Apache Flink® job orchestration using Azure Data Factory Workflow Orchestration Manager (powered by Apache Airflow)
Note
We will retire Azure HDInsight on AKS on January 31, 2025. Before January 31, 2025, you will need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads. The remaining clusters on your subscription will be stopped and removed from the host.
Only basic support will be available until the retirement date.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
This article covers managing a Flink job using Azure REST API and orchestration data pipeline with Azure Data Factory Workflow Orchestration Manager. Azure Data Factory Workflow Orchestration Manager service is a simple and efficient way to create and manage Apache Airflow environments, enabling you to run data pipelines at scale easily.
Apache Airflow is an open-source platform that programmatically creates, schedules, and monitors complex data workflows. It allows you to define a set of tasks, called operators that can be combined into directed acyclic graphs (DAGs) to represent data pipelines.
The following diagram shows the placement of Airflow, Key Vault, and HDInsight on AKS in Azure.

Multiple Azure Service Principals are created based on the scope to limit the access it needs and to manage the client credential life cycle independently.
It is recommended to rotate access keys or secrets periodically.
Setup steps
Upload your Flink Job jar to the storage account. It can be the primary storage account associated with the Flink cluster or any other storage account, where you should assign the "Storage Blob Data Owner" role to the user-assigned MSI used for the cluster in this storage account.
Azure Key Vault - You can follow this tutorial to create a new Azure Key Vault in case, if you don't have one.
Create Microsoft Entra service principal to access Key Vault – Grant permission to access Azure Key Vault with the “Key Vault Secrets Officer” role, and make a note of ‘appId’ ‘password’, and ‘tenant’ from the response. We need to use the same for Airflow to use Key Vault storage as backends for storing sensitive information.
az ad sp create-for-rbac -n <sp name> --role “Key Vault Secrets Officer” --scopes <key vault Resource ID>Enable Azure Key Vault for Workflow Orchestration Manager to store and manage your sensitive information in a secure and centralized manner. By doing this, you can use variables and connections, and they automatically be stored in Azure Key Vault. The name of connections and variables need to be prefixed by variables_prefix defined in AIRFLOW__SECRETS__BACKEND_KWARGS. For example, If variables_prefix has a value as hdinsight-aks-variables then for a variable key of hello, you would want to store your Variable at hdinsight-aks-variable -hello.
Add the following settings for the Airflow configuration overrides in integrated runtime properties:
AIRFLOW__SECRETS__BACKEND:
"airflow.providers.microsoft.azure.secrets.key_vault.AzureKeyVaultBackend"AIRFLOW__SECRETS__BACKEND_KWARGS:
"{"connections_prefix": "airflow-connections", "variables_prefix": "hdinsight-aks-variables", "vault_url": <your keyvault uri>}”
Add the following setting for the Environment variables configuration in the Airflow integrated runtime properties:
AZURE_CLIENT_ID =
<App Id from Create Azure AD Service Principal>AZURE_TENANT_ID =
<Tenant from Create Azure AD Service Principal>AZURE_CLIENT_SECRET =
<Password from Create Azure AD Service Principal>
Add Airflow requirements - apache-airflow-providers-microsoft-azure

Create Microsoft Entra service principal to access Azure – Grant permission to access HDInsight AKS Cluster with Contributor role, make a note of appId, password, and tenant from the response.
az ad sp create-for-rbac -n <sp name> --role Contributor --scopes <Flink Cluster Resource ID>Create the following secrets in your key vault with the value from the previous AD Service principal appId, password, and tenant, prefixed by property variables_prefix defined in AIRFLOW__SECRETS__BACKEND_KWARGS. The DAG code can access any of these variables without variables_prefix.
hdinsight-aks-variables-api-client-id=
<App ID from previous step>hdinsight-aks-variables-api-secret=
<Password from previous step>hdinsight-aks-variables-tenant-id=
<Tenant from previous step>
from airflow.models import Variable def retrieve_variable_from_akv(): variable_value = Variable.get("client-id") print(variable_value)

DAG definition
A DAG (Directed Acyclic Graph) is the core concept of Airflow, collecting Tasks together, organized with dependencies and relationships to say how they should run.
There are three ways to declare a DAG:
You can use a context manager, which adds the DAG to anything inside it implicitly
You can use a standard constructor, passing the DAG into any operators you use
You can use the @dag decorator to turn a function into a DAG generator (from airflow.decorators import dag)
DAGs are nothing without Tasks to run, and those are come in the form of either Operators, Sensors or TaskFlow.
You can read more details about DAGs, Control Flow, SubDAGs, TaskGroups, etc. directly from Apache Airflow.
DAG execution
Example code is available on the git; download the code locally on your computer and upload the wordcount.py to a blob storage. Follow the steps to import DAG into your workflow created during setup.
The wordcount.py is an example of orchestrating a Flink job submission using Apache Airflow with HDInsight on AKS. The DAG has two tasks:
get
OAuth TokenInvoke HDInsight Flink Job Submission Azure REST API to submit a new job
The DAG expects to have setup for the Service Principal, as described during the setup process for the OAuth Client credential and pass the following input configuration for the execution.
Execution steps
Execute the DAG from the Airflow UI, you can open the Azure Data Factory Workflow Orchestration Manager UI by clicking on Monitor icon.

Select the “FlinkWordCountExample” DAG from the “DAGs” page.

Click on the “execute” icon from the top right corner and select “Trigger DAG w/ config”.

Pass required configuration JSON
{ "jarName":"WordCount.jar", "jarDirectory":"abfs://filesystem@<storageaccount>.dfs.core.windows.net", "subscritpion":"<cluster subscription id>", "rg":"<cluster resource group>", "poolNm":"<cluster pool name>", "clusterNm":"<cluster name>" }Click on “Trigger” button, it starts the execution of the DAG.
You can visualize the status of DAG tasks from the DAG run
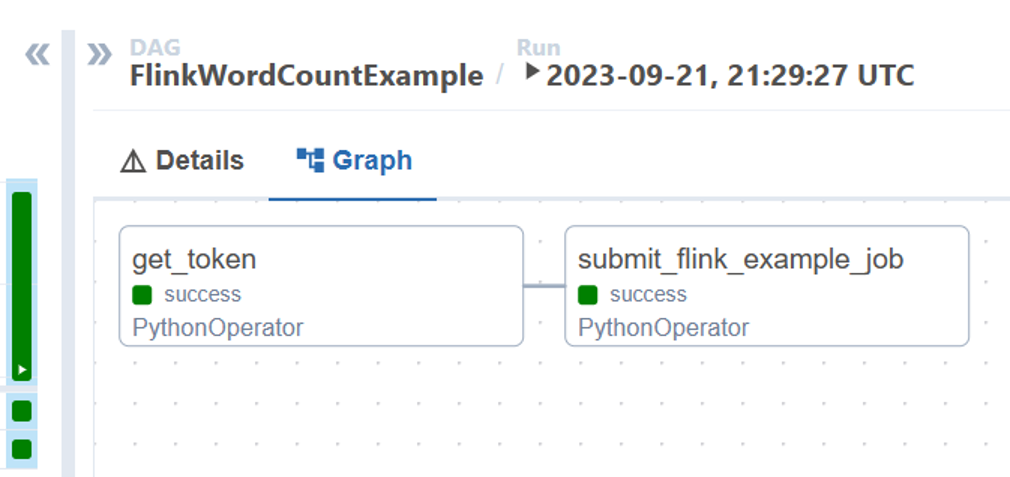
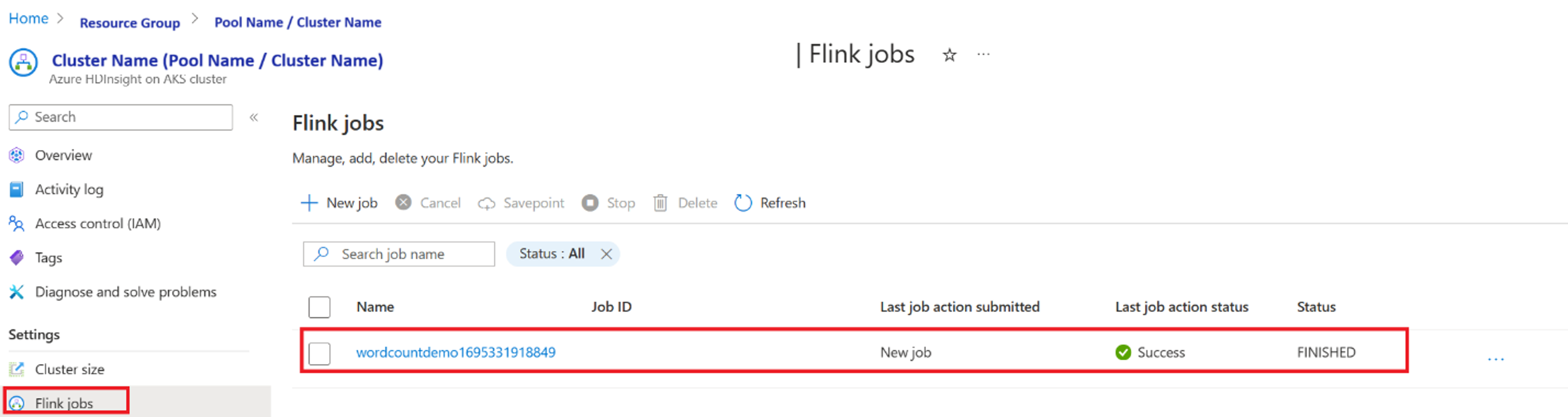
Validate the job execution from portal
Validate the job from “Apache Flink Dashboard”







Example code
This is an example of orchestrating data pipeline using Airflow with HDInsight on AKS.
The DAG expects to have setup for Service Principal for the OAuth Client credential and pass following input configuration for the execution:
{
'jarName':'WordCount.jar',
'jarDirectory':'abfs://filesystem@<storageaccount>.dfs.core.windows.net',
'subscritpion':'<cluster subscription id>',
'rg':'<cluster resource group>',
'poolNm':'<cluster pool name>',
'clusterNm':'<cluster name>'
}
Reference
- Refer to the sample code.
- Apache Flink Website
- Apache, Apache Airflow, Airflow, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).