Choose the best Fabric CI/CD workflow option for you
The goal of this article is to present Fabric developers with different options for building CI/CD processes in Fabric, based on common customer scenarios. This article focuses more on the continuous deployment (CD) of the CI/CD process. For a discussion on the continuous integration (CI) part, see Manage Git branches.
While this article outlines several distinct options, many organizations take a hybrid approach.
Prerequisites
To access the deployment pipelines feature, you must meet the following conditions:
You have a Microsoft Fabric subscription
You're an admin of a Fabric workspace
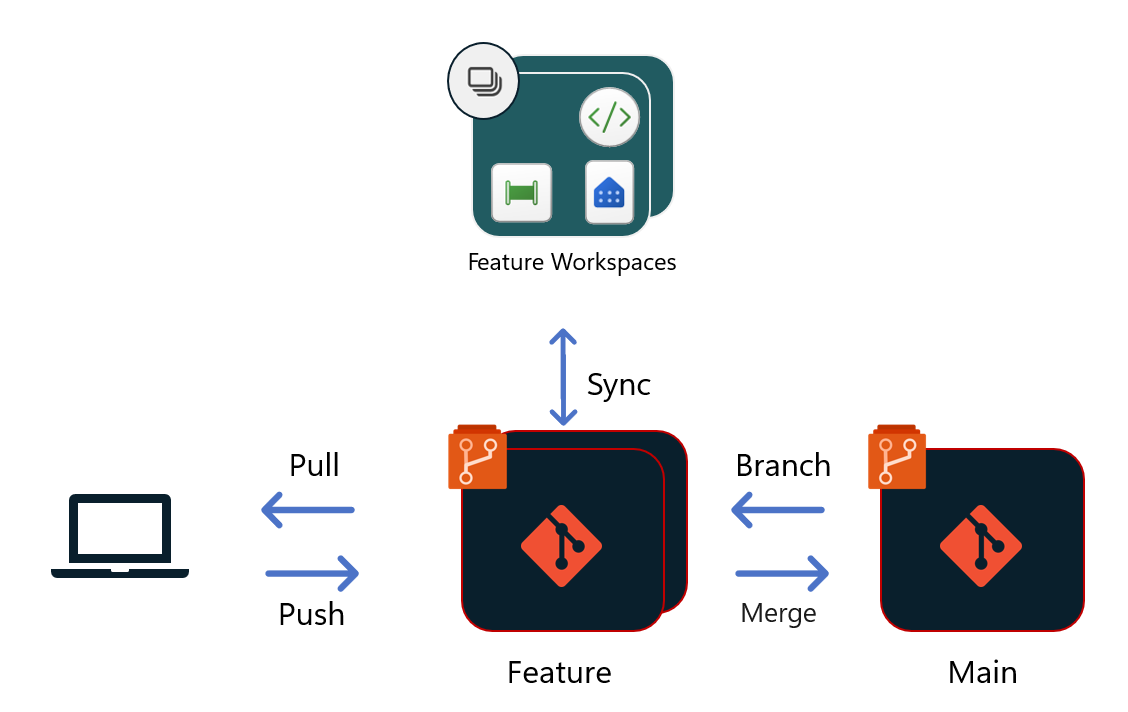
Development process
The development process is the same in all deployment scenarios, and is independent of how to release new updates into production. When developers work with source control, they need to work in an isolated environment. In Fabric, that environment can either be an IDE on your local machine (such as Power BI Desktop, or VS Code), or a different workspace in Fabric. You can find information about the different considerations for the development process in Manage Git branches
Release process
The release process starts once new updates are complete and the pull request (PR) merged into the team’s shared branch (such as Main, Dev etc.). From this point, there are different options to build a release process in Fabric.
Option 1 - Git- based deployments
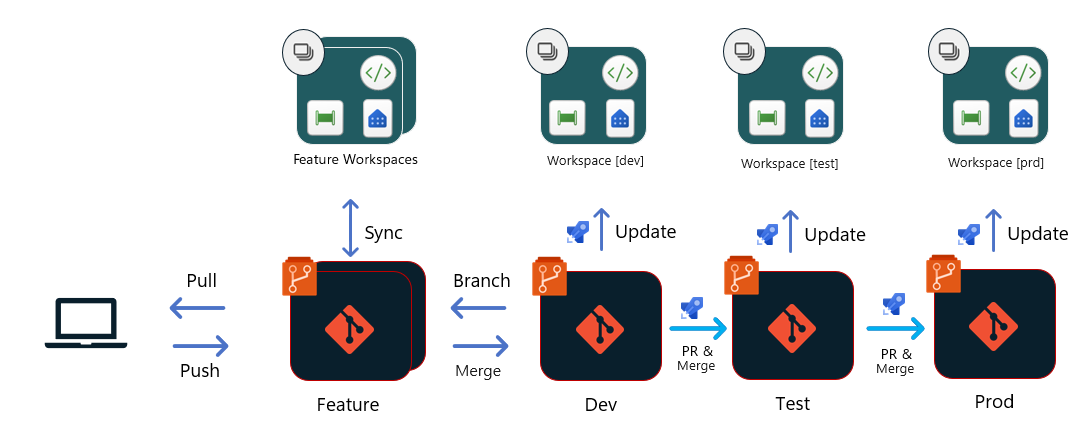
With this option, all deployments originate from the Git repository. Each stage in the release pipeline has a dedicated primary branch (in the diagram, these stages are Dev, Test, and Prod), which feeds the appropriate workspace in Fabric.
Once a PR to the Dev branch is approved and merged:
- A release pipeline is triggered to update the content of the Dev workspace. This process also can include a Build pipeline to run unit tests, but the actual upload of files is done directly from the repo into the workspace, using Fabric Git APIs. You might need to call other Fabric APIs for post-deployment operations that set specific configurations for this workspace, or ingest data.
- A PR is then created to the Test branch. In most cases, the PR is created using a release branch that can cherry pick the content to move into the next stage. The PR should include the same review and approval processes as any other in your team or organization.
- Another Build and release pipeline is triggered to update the Test workspace, using a process similar to the one described in the first step.
- A PR is created to Prod branch, using a process similar to the one described in step #2.
- Another Build and release pipeline is triggered to update the Prod workspace, using a process similar to the one described in the first step.
When should you consider using option #1?
- When you want to use your Git repo as the single source of truth, and the origin of all deployments.
- When your team follows Gitflow as the branching strategy, including multiple primary branches.
- The upload from the repo goes directly into the workspace, as we don’t need build environments to alter the files before deployments. You can change this by calling APIs or running items in the workspace after deployment.
Option 2 - Git- based deployments using Build environments
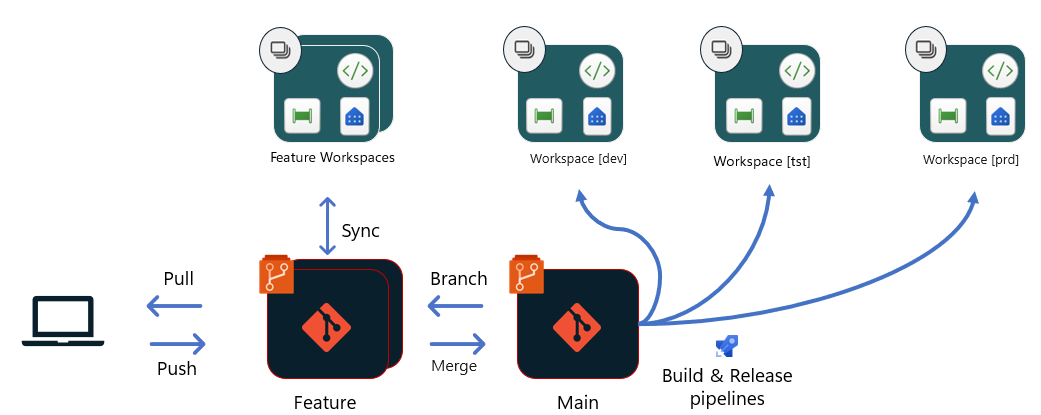
With this option, all deployments originate from the same branch of the Git repository (Main). Each stage in the release pipeline has a dedicated build and Release pipeline. These pipelines might use a Build environment to run unit tests and scripts that change some of the definitions in the items before they're uploaded to the workspace. For example, you might want to change the data source connection, the connections between items in the workspace, or the values of parameters to adjust configuration for the right stage.
Once a PR to the dev branch is approved and merged:
- A build pipeline is triggered to spin up a new Build environment and run unit tests for the dev stage. Then, a release pipeline is triggered to upload the content to a Build environment, run scripts to change some of the configuration, adjust the configuration to dev stage, and use Fabric’s Update item definition APIs to upload the files into the Workspace.
- When this process is complete, including ingesting data and approval from release managers, the next build and release pipelines for test stage can be created. These stages are created in a process similar to that described in the first step. For test stage, other automated or manual tests might be required after the deployment, to validate the changes are ready to be released to Prod stage.
- When all automated and manual tests are complete, the release manager can approve and kick off the build and release pipelines to Prod stage. As the Prod stage usually has different configurations than test/Dev stages, it's important to also test out the changes after the deployment. Also, the deployment should trigger any more ingestion of data, based on the change, to minimize potential non availability to consumers.
When should you consider using option #2?
- When you want to use Git as your single source of truth, and the origin of all deployments.
- When your team follows Trunk-based workflow as its branching strategy.
- You need a build environment (with a custom script) to alter workspace-specific attributes, such as connectionId and lakehouseId, before deployment.
- You need a release pipeline (custom script) to retrieve item content from git and call the corresponding Fabric Item API for creating, updating, or deleting modified Fabric Items.
Option 3 - Deploy using Fabric deployment pipelines
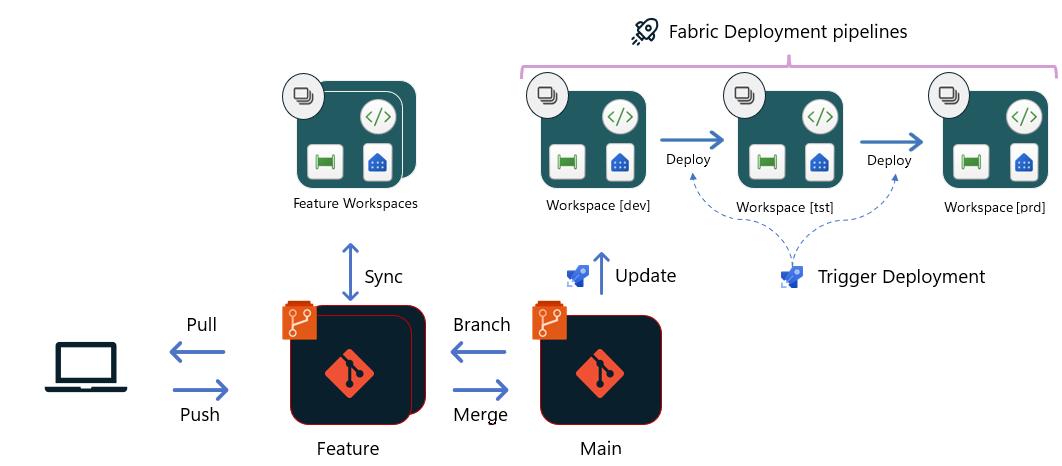
With this option, Git is connected only until the dev stage. From the dev stage, deployments happen directly between the workspaces of Dev/Test/Prod, using Fabric deployment pipelines. While the tool itself is internal to Fabric, developers can use the deployment pipelines APIs to orchestrate the deployment as part of their Azure release pipeline, or a GitHub workflow. These APIs enable the team to build a similar build and release process as in other options, by using automated tests (that can be done in the workspace itself, or before dev stage), approvals etc.
Once the PR to the main branch is approved and merged:
- A build pipeline is triggered that uploads the changes to the dev stage using Fabric Git APIs. If necessary, the pipeline can trigger other APIs to start post-deployment operations/tests in the dev stage.
- After the dev deployment is completed, a release pipeline kicks in to deploy the changes from dev stage to test stage. Automated and manual tests should take place after the deployment, to ensure that the changes are well-tested before reaching production.
- After tests are completed and the release manager approves the deployment to Prod stage, the release to Prod kicks in and completes the deployment.
When should you consider using option #3?
- When you're using source control only for development purposes, and prefer to deploy changes directly between stages of the release pipeline.
- When deployment rules, autobinding and other available APIs are sufficient to manage the configurations between the stages of the release pipeline.
- When you want to use other functionalities of Fabric deployment pipelines, such as viewing changes in Fabric, deployment history etc.
- Consider also that deployments in Fabric deployment pipelines have a linear structure, and require other permissions to create and manage the pipeline.
Option 4 - CI/CD for ISVs in Fabric (managing multiple customers/solutions)
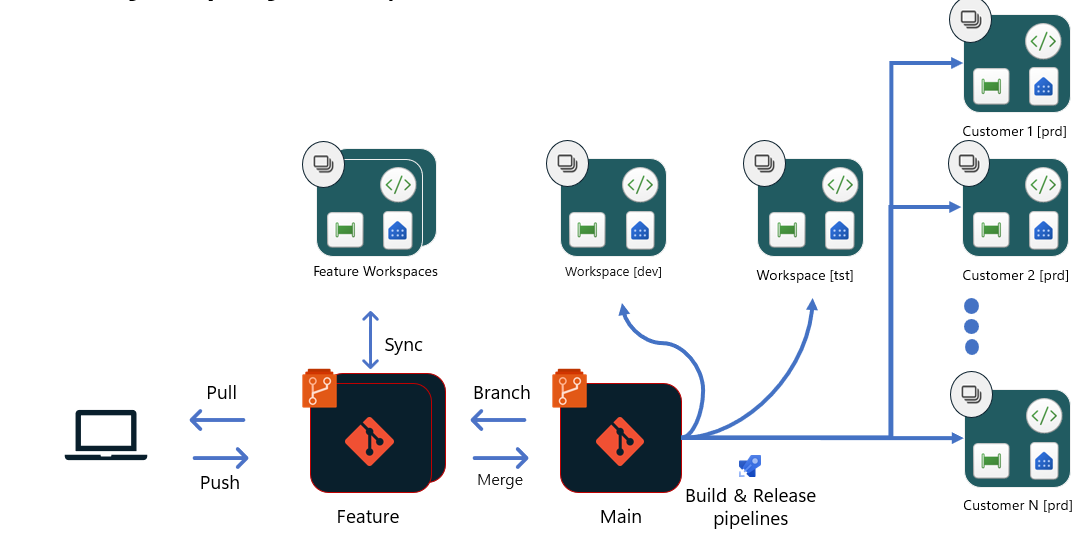
This option is different from the others. It's most relevant for Independent Software Vendors (ISV) who build SaaS applications for their customers on top of Fabric. ISVs usually have a separate workspace for each customer and can have as many as several hundred or thousands of workspaces. When the structure of the analytics provided to each customer is similar and out-of-the-box, we recommend having a centralized development and testing process that splits off to each customer only in the Prod stage.
This option is based on option #2. Once the PR to main is approved and merged:
- A build pipeline is triggered to spin up a new Build environment and run unit tests for dev stage. When tests are complete, a release pipeline is triggered. This pipeline can upload the content to a Build environment, run scripts to change some of the configuration, adjust the configuration to dev stage, and then use Fabric’s Update item definition APIs to upload the files into the Workspace.
- After this process is complete, including ingesting data and approval from release managers, the next build and release pipelines for test stage can kick off. This process is similar to that described in the first step. For test stage, other automated or manual tests might be required after the deployment, to validate the changes are ready to be release to Prod stage in high-quality.
- Once all tests pass and the approval process is complete, the deployment to Prod customers can start. Each customer has its own release with its own parameters, so that its specific configuration and data connection can take place in the relevant customer’s workspace. The configuration change can happen through scripts in a build environment, or using APIs post deployment. All releases can happen in parallel as they aren't related nor dependent of each other.
When should you consider using option #4?
- You're an ISV building applications on top of Fabric.
- You're using different workspaces for each customer to manage the multi-tenancy of your application
- For more separation, or for specific tests for different customers, you might want to have multi-tenancy in earlier stages of dev or test. In that case, consider that with multi-tenancy the number of workspaces required grows significantly.
Summary
This article summarizes the main CI/CD options for a team who wants to build an automated CI/CD process in Fabric. While we outline four options, the real-life constraints and solution architecture might lend themselves to hybrid options, or completely different ones. You can use this article to guide you through different options and how to build them, but you're not forced to choose only one of the options.
Some scenarios or specific items might have limitations in place that can keep you from adopting any of these scenarios.
The same goes for tooling. While we mention different tools here, you might choose other tools that can provide same level of functionality. Consider that Fabric has better integration with some tools, so choosing others result in more limitations that need different workarounds.