library project you can see the code handles this.
The modal form will generate a string representation of a DELETE FROM SQL statement.
private void cmdCheckForDuplicates_Click(object sender, EventArgs e)
{
if (clbColumns.Items.Count == 0) return;
var allColumns = clbColumns.Items.OfType<SqlColumn>();
var identityColumn = allColumns.FirstOrDefault(col => col.IsIdentity);
var sqlColumns = clbColumns.CheckedIColumnDetailsList();
if (sqlColumns.Count >0)
{
if (identityColumn != null)
{
var test = sqlColumns.Contains(identityColumn);
if (test)
{
sqlColumns.Remove(identityColumn);
}
}
}
var container = new DuplicateItemContainer()
{
Columns = sqlColumns,
OrderBy = cboOrderBy.SelectedIndex == 0 ? "" : cboOrderBy.Text
};
var manager = new DuplicateManager(container);
// ReSharper disable once PossibleMultipleEnumeration
var ops = new DataOperations(allColumns.First().Schema);
var dt = ops.Duplicates(manager.Statement);
if (!ops.IsSuccessFul)
{
MessageBox.Show("Failure");
return;
}
if (dt.Rows.Count == 0)
{
MessageBox.Show("There are no duplicates in the selected table");
return;
}
if (identityColumn != null)
{
var f = new ResultsForm(lstTableNames.Text, dt, identityColumn.ColumnName);
try
{
f.ShowDialog();
}
finally
{
f.Dispose();
}
}
else
{
MessageBox.Show("No identity column, can not continue");
}
}
Important notes
When working with tables that don’t have a primary key the code presented will not work “as is” as the idea is to present duplicate records with a pointer back to the current table which permits deletion or editing.
If the selected table has relationships to other tables and has data which points back to a record in the list of records presented, a DELETE operation will fail on the foreign key constraint. This means for these records you will need to handle the related table data.
Alternates
The following might be fine for some which will get duplicates excluding one per group e.g. if there were four records for a customer it will report three. Convert this to a DELETE and one of the four will remain. The problem is which one should stay out of the four.
SELECT *
FROM dbo.Customer
WHERE CustomerIdentifier NOT IN ( SELECT MIN(CustomerIdentifier)
FROM dbo.Customer
GROUP BY CompanyName ,
ContactName ,
ContactTitle ,
Address ,
City ,
PostalCode );
While the statement produced by the code in this article presents all four records allowing an operator to select which records to remove along with possibly merging data together from the four.
SELECT A.* FROM Customer A
INNER JOIN ( SELECT CompanyName ,
ContactName ,
ContactTitle ,
Address ,
City ,
PostalCode
FROM Customer
GROUP BY CompanyName ,
ContactName ,
ContactTitle ,
Address ,
City ,
PostalCode
HAVING COUNT(*) > 1
) B ON A.CompanyName = B.CompanyName
AND A.ContactName = B.ContactName
AND A.ContactTitle = B.ContactTitle
AND A.Address = B.Address
AND A.City = B.City
AND A.PostalCode = B.PostalCode
See also
T-SQL: Remove Duplicate Rows From A Table Using Query Without Common Table Expression
.NET: Defensive data programming (Part 2)
How to Remove Duplicates from a Table in SQL Server
Summary
This article has provided a utility with full source code on GitHub to find records in a table with the primary/identity field to present duplicate records in a SQL-Server database. Although the article has focused on SQL-Server this is possible in MS-Access also as in the following MSDN code sample.
Other resources
MSDN Find duplicate records via SQL or LINQ in database table
StackOverflow thread Finding duplicate values in a SQL table
Source code
GitHub including database scripts
08/03/2019 source code updated