LLMOps workflows on Azure Databricks
This article complements MLOps workflows on Databricks by adding information specific to LLMOps workflows. For more details, see The Big Book of MLOps.
How does the MLOps workflow change for LLMs?
LLMs are a class of natural language processing (NLP) models that have significantly surpassed their predecessors in size and performance across a variety of tasks, such as open-ended question answering, summarization, and execution of instructions.
Development and evaluation of LLMs differs in some important ways from traditional ML models. This section briefly summarizes some of the key properties of LLMs and the implications for MLOps.
| Key properties of LLMs | Implications for MLOps |
|---|---|
| LLMs are available in many forms. - General proprietary and OSS models that are accessed using paid APIs. - Off-the-shelf open source models that vary from general to specific applications. - Custom models that have been fine-tuned for specific applications. - Custom pre-trained applications. |
Development process: Projects often develop incrementally, starting from existing, third-party or open source models and ending with custom fine-tuned models. |
| Many LLMs take general natural language queries and instructions as input. Those queries can contain carefully engineered prompts to elicit the desired responses. | Development process: Designing text templates for querying LLMs is often an important part of developing new LLM pipelines. Packaging ML artifacts: Many LLM pipelines use existing LLMs or LLM serving endpoints. The ML logic developed for those pipelines might focus on prompt templates, agents, or chains instead of the model itself. The ML artifacts packaged and promoted to production might be these pipelines, rather than models. |
| Many LLMs can be given prompts with examples, context, or other information to help answer the query. | Serving infrastructure: When augmenting LLM queries with context, you might use additional tools such as vector databases to search for relevant context. |
| Third-party APIs provide proprietary and open-source models. | API governance: Using centralized API governance provides the ability to easily switch between API providers. |
| LLMs are very large deep learning models, often ranging from gigabytes to hundreds of gigabytes. | Serving infrastructure: LLMs might require GPUs for real-time model serving, and fast storage for models that need to be loaded dynamically. Cost/performance tradeoffs: Because larger models require more computation and are more expensive to serve, techniques for reducing model size and computation might be required. |
| LLMs are hard to evaluate using traditional ML metrics since there is often no single “right” answer. | Human feedback: Human feedback is essential for evaluating and testing LLMs. You should incorporate user feedback directly into the MLOps process, including for testing, monitoring, and future fine-tuning. |
Commonalities between MLOps and LLMOps
Many aspects of MLOps processes do not change for LLMs. For example, the following guidelines also apply to LLMs:
- Use separate environments for development, staging, and production.
- Use Git for version control.
- Manage model development with MLflow, and use Models in Unity Catalog to manage the model lifecycle.
- Store data in a lakehouse architecture using Delta tables.
- Your existing CI/CD infrastructure should not require any changes.
- The modular structure of MLOps remains the same, with pipelines for featurization, model training, model inference, and so on.
Reference architecture diagrams
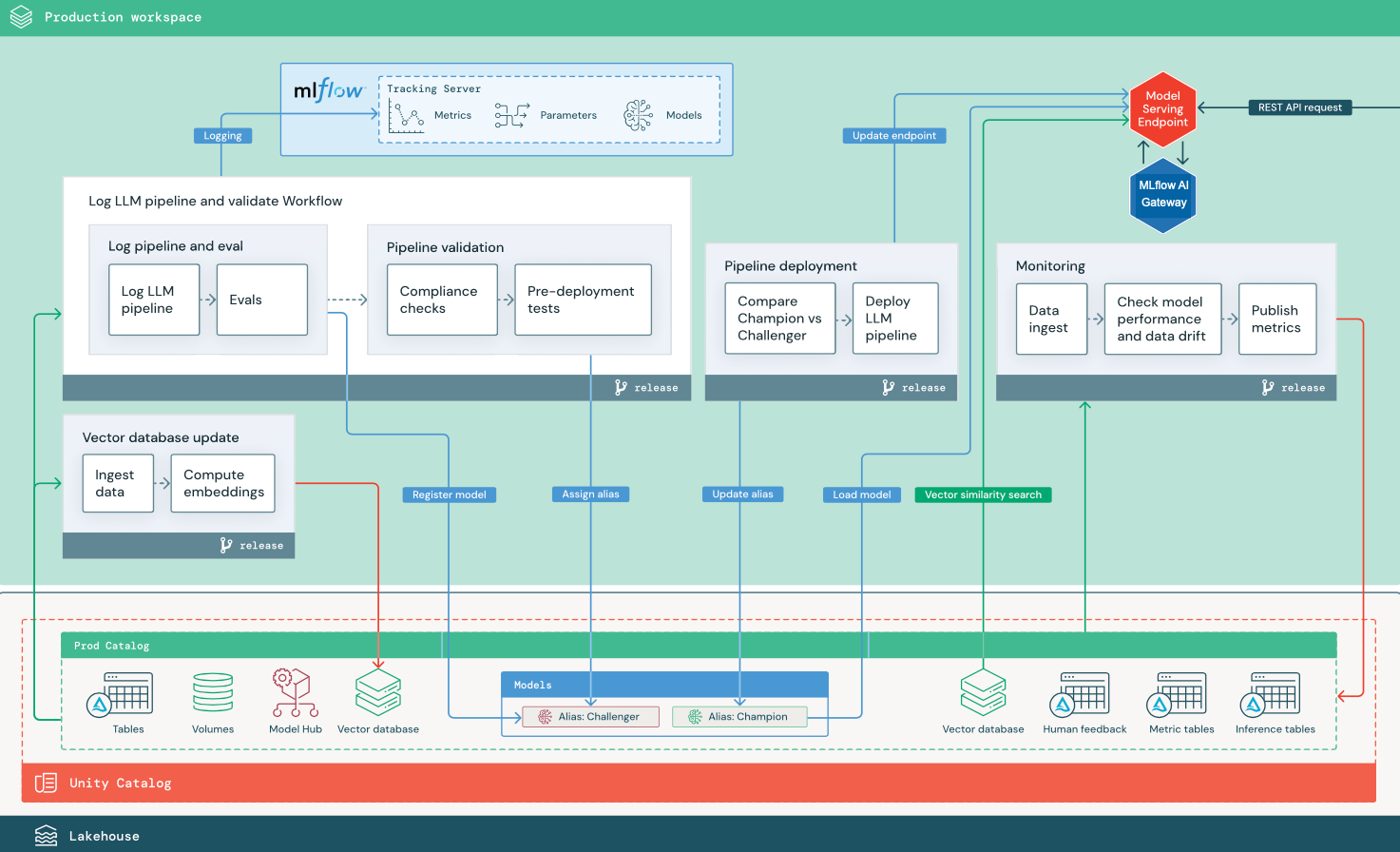
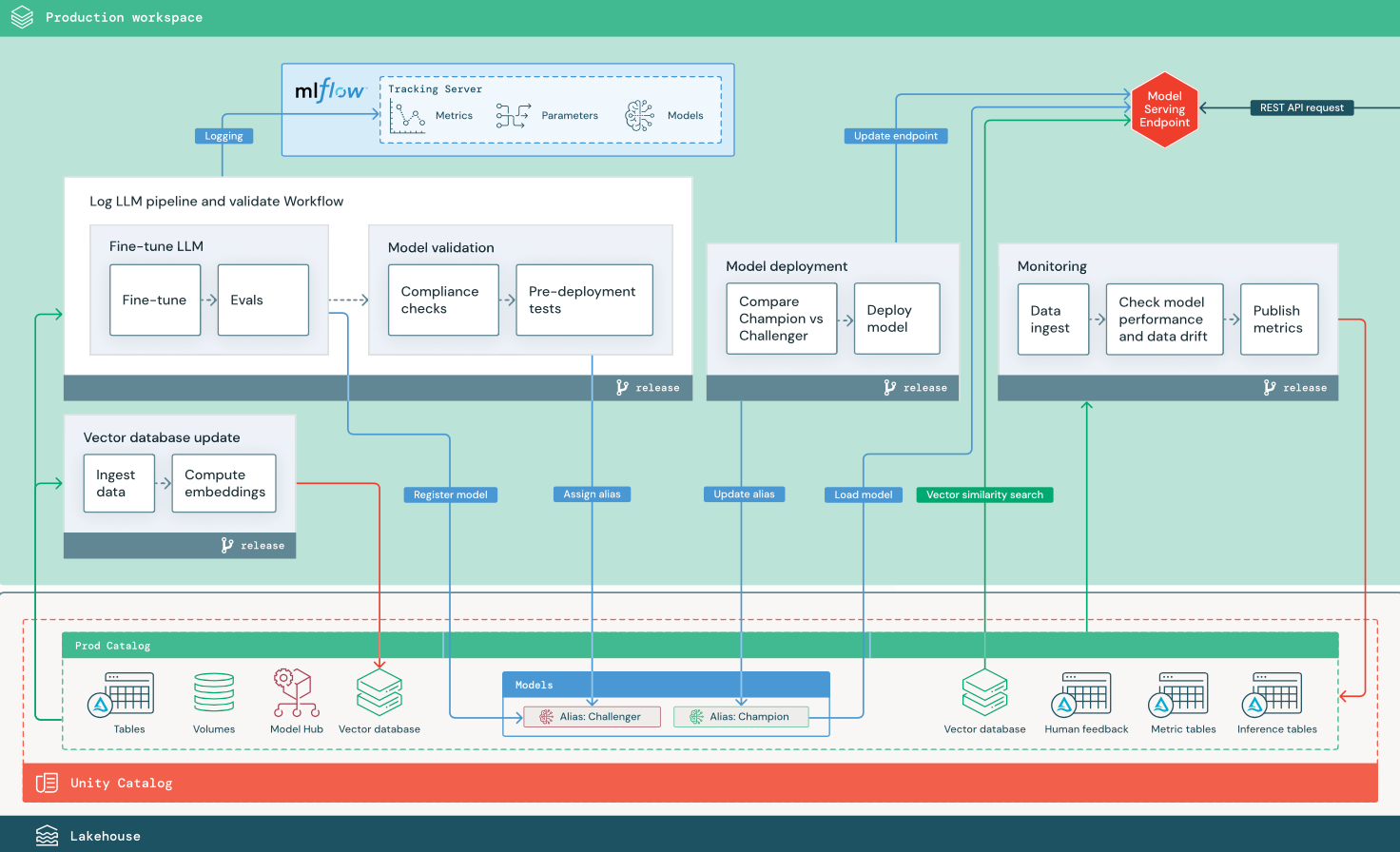
This section uses two LLM-based applications to illustrate some of the adjustments to the reference architecture of traditional MLOps. The diagrams show the production architecture for 1) a retrieval-augmented generation (RAG) application using a third-party API, and 2) a RAG application using a self-hosted fine-tuned model. Both diagrams show an optional vector database — this item can be replaced by directly querying the LLM through the Model Serving endpoint.
RAG with a third-party LLM API
The diagram shows a production architecture for a RAG application that connects to a third-party LLM API using Databricks External Models.
RAG with a fine-tuned open source model
The diagram shows a production architecture for a RAG application that fine-tunes an open source model.
LLMOps changes to MLOps production architecture
This section highlights the major changes to the MLOps reference architecture for LLMOps applications.
Model hub
LLM applications often use existing, pretrained models selected from an internal or external model hub. The model can be used as-is or fine-tuned.
Databricks includes a selection of high-quality, pre-trained foundation models in Unity Catalog and in Databricks Marketplace. You can use these pre-trained models to access state-of-the-art AI capabilities, saving you the time and expense of building your own custom models. For details, see Pre-trained models in Unity Catalog and Marketplace.
Vector database
Some LLM applications use vector databases for fast similarity searches, for example to provide context or domain knowledge in LLM queries. Databricks provides an integrated vector search functionality that lets you use any Delta table in Unity Catalog as a vector database. The vector search index automatically syncs with the Delta table. For details, see Vector Search.
You can create a model artifact that encapsulates the logic to retrieve information from a vector database and provides the returned data as context to the LLM. You can then log the model using the MLflow LangChain or PyFunc model flavor.
Fine-tune LLM
Because LLM models are expensive and time-consuming to create from scratch, LLM applications often fine-tune an existing model to improve its performance in a particular scenario. In the reference architecture, fine-tuning and model deployment are represented as distinct Databricks Jobs. Validating a fine-tuned model before deploying is often a manual process.
Databricks provides Foundation Model Fine-tuning, which lets you use your own data to customize an existing LLM to optimize its performance for your specific application. For details, see Foundation Model Fine-tuning.
Model serving
In the RAG using a third-party API scenario, an important architectural change is that the LLM pipeline makes external API calls, from the Model Serving endpoint to internal or third-party LLM APIs. This adds complexity, potential latency, and additional credential management.
Databricks provides Mosaic AI Model Serving, which provides a unified interface to deploy, govern, and query AI models. For details, see Mosaic AI Model Serving.
Human feedback in monitoring and evaluation
Human feedback loops are essential in most LLM applications. Human feedback should be managed like other data, ideally incorporated into monitoring based on near real-time streaming.
The Mosaic AI Agent Framework review app helps you gather feedback from human reviewers. For details, see Get feedback about the quality of an agentic application.