Power App: Build Document Digitization using Text Recognizer AI Model
Introduction
AI Builder is a Power Platform capability that provides you the AI models to take leverage of artificial intelligence to optimize your business as well as automate process. We can either use the already existing prebuilt models that suits our needs to use the Power of AI in Power Apps or Power Automate or create our own custom AI models to suit some specific business needs. You can read more about AI Models in the Official documentation here. The out of the box prebuilt available models in AI Builder are:
- Business card reader
- Category classification
- Entity extraction
- ID reader
- Invoice Processing
- Key phrase extraction
- Language detection
- Receipt processing
- Sentiment analysis
- Text recognition
- Text translation
In earlier days if we wanted to use any of these models, we had to call Power Automate and add the AI Builder actions to leverage the Cognitive abilities. However, more and more AI Builder capabilities are coming natively to Power App so that we can add them as controls to the App and directly interact with the AI Models based on our needs.
In this article we will see how we can make use of the Text Recognizer within Power App without the use of Power Automate
Scenario
We have a requirement where we need to automate the archival of old back-office documents by extracting the document content and storing it in a back end so that they become available for Content Search within the system. For this requirement we will create a Power App to accept the needed manual records inputs and use the Text Recognizer to automatically extract the scanned document contents and save it in a SharePoint List.
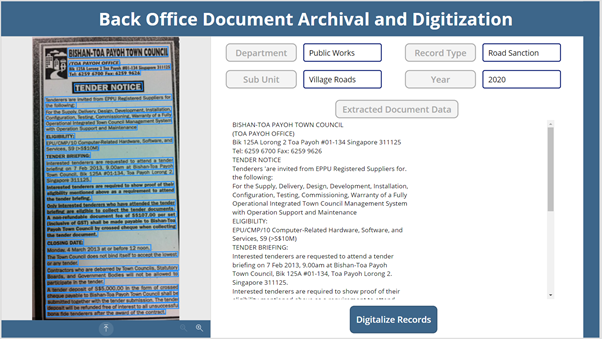
Implementation
So as to implement this requirement, we will create a SharePoint List named back Office Archival with Text columns (Department, Sub Unit, Record Type and Year) and Multi Line Rich Text Column(Extracted Document Data)
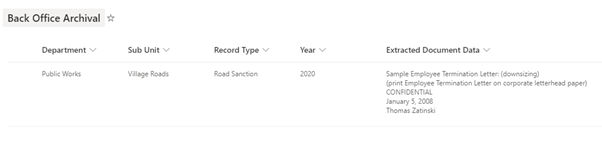
Let’s now head over to make.powerapps.com where we will create a Canvas app and add the below controls
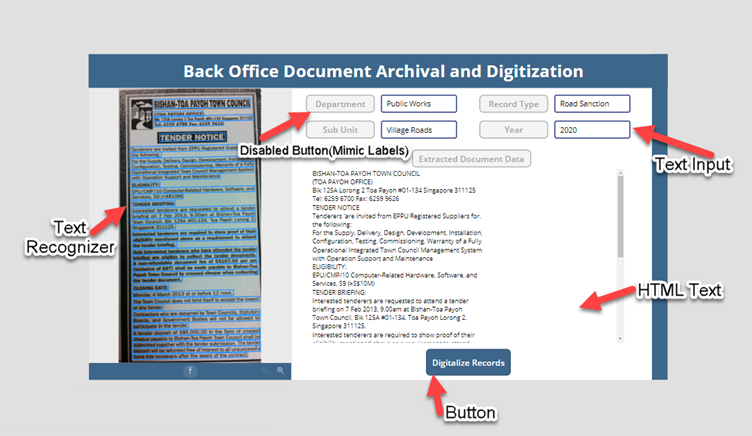
Here, Text Recognizer and HTML Text forms the main core controls that helps us do the Cognitive Data Extraction and Storage of extracted data respectively.
Data Extraction
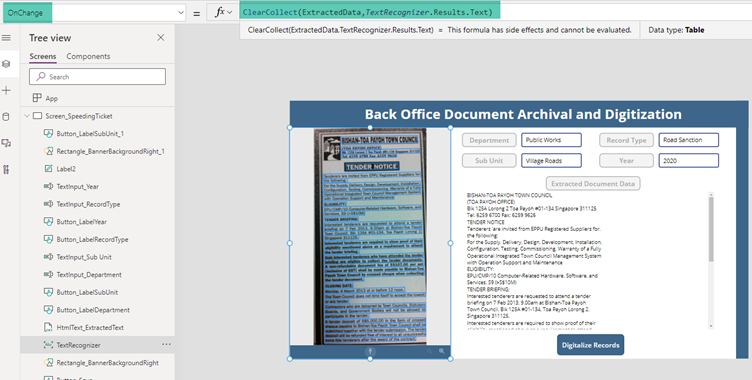
As part of implementing the data extraction, we will add the below expression to the OnChange of the Text Recognizer control so that whenever a new document scanned copy is uploaded to the control, it analyses the text and the returned results from the <ControlName>.Results.Text property is copied to a Collection using the ClearCollect method
ClearCollect(ExtractedData,TextRecognizer.Results.Text)
Now that the extracted data is present in the Collection, lets have a look at how the data is present in it from View->Collections
We can see that the data is extracted line by line and stored as records in the table.
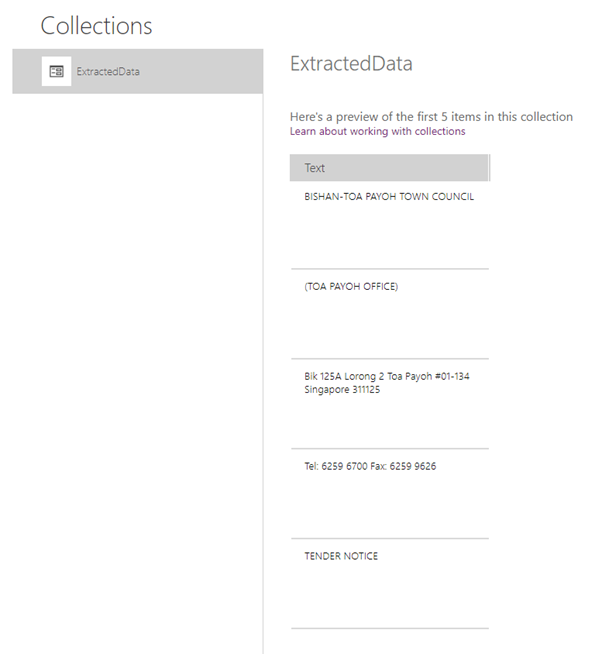
So as to combine them as a single paragraph, we will use the Concat function and use the Line break to make it a full formatted HTML text that will go into the HTML control.We will add the below expression to the HTMLText property of the HTML text control
Concat(ExtractedData,Text,"<br/>")
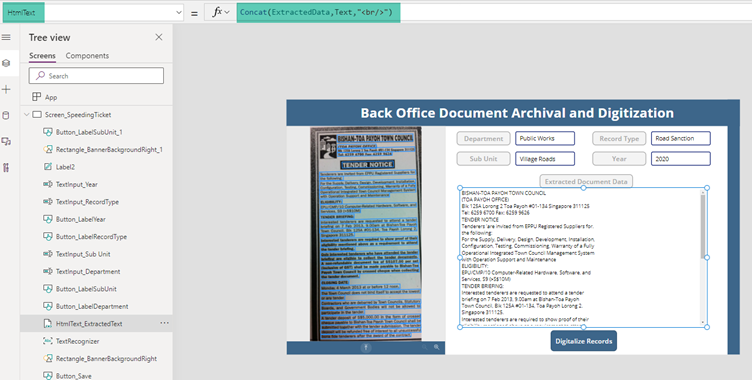
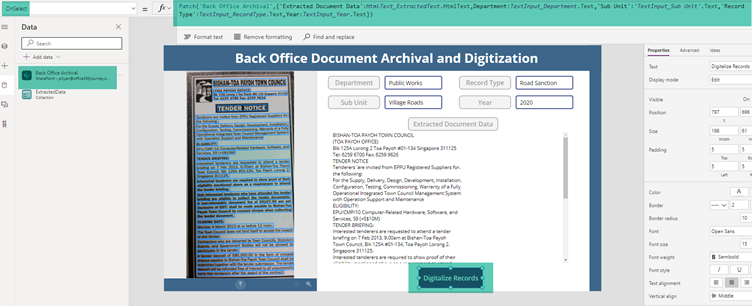
We have already created a Data Connection to the SharePoint List. Finally lets save the Manually entered data in the top Text input controls as well the HTML Text Control to the SharePoint back end using the Patch method with the below expression
Patch('Back Office Archival',{'Extracted Document Data':HtmlText_ExtractedText.HtmlText,Department:TextInput_Department.Text,'Sub Unit':'TextInput_Sub Unit'.Text,'Record Type':TextInput_RecordType.Text,Year:TextInput_Year.Text})
Test the App
Now let’s test the app by uploading a Document and see the Text Recognizer in action.
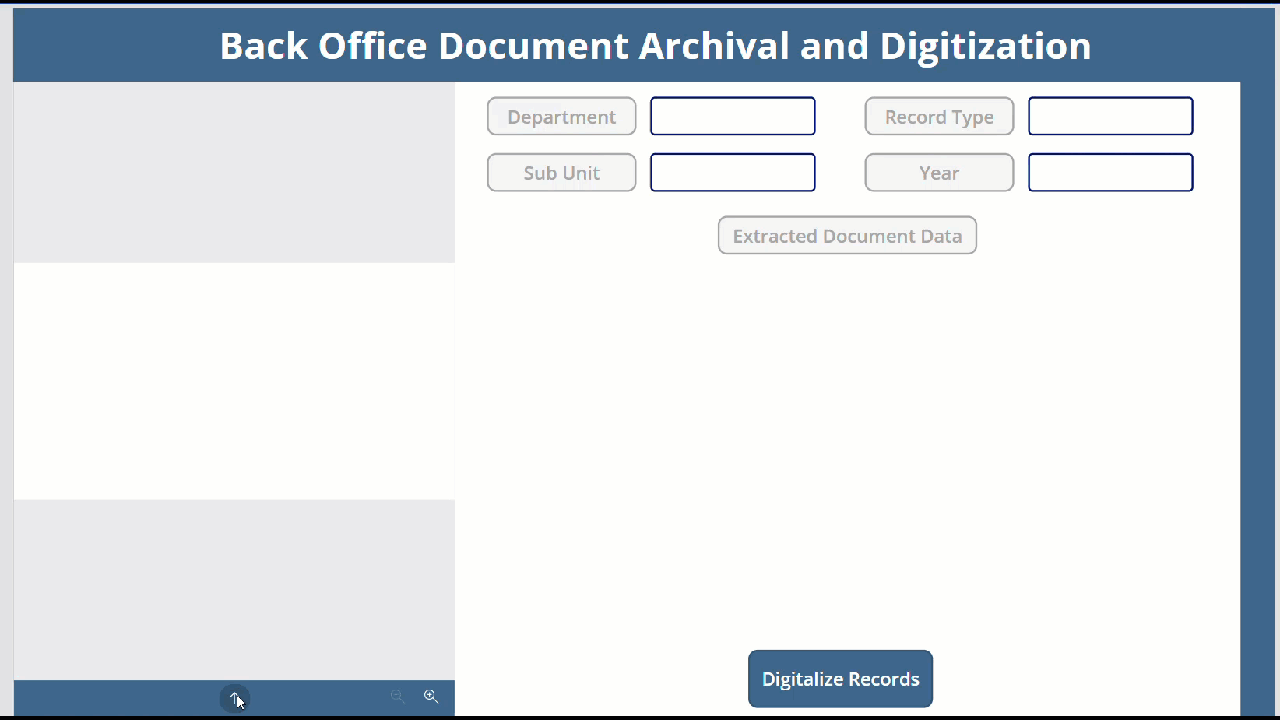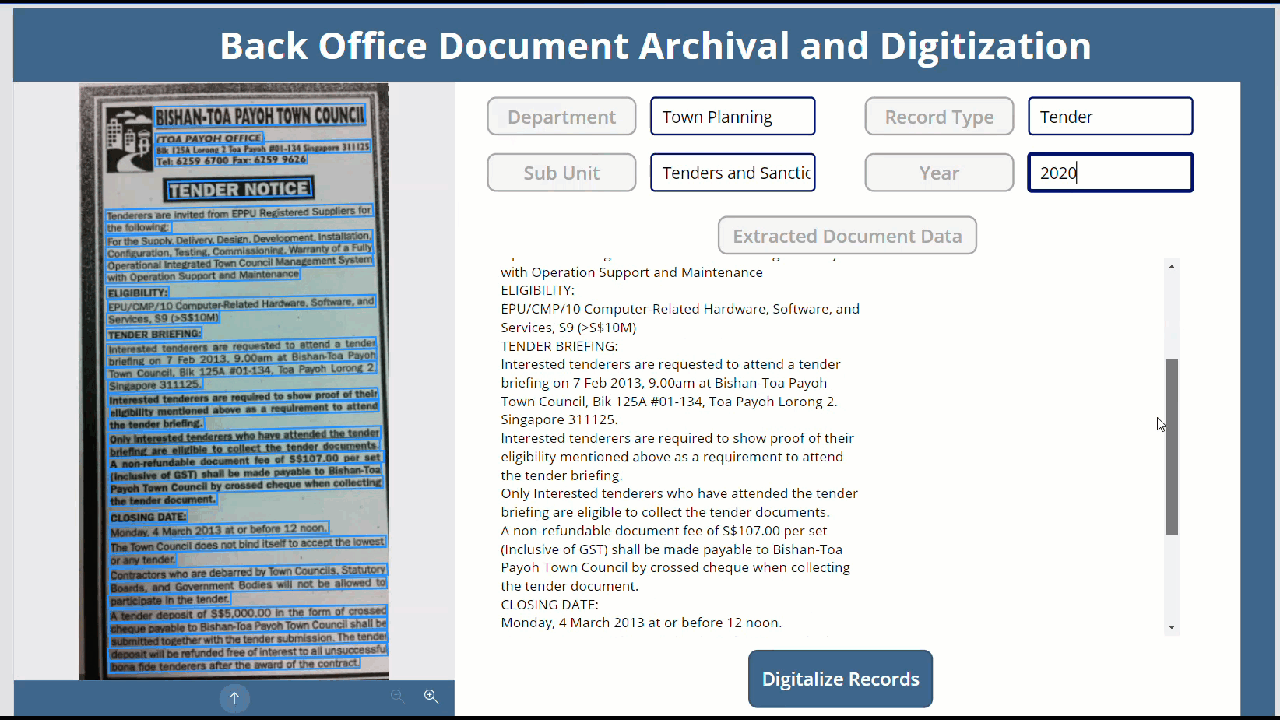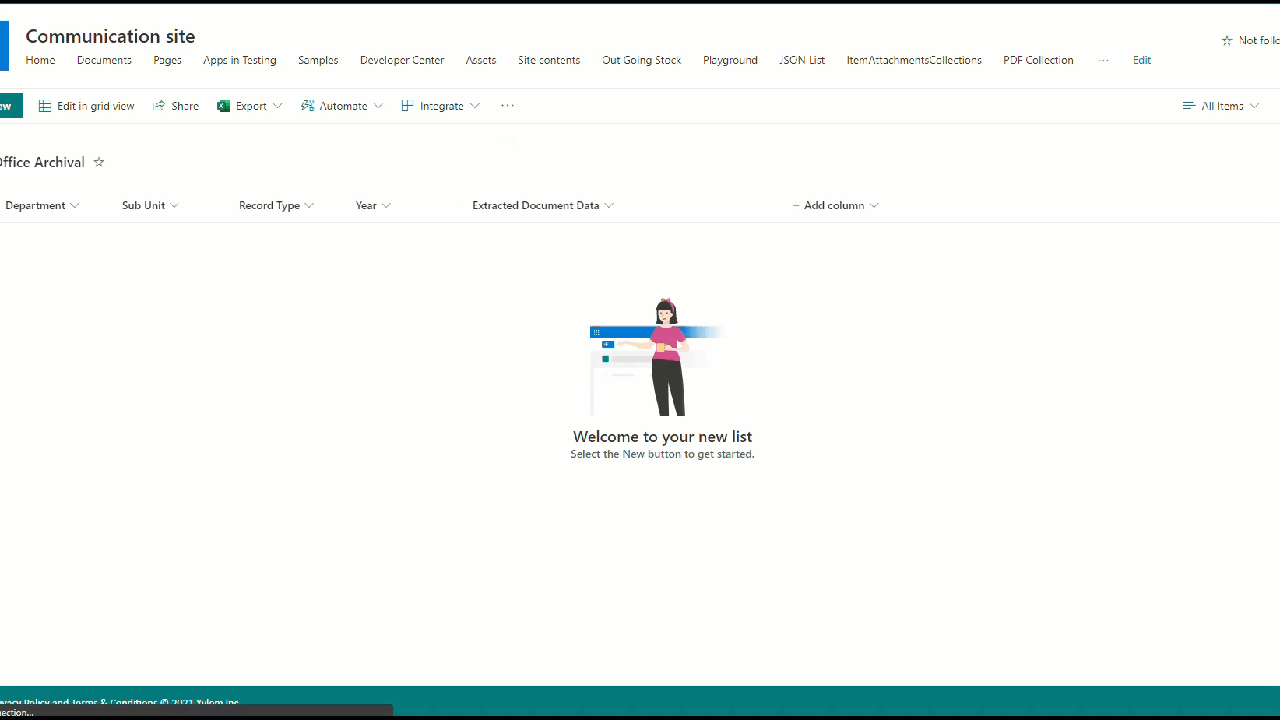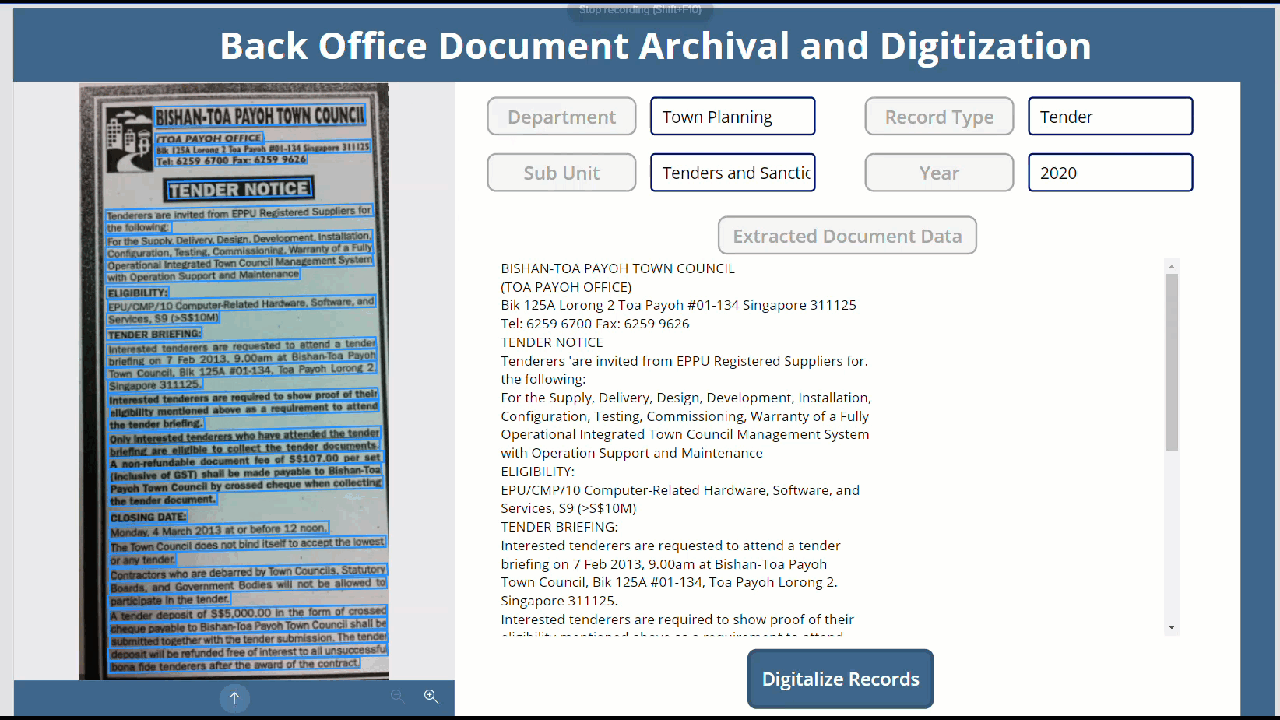
As we can see it has extracted the data and concatenated it into an HTML text which is fed into the HTLML Text control and eventually we have successfully saved it to the SharePoint List as well.