Billing and utilization reporting for Apache Spark in Microsoft Fabric
Applies to: ![]() Data Engineering and Data Science in Microsoft Fabric
Data Engineering and Data Science in Microsoft Fabric
This article explains the compute utilization and reporting for ApacheSpark which powers the Synapse Data Engineering and Science workloads in Microsoft Fabric. The compute utilization includes lakehouse operations like table preview, load to delta, notebook runs from the interface, scheduled runs, runs triggered by notebook steps in the pipelines, and Apache Spark job definition runs.
Like other experiences in Microsoft Fabric, Data Engineering also uses the capacity associated with a workspace to run these job and your overall capacity charges appear in the Azure portal under your Microsoft Cost Management subscription. To learn more about Fabric billing, see Understand your Azure bill on a Fabric capacity.
Fabric capacity
You as a user could purchase a Fabric capacity from Azure by specifying using an Azure subscription. The size of the capacity determines the amount of computation power available. For Apache Spark for Fabric, every CU purchased translates to 2 Apache Spark VCores. For example if you purchase a Fabric capacity F128, this translates to 256 SparkVCores. A Fabric capacity is shared across all the workspaces added to it and in which the total Apache Spark compute allowed gets shared across all the jobs submitted from all the workspaces associated to a capacity. To understand about the different SKUs, cores allocation and throttling on Spark, see Concurrency limits and queueing in Apache Spark for Microsoft Fabric.
Spark compute configuration and purchased capacity
Apache Spark compute for Fabric offers two options when it comes to compute configuration.
Starter pools: These default pools are fast and easy way to use Spark on the Microsoft Fabric platform within seconds. You can use Spark sessions right away, instead of waiting for Spark to set up the nodes for you, which helps you do more with data and get insights quicker. When it comes to billing and capacity consumption, you're charged when you start executing your notebook or Spark job definition or lakehouse operation. You aren't charged for the time the clusters are idle in the pool.
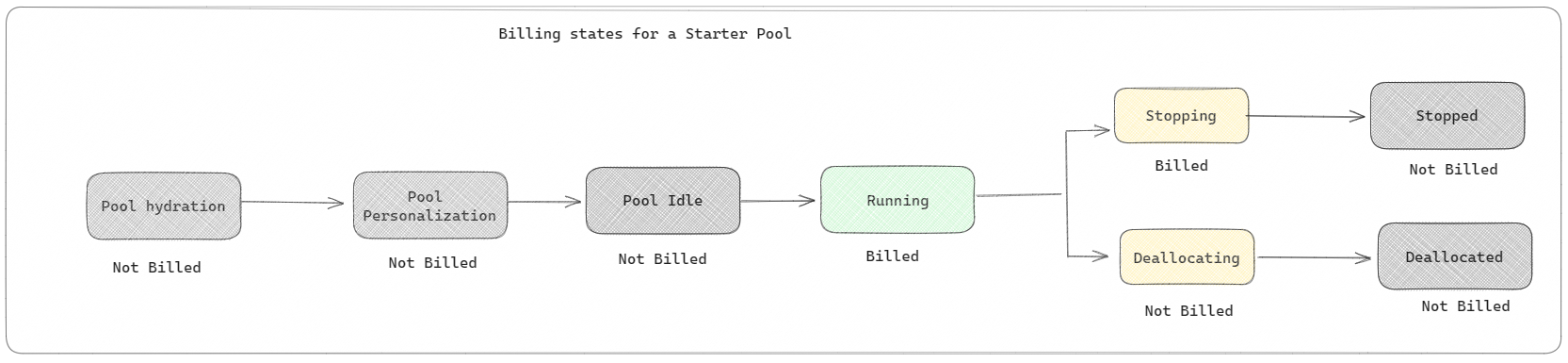
For example, if you submit a notebook job to a starter pool, you're billed only for the time period where the notebook session is active. The billed time doesn't include the idle time or the time taken to personalize the session with the Spark context. To understand more about configuring Starter pools based on the purchased Fabric Capacity SKU, visit Configuring Starter Pools based on Fabric Capacity
Spark pools: These are custom pools, where you get to customize on what size of resources you need for your data analysis tasks. You can give your Spark pool a name, and choose how many and how large the nodes (the machines that do the work) are. You can also tell Spark how to adjust the number of nodes depending on how much work you have. Creating a Spark pool is free; you only pay when you run a Spark job on the pool, and then Spark sets up the nodes for you.
- The size and number of nodes you can have in your custom Spark pool depends on your Microsoft Fabric capacity. You can use these Spark VCores to create nodes of different sizes for your custom Spark pool, as long as the total number of Spark VCores doesn't exceed 128.
- Spark pools are billed like starter pools; you don't pay for the custom Spark pools that you have created unless you have an active Spark session created for running a notebook or Spark job definition. You're only billed for the duration of your job runs. You aren't billed for stages like the cluster creation and deallocation after the job is complete.
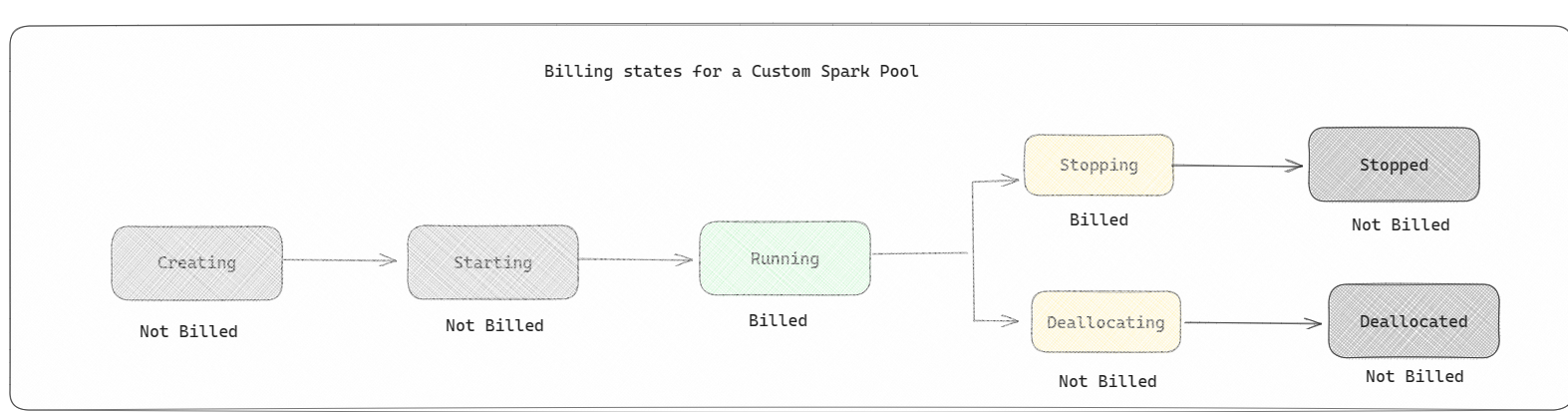
For example, if you submit a notebook job to a custom Spark pool, you're only charged for the time period when the session is active. The billing for that notebook session stops once the Spark session has stopped or expired. You aren't charged for the time taken to acquire cluster instances from the cloud or for the time taken for initializing the Spark context. To understand more about configuring Spark pools based on the purchased Fabric Capacity SKU, visit Configuring Pools based on Fabric Capacity


Note
The default session expiration time period for the Starter Pools and Spark Pools that you create is set to 20 minutes. If you don't use your Spark pool for 2 minutes after your session expires, your Spark pool will be deallocated. To stop the session and the billing after completing your notebook execution before the session expiry time period, you can either click the stop session button from the notebooks Home menu or go to the monitoring hub page and stop the session there.
Spark compute usage reporting
The Microsoft Fabric Capacity Metrics app provides visibility into capacity usage for all Fabric workloads in one place. It's used by capacity administrators to monitor the performance of workloads and their usage, compared to purchased capacity.
Once you have installed the app, select the item type Notebook,Lakehouse,Spark Job Definition from the Select item kind: dropdown list. The Multi metric ribbon chart chart can now be adjusted to a desired timeframe to understand the usage from all these selected items.
All Spark related operations are classified as background operations. Capacity consumption from Spark is displayed under a notebook, a Spark job definition, or a lakehouse, and is aggregated by operation name and item. For example: If you run a notebook job, you can see the notebook run, the CUs used by the notebook (Total Spark VCores/2 as 1 CU gives 2 Spark VCores), duration the job has taken in the report.
 To understand more about Spark capacity usage reporting, see Monitor Apache Spark capacity consumption
To understand more about Spark capacity usage reporting, see Monitor Apache Spark capacity consumption
Billing example
Consider the following scenario:
There is a Capacity C1 which hosts a Fabric Workspace W1 and this Workspace contains Lakehouse LH1 and Notebook NB1.
- Any Spark operation that the notebook(NB1) or lakehouse(LH1) performs is reported against the capacity C1.
Extending this example to a scenario where there is another Capacity C2 which hosts a Fabric Workspace W2 and lets say that this Workspace contains a Spark job definition (SJD1) and Lakehouse (LH2).
- If the Spark Job Definition (SDJ2) from Workspace (W2) reads data from lakehouse (LH1) the usage is reported against the Capacity C2 which is associated with the Workspace (W2) hosting the item.
- If the Notebook (NB1) performs a read operation from Lakehouse(LH2), the capacity consumption is reported against the Capacity C1 which is powering the workspace W1 that hosts the notebook item.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for