Native execution engine for Fabric Spark
The native execution engine is a groundbreaking enhancement for Apache Spark job executions in Microsoft Fabric. This vectorized engine optimizes the performance and efficiency of your Spark queries by running them directly on your lakehouse infrastructure. The engine's seamless integration means it requires no code modifications and avoids vendor lock-in. It supports Apache Spark APIs and is compatible with Runtime 1.2 (Spark 3.4) and Runtime 1.3 (Spark 3.5), and works with both Parquet and Delta formats. Regardless of your data's location within OneLake, or if you access data via shortcuts, the native execution engine maximizes efficiency and performance.
The native execution engine significantly elevates query performance while minimizing operational costs. It delivers a remarkable speed enhancement, achieving up to four times faster performance compared to traditional OSS (open source software) Spark, as validated by the TPC-DS 1TB benchmark. The engine is adept at managing a wide array of data processing scenarios, ranging from routine data ingestion, batch jobs, and ETL (extract, transform, load) tasks, to complex data science analytics and responsive interactive queries. Users benefit from accelerated processing times, heightened throughput, and optimized resource utilization.
The Native Execution Engine is based on two key OSS components: Velox, a C++ database acceleration library introduced by Meta, and Apache Gluten (incubating), a middle layer responsible for offloading JVM-based SQL engines’ execution to native engines introduced by Intel.
Note
The native execution engine is currently in public preview. For more information, see the current limitations. We encourage you to enable the Native Execution Engine on your workloads at no additional cost. You'll benefit from faster job execution without paying more - effectively, you pay less for the same work.
When to use the native execution engine
The native execution engine offers a solution for running queries on large-scale data sets; it optimizes performance by using the native capabilities of underlying data sources and minimizing the overhead typically associated with data movement and serialization in traditional Spark environments. The engine supports various operators and data types, including rollup hash aggregate, broadcast nested loop join (BNLJ), and precise timestamp formats. However, to fully benefit from the engine's capabilities, you should consider its optimal use cases:
- The engine is effective when working with data in Parquet and Delta formats, which it can process natively and efficiently.
- Queries that involve intricate transformations and aggregations benefit significantly from the columnar processing and vectorization capabilities of the engine.
- Performance enhancement is most notable in scenarios where the queries don't trigger the fallback mechanism by avoiding unsupported features or expressions.
- The engine is well-suited for queries that are computationally intensive, rather than simple or I/O-bound.
For information on the operators and functions supported by the native execution engine, see Apache Gluten documentation.
Enable the native execution engine
To use the full capabilities of the native execution engine during the preview phase, specific configurations are necessary. The following procedures show how to activate this feature for notebooks, Spark job definitions, and entire environments.
Important
The native execution engine supports the latest GA runtime version, which is Runtime 1.3 (Apache Spark 3.5, Delta Lake 3.2) and the older version - Runtime 1.2 (Apache Spark 3.4, Delta Lake 2.4).
Enable at the environment level
To ensure uniform performance enhancement, enable the native execution engine across all jobs and notebooks associated with your environment:
Navigate to your environment settings.
Go to Spark compute.
Go to Acceleration Tab.
Check the box labeled Enable native execution engine.
Save and Publish the changes.
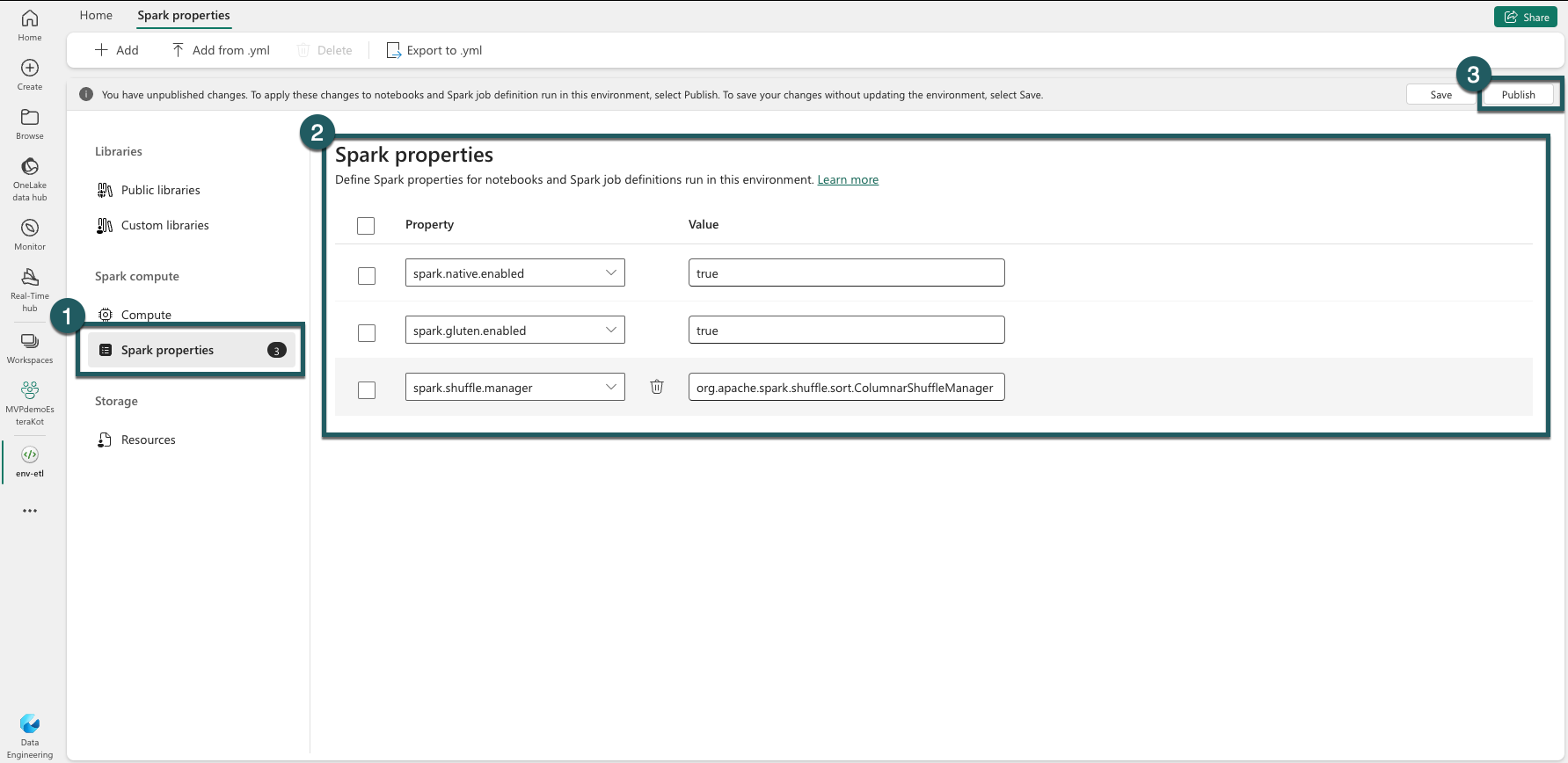

When enabled at the environment level, all subsequent jobs and notebooks inherit the setting. This inheritance ensures that any new sessions or resources created in the environment automatically benefit from the enhanced execution capabilities.
Enable for a notebook or Spark job definition
To enable the native execution engine for a single notebook or Spark job definition, you must incorporate the necessary configurations at the beginning of your execution script:
%%configure
{
"conf": {
"spark.native.enabled": "true",
"spark.shuffle.manager": "org.apache.spark.shuffle.sort.ColumnarShuffleManager"
}
}
For notebooks, insert the required configuration commands in the first cell. For Spark job definitions, include the configurations in the frontline of your Spark job definition.

The Native Execution Engine is integrated with live pools, so once you enable the feature, it takes effect immediately without requiring you to initiate a new session.
Important
Configuration of the native execution engine must be done prior to the initiation of the Spark session. After the Spark session starts, the spark.shuffle.manager setting becomes immutable and can't be changed. Ensure that these configurations are set within the %%configure block in notebooks or in the Spark session builder for Spark job definitions.
Control on the query level
The mechanisms to enable the Native Execution Engine at the tenant, workspace, and environment levels, seamlessly integrated with the UI, are under active development. In the meantime, you can disable the native execution engine for specific queries, particularly if they involve operators that aren't currently supported (see limitations). To disable, set the Spark configuration spark.native.enabled to false for the specific cell containing your query.
%%sql
SET spark.native.enabled=FALSE;

After executing the query in which the native execution engine is disabled, you must re-enable it for subsequent cells by setting spark.native.enabled to true. This step is necessary because Spark executes code cells sequentially.
%%sql
SET spark.native.enabled=TRUE;
Identify operations executed by the engine
There are several methods to determine if an operator in your Apache Spark job was processed using the native execution engine.
Spark UI and Spark history server
Access the Spark UI or Spark history server to locate the query you need to inspect. In the query plan displayed within the interface, look for any node names that end with the suffix Transformer, NativeFileScan or VeloxColumnarToRowExec. The suffix indicates that the native execution engine executed the operation. For instance, nodes might be labeled as RollUpHashAggregateTransformer, ProjectExecTransformer, BroadcastHashJoinExecTransformer, ShuffledHashJoinExecTransformer, or BroadcastNestedLoopJoinExecTransformer.

DataFrame explain
Alternatively, you can execute the df.explain() command in your notebook to view the execution plan. Within the output, look for the same Transformer, NativeFileScan or VeloxColumnarToRowExec suffixes. This method provides a quick way to confirm whether specific operations are being handled by the native execution engine.

Fallback mechanism
In some instances, the native execution engine might not be able to execute a query due to reasons such as unsupported features. In these cases, the operation falls back to the traditional Spark engine. This fallback mechanism ensures that there's no interruption to your workflow.


Monitor Queries and DataFrames executed by the engine
To better understand how the Native Execution engine is applied to SQL queries and DataFrame operations, and to drill down to the stage and operator levels, you can refer to the Spark UI and Spark History Server for more detailed information about the native engine execution.
Native Execution Engine Tab
You can navigate to the new 'Gluten SQL / DataFrame' tab to view the Gluten build information and query execution details. The Queries table provides insights into the number of nodes running on the Native engine and those falling back to the JVM for each query.

Query Execution Graph
You can also click on the query description for the Apache Spark query execution plan visualization. The execution graph provides native execution details across stages and their respective operations. Background colors differentiate the execution engines: green represents the Native Execution Engine, while light blue indicates that the operation is running on the default JVM Engine.

Limitations
While the native execution engine enhances performance for Apache Spark jobs, note its current limitations.
- Some Delta-specific operations aren't supported (yet), including merge operations, checkpoint scans, and deletion vectors.
- Certain Spark features and expressions aren't compatible with the native execution engine, such as user-defined functions (UDFs) and the
array_containsfunction, as well as Spark structured streaming. Usage of these incompatible operations or functions as part of an imported library will also cause fallback to the Spark engine. - Scans from storage solutions that utilize private endpoints aren't supported.
- The engine doesn't support ANSI mode, so it searches, and once ANSI mode is enabled, it falls back to vanilla Spark.
When using date filters in queries, it is essential to ensure that the data types on both sides of the comparison match to avoid performance issues. Mismatched data types may not bring query execution boost and may require explicit casting. Always ensure that the data types of the left-hand side (LHS) and right-hand side (RHS) of a comparison are identical, as mismatched types will not always be automatically cast. If a type mismatch is unavoidable, use explicit casting to match the data types, such as CAST(order_date AS DATE) = '2024-05-20'. Queries with mismatched data types that require casting will not be accelerated by Native Execution Engine, so ensuring type consistency is crucial for maintaining performance. For example, instead of order_date = '2024-05-20' where order_date is DATETIME and the string is DATE, explicitly cast order_date to DATE to ensure consistent data types and improve performance.
Note
The native execution engine is currently in preview and your insights are important to us. We invite you to share your feedback and the outcomes of your evaluation directly with our product team. Please fill out the feedback form. We look forward to your valuable input and are eager to discuss your findings in detail.