Serverless compute for notebooks
Important
This feature is in Public Preview. For information on eligibility and enablement, see Enable serverless compute.
This article explains how to use serverless compute for notebooks. For information on using serverless compute for workflows, see Run your Azure Databricks job with serverless compute for workflows.
For pricing information, see Databricks pricing.
Requirements
Your workspace must be enabled for Unity Catalog.
Your workspace must be in a supported region. See Azure Databricks regions.
Your account must be enabled for serverless compute. See Enable serverless compute.
Attach a notebook to serverless compute
If your workspace is enabled for serverless interactive compute, all users in the workspace have access to serverless compute for notebooks. No additional permissions are required.
To attach to the serverless compute, click the Connect drop-down menu in the notebook and select Serverless. For new notebooks, the attached compute automatically defaults to serverless upon code execution if no other resource has been selected.
Install notebook dependencies
You can install Python dependencies for serverless notebooks using the Environment side panel, which provides a single place to edit, view, and export the library requirements for a notebook. These dependencies can be added using a base environment or individually.
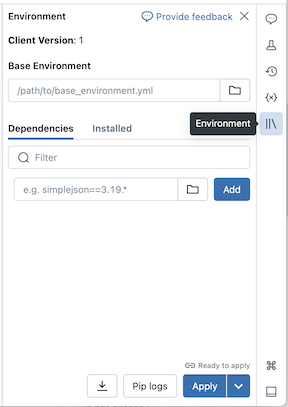
Configure a base environment
A base environment is a YAML file stored as a workspace file or on a Unity Catalog volume that specifies additional environment dependencies. Base environments can be shared among notebooks. To configure a base environment:
Create a YAML file that defines settings for a Python virtual environment. The following example YAML, which is based on the MLflow projects environment specification, defines a base environment with a few library dependencies:
client: "1" dependencies: - --index-url https://pypi.org/simple - -r "/Workspace/Shared/requirements.txt" - cowsay==6.1Upload the YAML file as a workspace file or to a Unity Catalog volume. See Import a file or Upload files to a Unity Catalog volume.
To the right of the notebook, click the
 button to expand the Environment panel. This button only appears when a notebook is connected to serverless compute.
button to expand the Environment panel. This button only appears when a notebook is connected to serverless compute.In the Base Environment field, enter the path of the uploaded YAML file or navigate to it and select it.
Click Apply. This installs the dependencies in the notebook virtual environment and restarts the Python process.
Users can override the dependencies specified in the base environment by installing dependencies individually.
Add dependencies individually
You can also install dependencies on a notebook connected to serverless compute using the Dependencies tab of the Environment panel:
- To the right of the notebook, click on the button to expand the Environment panel. This button only appears when a notebook is connected to serverless compute.
- In the Dependencies section, click Add Dependency and enter the path of the library dependency in the field. You can specify a dependency in any format that is valid in a requirements.txt file.
- Click Apply. This installs the dependencies in the notebook virtual environment and restarts the Python process.
Note
A job using serverless compute will install the environment specification of the notebook before executing the notebook code. This means that there is no need to add dependencies when scheduling notebooks as jobs. See Configure notebook environments and dependencies.
View installed dependencies and pip logs
To view installed dependencies, click Installed in the Environments side panel for a notebook. Pip installation logs for the notebook environment are also available by clicking Pip logs at the bottom of the panel.
Reset the environment
If your notebook is connected to serverless compute, Databricks automatically caches the content of the notebook’s virtual environment. This means you generally do not need to reinstall the Python dependencies specified in the Environment panel when you open an existing notebook, even if it has been disconnected due to inactivity.
Python virtual environment caching also applies to jobs. This means that subsequent runs of jobs are faster as required dependencies are already available.
Note
If you change the implementation of a custom Python package that is used in a job on serverless, you must also update its version number for jobs to pick up the latest implementation.
To clear the environment cache and perform a fresh install of the dependencies specified in the Environment panel of a notebook attached to serverless compute, click the arrow next to Apply and then click Reset environment.
Note
Reset the virtual environment if you install packages that break or change the core notebook or Apache Spark environment. Detaching the notebook from serverless compute and reattaching it does not necessarily clear the entire environment cache.
View query insights
Serverless compute for notebooks and workflows uses query insights to assess Spark execution performance. After running a cell in a notebook, you can view insights related to SQL and Python queries by clicking the See performance link.
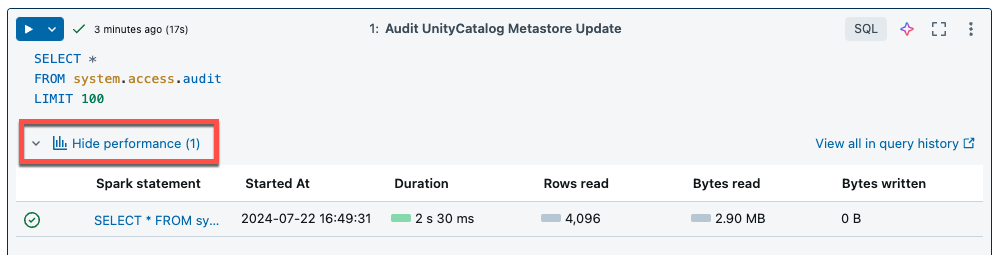
You can click on any of the Spark statements to view the query metrics. From there you can click See query profile to see a visualization of the query execution. For more information on query profiles, see Query profile.
Note
To view performance insights for your job runs, see View job run query insights.
Query history
All queries that are run on serverless compute will also be recorded on your workspace’s query history page. For information on query history, see Query history.
Query insight limitations
- The query profile is only available after the query execution terminates.
- Metrics are updated live although the query profile is not shown during execution.
- Only the following query statuses are covered: RUNNING, CANCELED, FAILED, FINISHED.
- Running queries cannot be canceled from the query history page. They can be canceled in notebooks or jobs.
- Verbose metrics are not available.
- Query Profile download is not available.
- Access to the Spark UI is not available.
- The statement text only contains the last line that was run. However, there might be several lines preceding this line that were run as part of the same statement.
Limitations
For a list of limitations, see Serverless compute limitations.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for