Natural language processing (NLP) has many uses: sentiment analysis, topic detection, language detection, key phrase extraction, and document categorization.
Specifically, you can use NLP to:
- Classify documents. For instance, you can label documents as sensitive or spam.
- Do subsequent processing or searches. You can use NLP output for these purposes.
- Summarize text by identifying the entities that are present in the document.
- Tag documents with keywords. For the keywords, NLP can use identified entities.
- Do content-based search and retrieval. Tagging makes this functionality possible.
- Summarize a document's important topics. NLP can combine identified entities into topics.
- Categorize documents for navigation. For this purpose, NLP uses detected topics.
- Enumerate related documents based on a selected topic. For this purpose, NLP uses detected topics.
- Score text for sentiment. By using this functionality, you can assess the positive or negative tone of a document.
Apache®, Apache Spark, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Potential use cases
Business scenarios that can benefit from custom NLP include:
- Document Intelligence for handwritten or machine-created documents in finance, healthcare, retail, government, and other sectors.
- Industry-agnostic NLP tasks for text processing, such as name entity recognition (NER), classification, summarization, and relation extraction. These tasks automate the process of retrieving, identifying, and analyzing document information like text and unstructured data. Examples of these tasks include risk stratification models, ontology classification, and retail summarizations.
- Information retrieval and knowledge graph creation for semantic search. This functionality makes it possible to create medical knowledge graphs that support drug discovery and clinical trials.
- Text translation for conversational AI systems in customer-facing applications across retail, finance, travel, and other industries.
Apache Spark as a customized NLP framework
Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. Azure Synapse Analytics, Azure HDInsight, and Azure Databricks offer access to Spark and take advantage of its processing power.
For customized NLP workloads, Spark NLP serves as an efficient framework for processing a large amount of text. This open-source NLP library provides Python, Java, and Scala libraries that offer the full functionality of traditional NLP libraries such as spaCy, NLTK, Stanford CoreNLP, and Open NLP. Spark NLP also offers functionality such as spell checking, sentiment analysis, and document classification. Spark NLP improves on previous efforts by providing state-of-the-art accuracy, speed, and scalability.
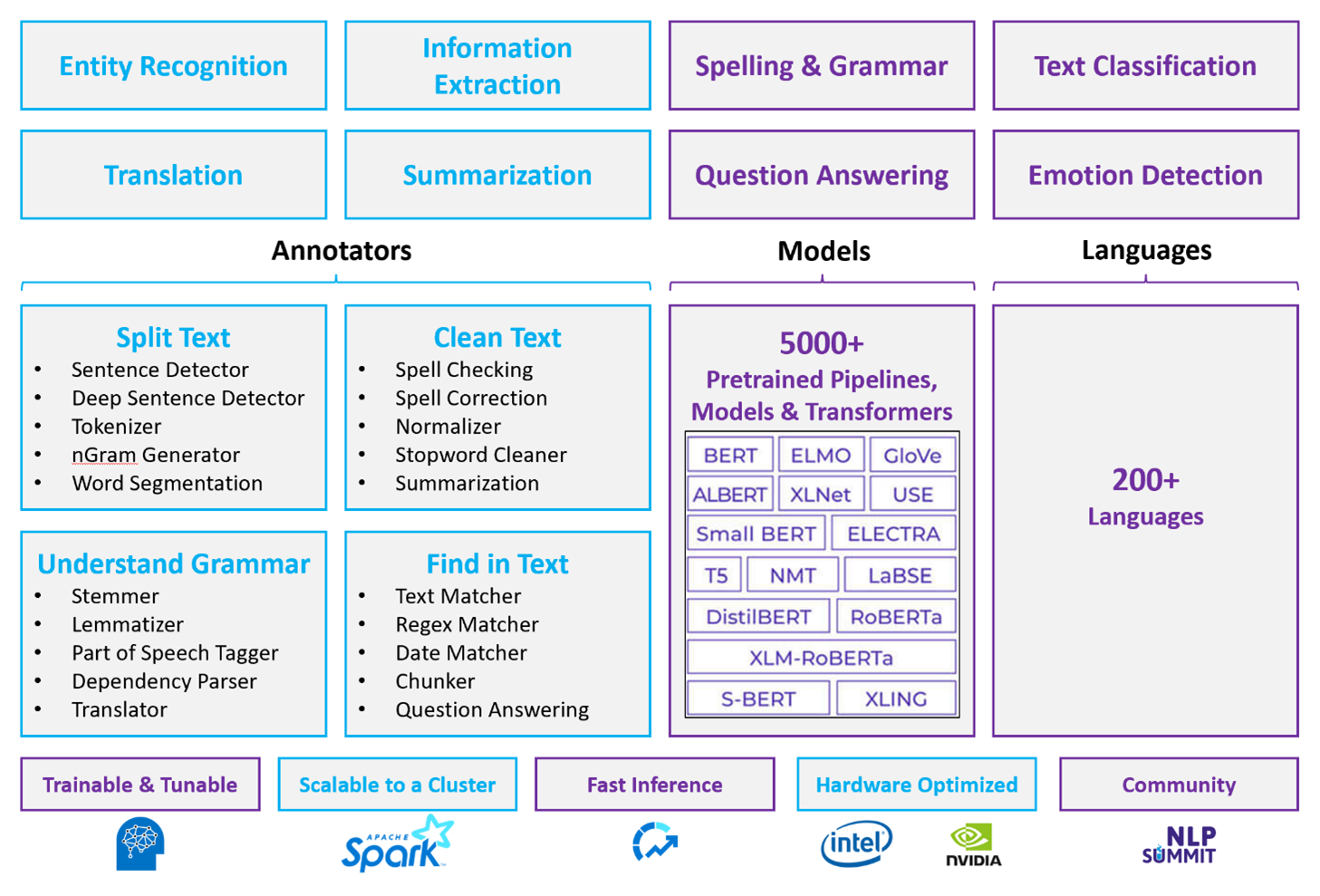
Recent public benchmarks show Spark NLP as 38 and 80 times faster than spaCy, with comparable accuracy for training custom models. Spark NLP is the only open-source library that can use a distributed Spark cluster. Spark NLP is a native extension of Spark ML that operates directly on data frames. As a result, speedups on a cluster result in another order of magnitude of performance gain. Because every Spark NLP pipeline is a Spark ML pipeline, Spark NLP is well-suited for building unified NLP and machine learning pipelines such as document classification, risk prediction, and recommender pipelines.
Besides excellent performance, Spark NLP also delivers state-of-the-art accuracy for a growing number of NLP tasks. The Spark NLP team regularly reads the latest relevant academic papers and implements state-of-the-art models. In the past two to three years, the best performing models have used deep learning. The library comes with prebuilt deep learning models for named entity recognition, document classification, sentiment and emotion detection, and sentence detection. The library also includes dozens of pre-trained language models that include support for word, chunk, sentence, and document embeddings.
The library has optimized builds for CPUs, GPUs, and the latest Intel Xeon chips. You can scale training and inference processes to take advantage of Spark clusters. These processes can run in production in all popular analytics platforms.
Challenges
- Processing a collection of free-form text documents requires a significant amount of computational resources. The processing is also time intensive. Such processes often involve GPU compute deployment.
- Without a standardized document format, it can be difficult to achieve consistently accurate results when you use free-form text processing to extract specific facts from a document. For example, think of a text representation of an invoice—it can be difficult to build a process that correctly extracts the invoice number and date when invoices are from various vendors.
Key selection criteria
In Azure, Spark services like Azure Databricks, Azure Synapse Analytics, and Azure HDInsight provide NLP functionality when you use them with Spark NLP. Azure AI services is another option for NLP functionality. To decide which service to use, consider these questions:
Do you want to use prebuilt or pretrained models? If yes, consider using the APIs that Azure AI services offers. Or download your model of choice through Spark NLP.
Do you need to train custom models against a large corpus of text data? If yes, consider using Azure Databricks, Azure Synapse Analytics, or Azure HDInsight with Spark NLP.
Do you need low-level NLP capabilities like tokenization, stemming, lemmatization, and term frequency/inverse document frequency (TF/IDF)? If yes, consider using Azure Databricks, Azure Synapse Analytics, or Azure HDInsight with Spark NLP. Or use an open-source software library in your processing tool of choice.
Do you need simple, high-level NLP capabilities like entity and intent identification, topic detection, spell check, or sentiment analysis? If yes, consider using the APIs that Azure AI services offers. Or download your model of choice through Spark NLP.
Capability matrix
The following tables summarize the key differences in the capabilities of NLP services.
General capabilities
| Capability | Spark service (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) with Spark NLP | Azure AI services |
|---|---|---|
| Provides pretrained models as a service | Yes | Yes |
| REST API | Yes | Yes |
| Programmability | Python, Scala | For supported languages, see Additional Resources |
| Supports processing of big data sets and large documents | Yes | No |
Low-level NLP capabilities
| Capability of annotators | Spark service (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) with Spark NLP | Azure AI services |
|---|---|---|
| Sentence detector | Yes | No |
| Deep sentence detector | Yes | Yes |
| Tokenizer | Yes | Yes |
| N-gram generator | Yes | No |
| Word segmentation | Yes | Yes |
| Stemmer | Yes | No |
| Lemmatizer | Yes | No |
| Part-of-speech tagging | Yes | No |
| Dependency parser | Yes | No |
| Translation | Yes | No |
| Stopword cleaner | Yes | No |
| Spell correction | Yes | No |
| Normalizer | Yes | Yes |
| Text matcher | Yes | No |
| TF/IDF | Yes | No |
| Regular expression matcher | Yes | Embedded in Language Understanding Service (LUIS). Not supported in Conversational Language Understanding (CLU), which is replacing LUIS. |
| Date matcher | Yes | Possible in LUIS and CLU through DateTime recognizers |
| Chunker | Yes | No |
High-level NLP capabilities
| Capability | Spark service (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) with Spark NLP | Azure AI services |
|---|---|---|
| Spell checking | Yes | No |
| Summarization | Yes | Yes |
| Question answering | Yes | Yes |
| Sentiment detection | Yes | Yes |
| Emotion detection | Yes | Supports opinion mining |
| Token classification | Yes | Yes, through custom models |
| Text classification | Yes | Yes, through custom models |
| Text representation | Yes | No |
| NER | Yes | Yes—text analytics provides a set of NER, and custom models are in entity recognition |
| Entity recognition | Yes | Yes, through custom models |
| Language detection | Yes | Yes |
| Supports languages besides English | Yes, supports over 200 languages | Yes, supports over 97 languages |
Set up Spark NLP in Azure
To install Spark NLP, use the following code, but replace <version> with the latest version number. For more information, see the Spark NLP documentation.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Develop NLP pipelines
For the execution order of an NLP pipeline, Spark NLP follows the same development concept as traditional Spark ML machine learning models. But Spark NLP applies NLP techniques.
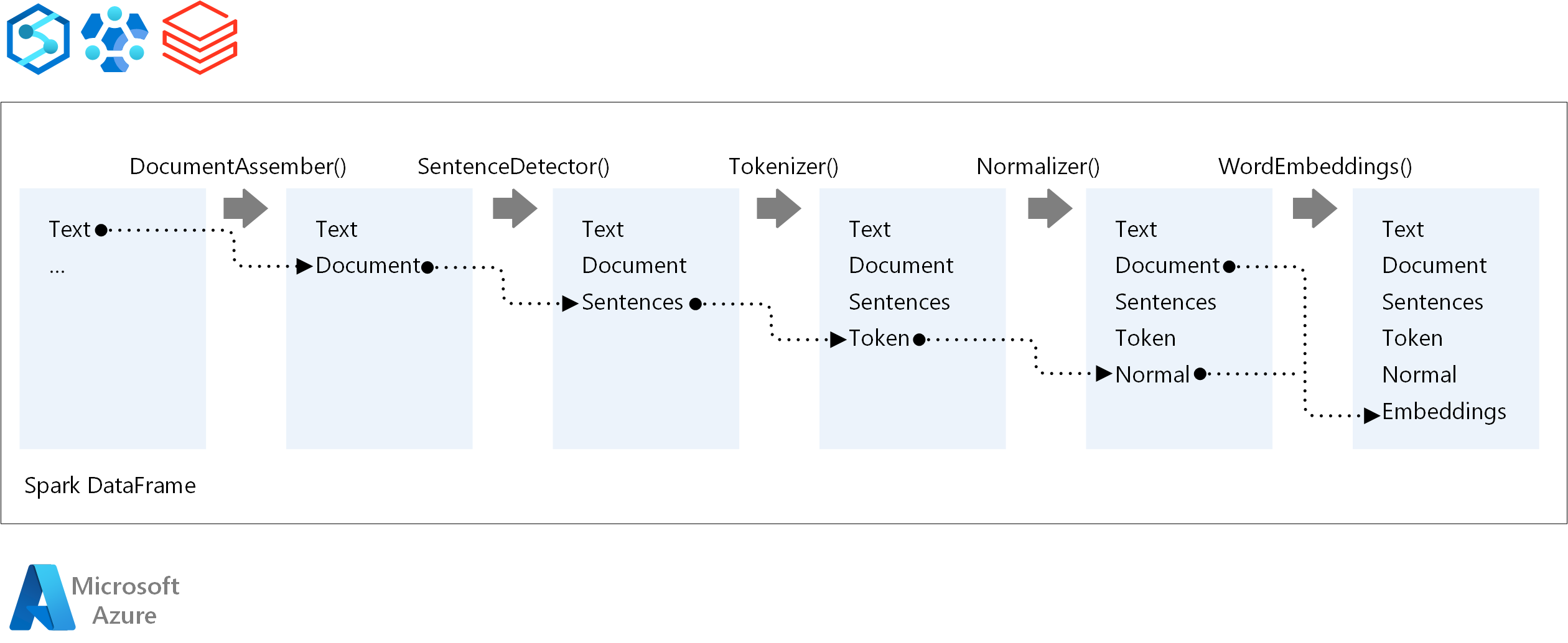
The core components of a Spark NLP pipeline are:
DocumentAssembler: A transformer that prepares data by changing it into a format that Spark NLP can process. This stage is the entry point for every Spark NLP pipeline. DocumentAssembler can read either a
Stringcolumn or anArray[String]. You can usesetCleanupModeto preprocess the text. By default, this mode is turned off.SentenceDetector: An annotator that detects sentence boundaries by using the approach that it's given. This annotator can return each extracted sentence in an
Array. It can also return each sentence in a different row, if you setexplodeSentencesto true.Tokenizer: An annotator that separates raw text into tokens, or units like words, numbers, and symbols, and returns the tokens in a
TokenizedSentencestructure. This class is non-fitted. If you fit a tokenizer, the internalRuleFactoryuses the input configuration to set up tokenizing rules. Tokenizer uses open standards to identify tokens. If the default settings don't meet your needs, you can add rules to customize Tokenizer.Normalizer: An annotator that cleans tokens. Normalizer requires stems. Normalizer uses regular expressions and a dictionary to transform text and remove dirty characters.
WordEmbeddings: Look-up annotators that map tokens to vectors. You can use
setStoragePathto specify a custom token look-up dictionary for embeddings. Each line of your dictionary needs to contain a token and its vector representation, separated by spaces. If a token isn't found in the dictionary, the result is a zero vector of the same dimension.
Spark NLP uses Spark MLlib pipelines, which MLflow natively supports. MLflow is an open-source platform for the machine learning lifecycle. Its components include:
- MLflow Tracking: Records experiments and provides a way to query results.
- MLflow Projects: Makes it possible to run data science code on any platform.
- MLflow Models: Deploys models to diverse environments.
- Model Registry: Manages models that you store in a central repository.
MLflow is integrated in Azure Databricks. You can install MLflow in any other Spark-based environment to track and manage your experiments. You can also use MLflow Model Registry to make models available for production purposes.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Moritz Steller | Senior Cloud Solution Architect
- Zoiner Tejada | CEO and Architect
Next steps
Spark NLP documentation:
Azure components:
Learn resources:
Related resources
- Large-scale custom natural language processing in Azure
- Choose a Microsoft Azure AI services technology
- Compare the machine learning products and technologies from Microsoft
- MLflow and Azure Machine Learning
- AI enrichment with image and natural language processing in Azure Cognitive Search
- Analyze news feeds with near real-time analytics using image and natural language processing