This article presents a solution and guidance for developing offline data operations and data management (DataOps) for an automated driving system. The DataOps solution is built on the framework that's outlined in Autonomous vehicle operations (AVOps) design guide. DataOps is one of the building blocks of AVOps. Other building blocks include machine learning operations (MLOps), validation operations (ValOps), DevOps, and centralized AVOps functions.
Apache®, Apache Spark, and Apache Parquet are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by the Apache Software Foundation is implied by the use of these marks.
Architecture

Download a Visio file that contains the architecture diagrams in this article.
Dataflow
Measurement data originates in a vehicle's data streams. Sources include cameras, vehicle telemetry, and radar, ultrasonic, and lidar sensors. Data loggers in the vehicle store the measurement data on logger storage devices. The logger storage data is uploaded to a landing data lake. A service like Azure Data Box or Azure Stack Edge, or a dedicated connection like Azure ExpressRoute ingests the data into Azure. Measurement data in the following formats lands in Azure Data Lake Storage: Measurement Data Format version 4 (MDF4), technical data management systems (TDMS), and rosbag. The uploaded data enters a dedicated storage account called Landing that's designated for receiving and validating the data.
An Azure Data Factory pipeline is triggered at a scheduled interval to process the data in the Landing storage account. The pipeline handles the following steps:
- Performs a data quality check such as a checksum. This step removes low-quality data so that only high-quality data passes through to the next stage. Azure App Service is used to run the quality check code. Data that's deemed incomplete is archived for future processing.
- For lineage tracking, calls a metadata API by using App Service. This step updates metadata that's stored in Azure Cosmos DB to create a new data stream. For each measurement, there's a raw data stream.
- Copies the data to a storage account called Raw in Data Lake Storage.
- Calls the metadata API to mark the data stream as complete so that other components and services can consume the data stream.
- Archives the measurements and removes them from the Landing storage account.
Data Factory and Azure Batch process the data in the raw zone to extract information that downstream systems can consume:
- Batch reads the data from topics in the raw file and outputs the data into selected topics in respective folders.
- Because the files in the raw zone can each be more than 2 GB in size, parallel processing extraction functions are run on each file. These functions extract image processing, lidar, radar, and GPS data. They also perform metadata processing. Data Factory and Batch provide a way to perform parallelism in a scalable manner.
- The data is downsampled to reduce the amount of data that needs to be labeled and annotated.
If data from the vehicle logger isn't synchronized across the various sensors, a Data Factory pipeline is triggered that syncs the data to create a valid dataset. The synchronization algorithm runs on Batch.
A Data Factory pipeline runs to enrich the data. Examples of enhancements include telemetry, vehicle logger data, and other data, such as weather, map, or object data. Enriched data helps to provide data scientists with insights that they can use in algorithm development, for example. The generated data is kept in Apache Parquet files that are compatible with the synchronized data. Metadata about the enriched data is stored in a metadata store in Azure Cosmos DB.
Third-party partners perform manual or auto labeling. The data is shared with the third-party partners via Azure Data Share and is integrated in Microsoft Purview. Data Share uses a dedicated storage account named Labeled in Data Lake Storage to return the labeled data to the organization.
A Data Factory pipeline performs scene detection. Scene metadata is kept in the metadata store. Scene data is stored as objects in Parquet or Delta files.
Besides metadata for the enrichment data and detected scenes, the metadata store in Azure Cosmos DB stores metadata for the measurements, such as drive data. This store also contains metadata for the lineage of the data as it goes through the processes of extraction, downsampling, synchronization, enrichment, and scene detection. The metadata API is used to access the measurements, the lineage, and the scene data and to look up where data is stored. As a result, the metadata API serves as a storage layer manager. It spreads data across storage accounts. It also provides developers with a way to use a metadata-based search to get data locations. For that reason, the metadata store is a centralized component that offers traceability and lineage across the solution's data flow.
Azure Databricks and Azure Synapse Analytics are used to connect with the metadata API and access Data Lake Storage and conduct research on the data.
Components
- Data Box provides a way to send terabytes of data into and out of Azure in a quick, inexpensive, and reliable way. In this solution, Data Box is used to transfer collected vehicle data to Azure via a regional carrier.
- Azure Stack Edge devices provide Azure functionality in edge locations. Examples of Azure capabilities include compute, storage, networking, and hardware-accelerated machine learning.
- ExpressRoute extends an on-premises network into the Microsoft cloud over a private connection.
- Data Lake Storage holds a large amount of data in its native, raw format. In this case, Data Lake Storage stores data based on stages, for example, raw or extracted.
- Data Factory is a fully managed, serverless solution for creating and scheduling extract, transform, load (ETL) and extract, load, transform (ELT) workflows. Here, Data Factory performs ETL via batch compute and creates data-driven workflows for orchestrating data movement and transforming data.
- Batch runs large-scale parallel and high-performance computing (HPC) batch jobs efficiently in Azure. This solution uses Batch to run large-scale applications for tasks like data wrangling, filtering and preparing data, and extracting metadata.
- Azure Cosmos DB is a globally distributed, multiple-model database. Here, it stores metadata results like stored measurements.
- Data Share shares data with partner organizations with enhanced security. By using in-place sharing, data providers can share data where it resides without copying the data or taking snapshots. In this solution, Data Share shares data with labeling companies.
- Azure Databricks provides a set of tools for maintaining enterprise-grade data solutions at scale. It's required for long-running operations on large amounts of vehicle data. Data engineers use Azure Databricks as an analytics workbench.
- Azure Synapse Analytics reduces time to insight across data warehouses and big data systems.
- Azure Cognitive Search provides data catalog search services.
- App Service provides a serverless-based web app service. In this case, App Service hosts the metadata API.
- Microsoft Purview provides data governance across organizations.
- Azure Container Registry is a service that creates a managed registry of container images. This solution uses Container Registry to store containers for processing topics.
- Application Insights is an extension of Azure Monitor that provides application performance management. In this scenario, Application Insights helps you build observability around measurement extraction: you can use Application Insights to log custom events, custom metrics, and other information while the solution processes each measurement for extraction. You can also build queries on log analytics to get detailed information about each measurement.
Scenario details
Designing a robust DataOps framework for autonomous vehicles is crucial for using your data, tracing its lineage, and making it available throughout your organization. Without a well-designed DataOps process, the massive amount of data that autonomous vehicles generate can quickly become overwhelming and difficult to manage.
When you implement an effective DataOps strategy, you help ensure that your data is properly stored, easily accessible, and has a clear lineage. You also make it easy to manage and analyze the data, leading to more informed decision-making and improved vehicle performance.
An efficient DataOps process provides a way to easily distribute data throughout your organization. Various teams can then access the information that they need to optimize their operations. DataOps makes it easy to collaborate and share insights, which helps to improve the overall effectiveness of your organization.
Typical challenges for data operations in the context of autonomous vehicles include:
- Management of the daily terabyte-scale or petabyte-scale volume of measurement data from research and development vehicles.
- Data sharing and collaboration across multiple teams and partners, for instance, for labeling, annotations, and quality checks.
- Traceability and lineage for a safety-critical perception stack that captures versioning and the lineage of measurement data.
- Metadata and data discovery to improve semantic segmentation, image classification, and object detection models.
This AVOps DataOps solution provides guidance on how to address these challenges.
Potential use cases
This solution benefits automotive original equipment manufacturers (OEMs), tier 1 vendors, and independent software vendors (ISVs) that develop solutions for automated driving.
Federated data operations
In an organization that implements AVOps, multiple teams contribute to DataOps due to the complexity that's required for AVOps. For example, one team might be in charge of data collection and data ingestion. Another team might be responsible for data quality management of lidar data. For that reason, the following principles of a data mesh architecture are important to consider for DataOps:
- Domain-oriented decentralization of data ownership and architecture. One dedicated team is responsible for one data domain that provides data products for that domain, for example, labeled datasets.
- Data as a product. Each data domain has various zones on data-lake implemented storage containers. There are zones for internal usage. There's also a zone that contains published data products for other data domains or external usage to avoid data duplication.
- Self-serve data as a platform to enable autonomous, domain-oriented data teams.
- Federated governance to enable interoperability and access between AVOps data domains that requires a centralized metadata store and data catalog. For example, a labeling data domain might need access to a data collection domain.
For more information about data mesh implementations, see Cloud-scale analytics.
Example structure for AVOps data domains
The following table provides some ideas for structuring AVOps data domains:
| Data domain | Published data products | Solution step |
|---|---|---|
| Data collection | Uploaded and validated measurement files | Landing and raw |
| Extracted images | Selected and extracted images or frames, lidar, and radar data | Extracted |
| Extracted radar or lidar | Selected and extracted lidar and radar data | Extracted |
| Extracted telemetry | Selected and extracted car telemetry data | Extracted |
| Labeled | Labeled datasets | Labeled |
| Recompute | Generated key performance indicators (KPIs) based on repeated simulation runs | Recompute |
Each AVOps data domain is set up based on a blueprint structure. That structure includes Data Factory, Data Lake Storage, databases, Batch, and Apache Spark runtimes via Azure Databricks or Azure Synapse Analytics.
Metadata and data discovery
Each data domain is decentralized and individually manages its corresponding AVOps data products. For central data discovery and to know where data products are located, two components are required:
- A metadata store that persists metadata about processed measurement files and data streams, such as video sequences. This component makes the data discoverable and traceable with annotations that need to be indexed, such as for searching the metadata of unlabeled files. For example, you might want the metadata store to return all frames for specific vehicle identification numbers (VINs) or frames with pedestrians or other enrichment-based objects.
- A data catalog that shows lineage, the dependencies between AVOps data domains, and which data stores are involved in the AVOps data loop. An example of a data catalog is Microsoft Purview.
You can use Azure Data Explorer or Azure Cognitive Search to extend a metadata store that's based on Azure Cosmos DB. Your selection depends on the final scenario that you need for data discovery. Use Azure Cognitive Search for semantic search capabilities.
The following metadata model diagram shows a typical unified metadata model that's used across several AVOps data loop pillars:
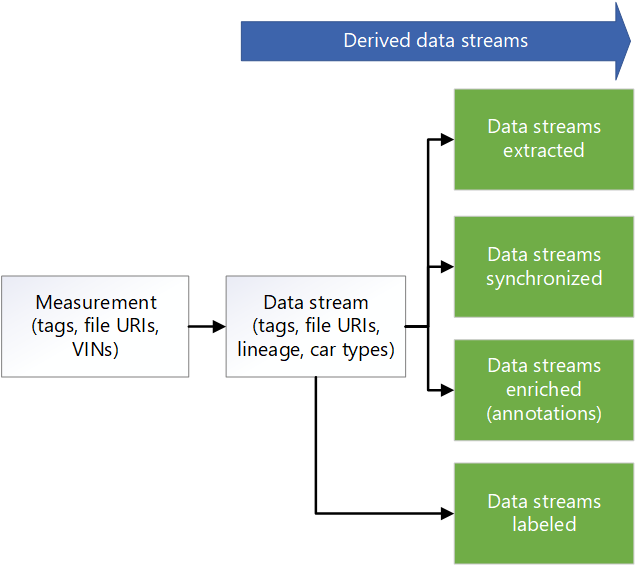
Data sharing
Data sharing is a common scenario in an AVOps data loop. Uses include data sharing between data domains and external sharing, for example, to integrate labeling partners. Microsoft Purview provides the following capabilities for efficient data sharing in a data loop:
Recommended formats for label data exchange include common objects in context (COCO) datasets and Association for Standardization of Automation and Measuring Systems (ASAM) OpenLABEL datasets.
In this solution, the labeled datasets are used in MLOps processes to create specialized algorithms such as perception and sensor fusion models. The algorithms can detect scenes and objects in an environment, such as the car changing lanes, blocked roads, pedestrian traffic, traffic lights, and traffic signs.
Data pipeline
In this DataOps solution, the movement of data between different stages in the data pipeline is automated. Through this approach, the process provides efficiency, scalability, consistency, reproducibility, adaptability, and error handling benefits. It enhances the overall development process, accelerates progress, and supports the safe and effective deployment of autonomous driving technologies.
The following sections describe how you can implement data movement between stages and how you should structure your storage accounts.
Hierarchical folder structure
A well-organized folder structure is a vital component of a data pipeline in autonomous driving development. Such a structure provides a systematic and easily navigable arrangement of data files, facilitating efficient data management and retrieval.
In this solution, the data in the raw folder has the following hierarchical structure:
region/raw/<measurement-ID>/<data-stream-ID>/YYYY/MM/DD
The data in the extracted zone storage account uses a similar hierarchical structure:
region/extracted/<measurement-ID>/<data-stream-ID>/YYYY/MM/DD
By using similar hierarchical structures, you can take advantage of the hierarchical namespace capability of Data Lake Storage. Hierarchical structures help create scalable and cost-effective object storage. These structures also improve the efficiency of object search and retrieval. Partitioning by year and VIN makes it easy to search for relevant images from specific vehicles. In the data lake, a storage container is created for each sensor, such as a camera, a GPS device, or a lidar or radar sensor.
Landing storage account to Raw storage account
A Data Factory pipeline is triggered based on a schedule. After the pipeline is triggered, the data is copied from the Landing storage account to the Raw storage account.

The pipeline retrieves all the measurement folders and iterates through them. With each measurement, the solution performs the following activities:
A function validates the measurement. The function retrieves the manifest file from the measurement manifest. Then the function checks whether all the MDF4, TDMS, and rosbag measurement files for the current measurement exist in the measurement folder. If the validation succeeds, the function proceeds to the next activity. If the validation fails, the function skips the current measurement and moves to the next measurement folder.
A web API call is made to an API that creates a measurement, and the JSON payload from the measurement manifest JSON file is passed to the API. If the call succeeds, the response is parsed to retrieve the measurement ID. If the call fails, the measurement is moved to the on-error activity for error handling.
Note
This DataOps solution is built on the assumption that you limit the number of requests to the app service. If your solution might make an indeterminate number of requests, consider a rate limiting pattern.
A web API call is made to an API that creates a data stream by creating the required JSON payload. If the call succeeds, the response is parsed to retrieve the data stream ID and the data stream location. If the call fails, the measurement is moved to the on-error activity.
A web API call is made to update the state of the data stream to
Start Copy. If the call succeeds, the copy activity copies measurement files to the data stream location. If the call fails, the measurement is moved to the on-error activity.A Data Factory pipeline invokes Batch to copy the measurement files from the Landing storage account to the Raw storage account. A copy module of an orchestrator app creates a job with the following tasks for each measurement:
- Copy the measurement files to the Raw storage account.
- Copy the measurement files to an archive storage account.
- Remove the measurement files from the Landing storage account.
Note
In these tasks, Batch uses an orchestrator pool and the AzCopy tool to copy and remove data. AzCopy uses SAS tokens to perform copy or removal tasks. SAS tokens are stored in a key vault and are referenced by using the terms
landingsaskey,archivesaskey, andrawsaskey.A web API call is made to update the state of the data stream to
Copy Complete. If the call succeeds, the sequence proceeds to the next activity. If the call fails, the measurement is moved to the on-error activity.The measurement files are moved from the Landing storage account to a landing archive. This activity can rerun a particular measurement by moving it back to the Landing storage account via a hydrate copy pipeline. Lifecycle management is turned on for this zone so that measurements in this zone are automatically deleted or archived.
If an error occurs with a measurement, the measurement is moved to an error zone. From there, it can be moved to the Landing storage account to be run again. Alternatively, lifecycle management can automatically delete or archive the measurement.
Note the following points:
- These pipelines are triggered based on a schedule. This approach helps to improve the traceability of pipeline runs and to avoid unnecessary runs.
- Each pipeline is configured with a concurrency value of one to make sure any previous runs finish before the next scheduled run starts.
- Each pipeline is configured to copy measurements in parallel. For instance, if a scheduled run picks up 10 measurements to copy, the pipeline steps can be run concurrently for all ten measurements.
- Each pipeline is configured to generate an alert in Monitor if the pipeline takes longer than the expected time to finish.
- The on-error activity is implemented in later observability stories.
- Lifecycle management automatically deletes partial measurements, for example, measurements with missing rosbag files.
Batch design
All extraction logic is packaged in different container images, with one container for each extraction process. Batch runs the container workloads in parallel when it extracts information from measurement files.

Batch uses an orchestrator pool and an execution pool for processing workloads:
- An orchestrator pool has Linux nodes without container runtime support. The pool runs Python code that uses the Batch API to create jobs and tasks for the execution pool. This pool also monitors those tasks. Data Factory invokes the orchestrator pool, which orchestrates the container workloads that extract data.
- An execution pool has Linux nodes with container runtimes to support running container workloads. For this pool, jobs and tasks are scheduled via the orchestrator pool. All the container images that are required for processing in the execution pool are pushed to a container registry by using JFrog. The execution pool is configured to connect to this registry and pull the required images.
Storage accounts that data is read from and written to are mounted via NFS 3.0 on the batch nodes and the containers that run on the nodes. This approach helps batch nodes and containers process data quickly without the need to download the data files locally to the batch nodes.
Note
The batch and storage accounts need to be in the same virtual network for mounting.
Invoke Batch from Data Factory
In the extraction pipeline, the trigger passes the path of the metadata file and the raw data stream path in the pipeline parameters. Data Factory uses a Lookup activity to parse the JSON from the manifest file. The raw data stream ID can be extracted from the raw data stream path by parsing the pipeline variable.
Data Factory calls an API to create a data stream. The API returns the path for the extracted data stream. The extracted path is added to the current object, and Data Factory invokes Batch via a custom activity by passing the current object, after appending the extracted data stream path:
{
"measurementId":"210b1ba7-9184-4840-a1c8-eb£397b7c686",
"rawDataStreamPath":"raw/2022/09/30/KA123456/210b1ba7-9184-4840-
alc8-ebf39767c68b/57472a44-0886-475-865a-ca32{c851207",
"extractedDatastreamPath":"extracted/2022/09/30/KA123456
/210bIba7-9184-4840-a1c8-ebf39767c68b/87404c9-0549-4a18-93ff-d1cc55£d8b78",
"extractedDataStreamId":"87404bc9-0549-4a18-93ff-d1cc55fd8b78"
}
Stepwise extraction process

Data Factory schedules a job with one task for the orchestrator pool to process a measurement for extraction. Data Factory passes the following information to the orchestrator pool:
- The measurement ID
- The location of the measurement files of type MDF4, TDMS, or rosbag that need to be extracted
- The destination path of the storage location of the extracted contents
- The extracted data stream ID
The orchestrator pool invokes an API to update the data stream and set its status to
Processing.The orchestrator pool creates a job for each measurement file that's part of the measurement. Each job contains the following tasks:
Task Purpose Note Validation Validates that data can be extracted from the measurement file. All other tasks depend on this task. Process metadata Derives metadata from the measurement file and enriches the file's metadata by using an API to update the file's metadata. Process StructuredTopicsExtracts structured data from a given measurement file. The list of topics to extract structured data from is passed as a configuration object. Process CameraTopicsExtracts image data from a given measurement file. The list of topics to extract images from is passed as a configuration object. Process LidarTopicsExtracts lidar data from a given measurement file. The list of topics to extract lidar data from is passed as a configuration object. Process CANTopicsExtracts controller area network (CAN) data from a given measurement file. The list of topics to extract data from is passed as a configuration object. The orchestrator pool monitors the progress of each task. After all the jobs finish for all measurement files, the pool invokes an API to update the data stream and set its status to
Completed.The orchestrator exits gracefully.
Note
Each task is a separate container image that has logic that's appropriately defined for its purpose. Tasks accept configuration objects as input. For example, the input specifies where to write the output and which measurement file to process. An array of topic types, such as
sensor_msgs/Image, is another example of input. Because all other tasks depend on the validation task, a dependent task is created for it. All other tasks can be processed independently and can run in parallel.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Reliability
Reliability ensures your application can meet the commitments you make to your customers. For more information, see Overview of the reliability pillar.
- In your solution, consider using Azure availability zones, which are unique physical locations within the same Azure region.
- Plan for disaster recovery and account failover.
Security
Security provides assurances against deliberate attacks and the abuse of your valuable data and systems. For more information, see Overview of the security pillar.
It's important to understand the division of responsibility between an automotive OEM and Microsoft. In a vehicle, the OEM owns the whole stack, but as the data moves to the cloud, some responsibilities transfer to Microsoft. Azure platform as a service (PaaS) layers provide built-in security on the physical stack, including the operating system. You can add the following capabilities to the existing infrastructure security components:
- Identity and access management that uses Microsoft Entra identities and Microsoft Entra Conditional Access policies.
- Infrastructure governance that uses Azure Policy.
- Data governance that uses Microsoft Purview.
- Encryption of data at rest that uses native Azure storage and database services. For more information, see Data protection considerations.
- The safeguarding of cryptographic keys and secrets. Use Azure Key Vault for this purpose.
Cost optimization
Cost optimization looks at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Overview of the cost optimization pillar.
A key concern for OEMs and tier 1 suppliers that operate DataOps for automated vehicles is the cost of operating. This solution uses the following practices to help optimize costs:
- Taking advantage of various options that Azure offers for hosting application code. This solution uses App Service and Batch. For guidance about how to choose the right service for your deployment, see Choose an Azure compute service.
- Using Azure Storage in-place data sharing.
- Optimizing costs by using lifecycle management.
- Saving costs on App Service by using reserved instances.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal authors:
- Ryan Matsumura | Senior Program Manager
- Jochen Schroeer | Lead Architect (Service Line Mobility)
- Brij Singh | Principal Software Engineer
- Ginette Vellera | Senior Software Engineering Lead
To see nonpublic LinkedIn profiles, sign in to LinkedIn.
Next steps
- What is Azure Batch?
- What is Azure Data Factory?
- Introduction to Azure Data Lake Storage Gen2
- Welcome to Azure Cosmos DB
- App Service overview
- What is Azure Data Share?
- What is Azure Data Box?
- Azure Stack Edge documentation
- What is Azure ExpressRoute?
- What is Azure Machine Learning?
- What is Azure Databricks?
- What is Azure Synapse Analytics?
- Azure Monitor overview
- ROS Log Files (rosbags)
- Large-scale Data Operations Platform for Autonomous Vehicles