Transform data by running an Azure Databricks activity
The Azure Databricks activity in Data Factory for Microsoft Fabric allows you to orchestrate the following Azure Databricks jobs:
- Notebook
- Jar
- Python
This article provides a step-by-step walkthrough that describes how to create an Azure Databricks activity using the Data Factory interface.
Prerequisites
To get started, you must complete the following prerequisites:
- A tenant account with an active subscription. Create an account for free.
- A workspace is created.
Configuring an Azure Databricks activity
To use an Azure Databricks activity in a pipeline, complete the following steps:
Configuring connection
Create a new pipeline in your workspace.
Click on add a pipeline activity and search for Azure Databricks.
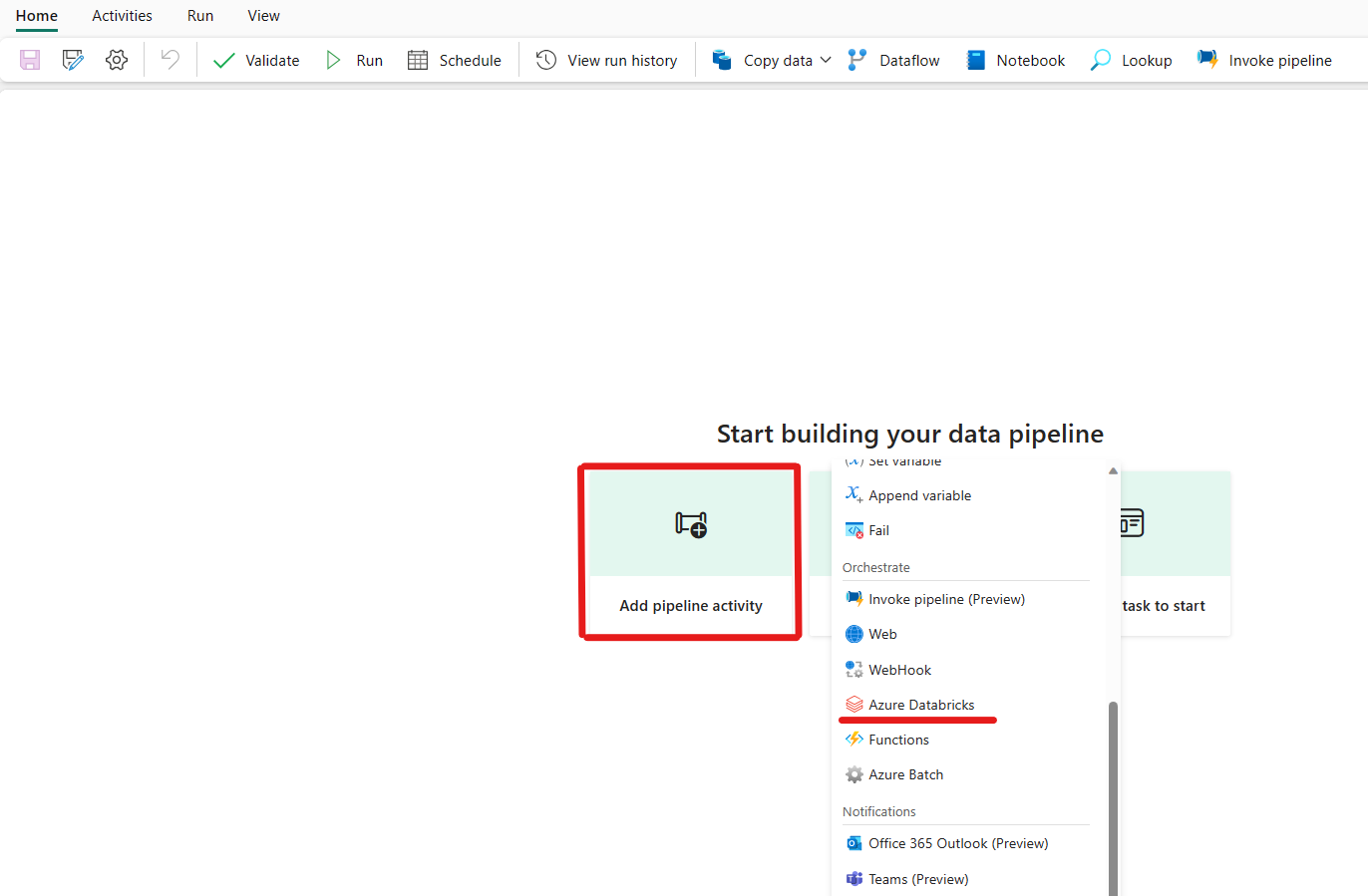
Alternately, you can search for Azure Databricks in the pipeline Activities pane, and select it to add it to the pipeline canvas.
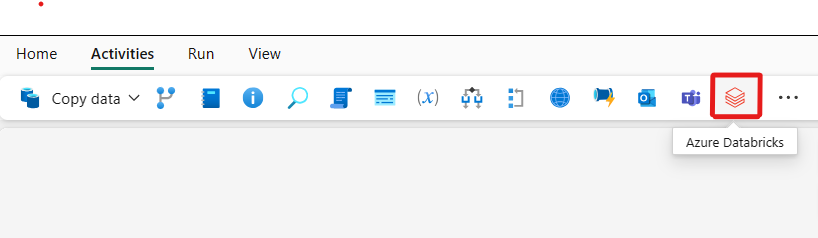
Select the new Azure Databricks activity on the canvas if it isn’t already selected.
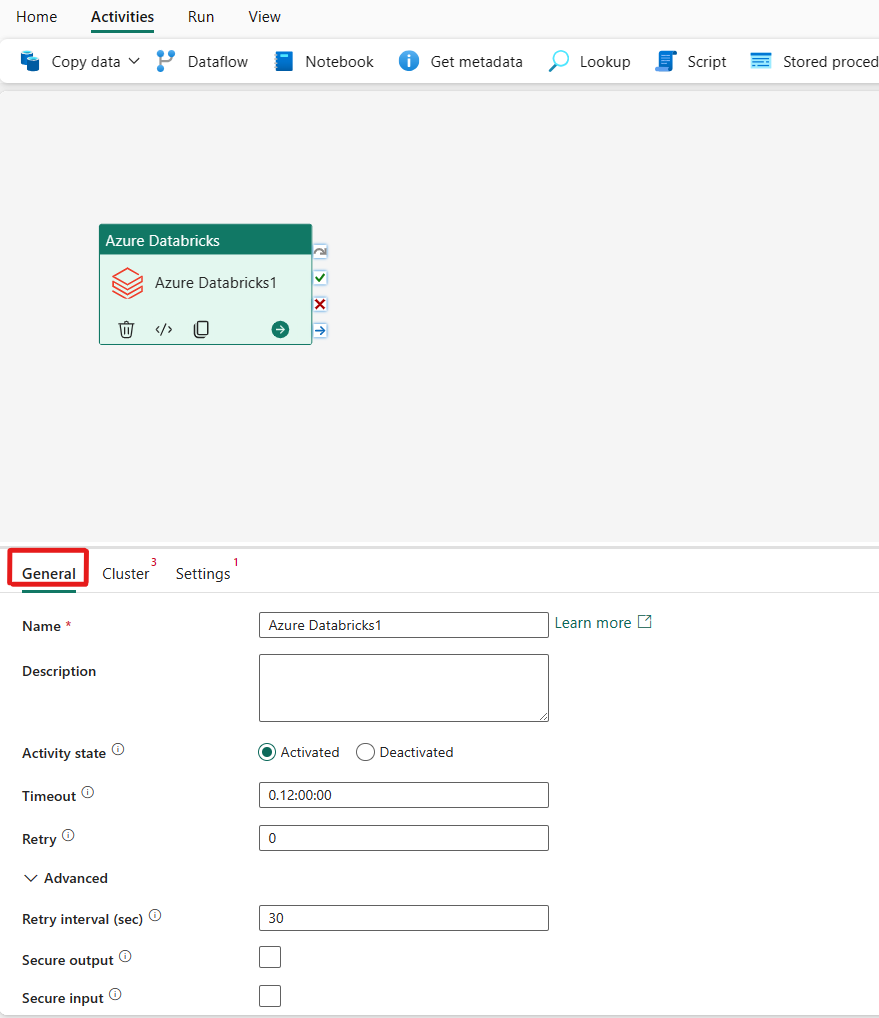
Refer to the General settings guidance to configure the General settings tab.
Configuring clusters
Select the Cluster tab. Then you can choose an existing or create a new Azure Databricks connection, and then pick a new job cluster, an existing interactive cluster, or an existing instance pool.
Depending on what you pick for the cluster, fill out the corresponding fields as presented.
- Under new job cluster and existing instance pool, you also have the ability to configure the number of workers and enable spot instances.
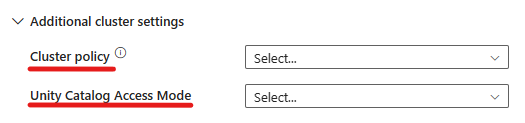
You can also specify additional cluster settings, such as Cluster policy, Spark configuration, Spark environment variables, and custom tags, as required for the cluster you are connecting to. Databricks init scripts and Cluster Log destination path can also be added under the additional cluster settings.
Note
All advanced cluster properties and dynamic expressions supported in the Azure Data Factory Azure Databricks linked service are now also supported in the Azure Databricks activity in Microsoft Fabric under the ‘Additional cluster configuration’ section in the UI. As these properties are now included within the activity UI; they can be easily used with an expression (dynamic content) without the need for the Advanced JSON specification in the Azure Data Factory Azure Databricks linked service.
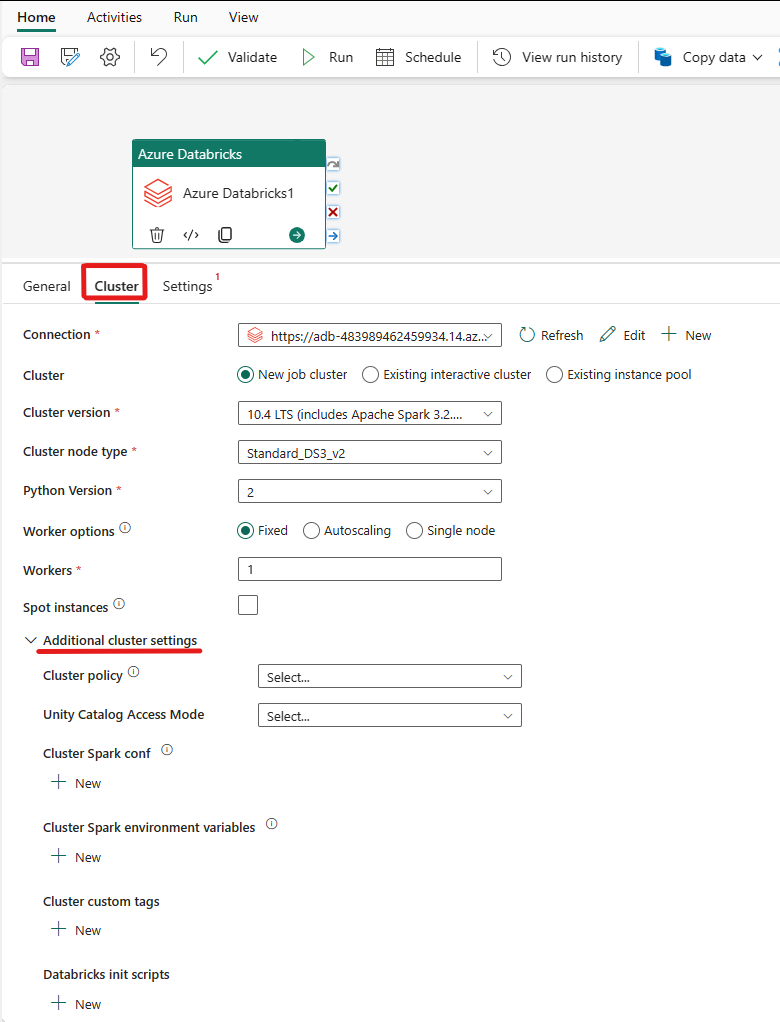
The Azure Databricks Activity now also supports Cluster Policy and Unity Catalog support.
- Under advanced settings, you have the option to choose the Cluster Policy so you can specify which cluster configurations are permitted.
- Also, under advanced settings, you have the option to configure the Unity Catalog Access Mode for added security. The available access mode types are:
- Single User Access Mode This mode is designed for scenarios where each cluster is used by a single user. It ensures that the data access within the cluster is restricted to that user only. This mode is useful for tasks that require isolation and individual data handling.
- Shared Access Mode In this mode, multiple users can access the same cluster. It combines Unity Catalog's data governance with the legacy table access control lists (ACLs). This mode allows for collaborative data access while maintaining governance and security protocols. However, it has certain limitations, such as not supporting Databricks Runtime ML, Spark-submit jobs, and specific Spark APIs and UDFs.
- No Access Mode This mode disables interaction with the Unity Catalog, meaning clusters do not have access to data managed by Unity Catalog. This mode is useful for workloads that do not require Unity Catalog’s governance features.
Configuring settings
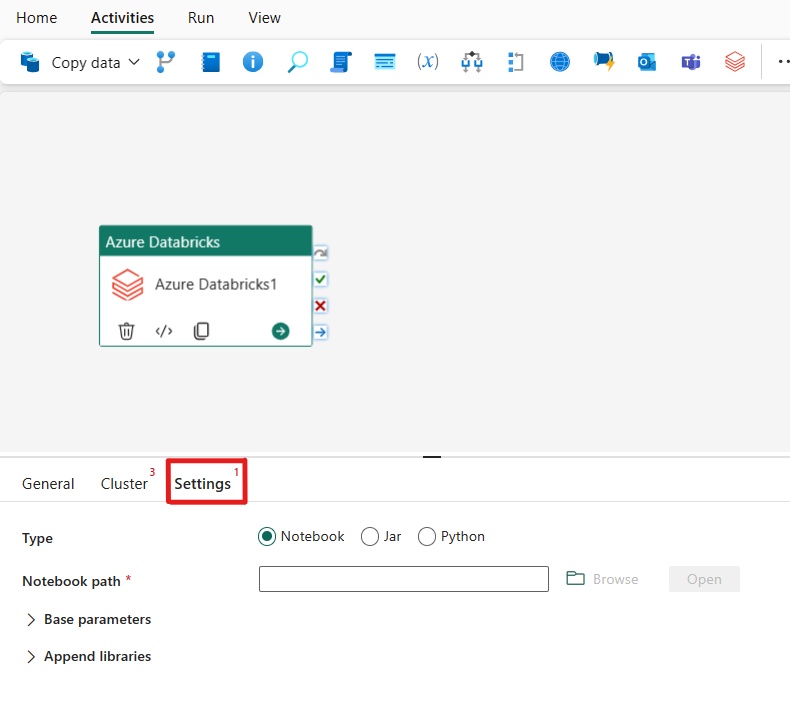
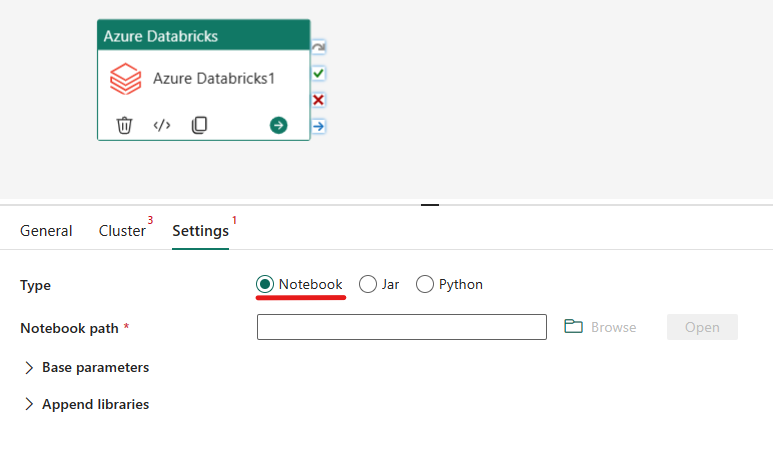
Selecting the Settings tab, you can choose between 3 options which Azure Databricks type you would like to orchestrate.
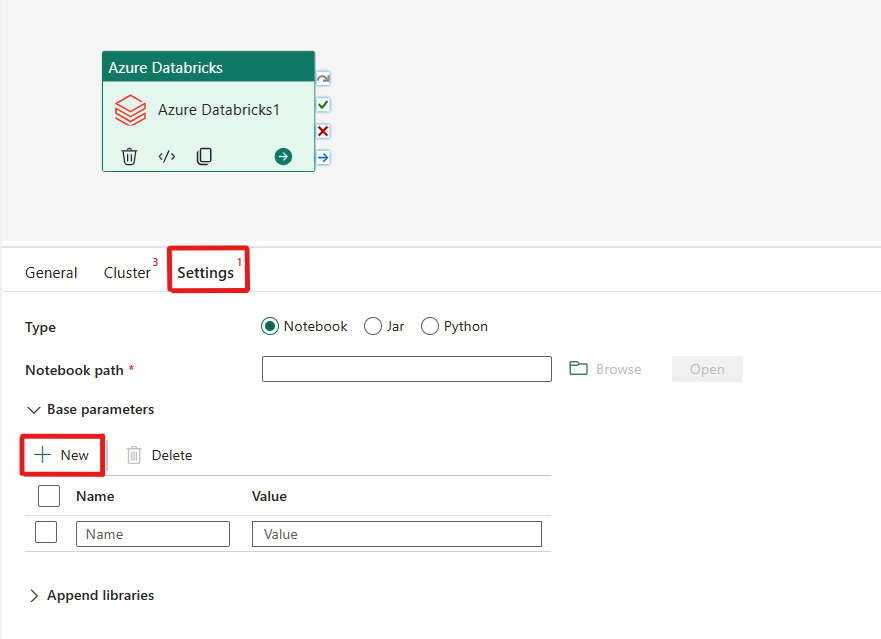
Orchestrating the Notebook type in Azure Databricks activity:
Under the Settings tab, you can choose the Notebook radio button to run a Notebook. You will need to specify the notebook path to be executed on Azure Databricks, optional base parameters to be passed to the notebook, and any additional libraries to be installed on the cluster to execute the job.
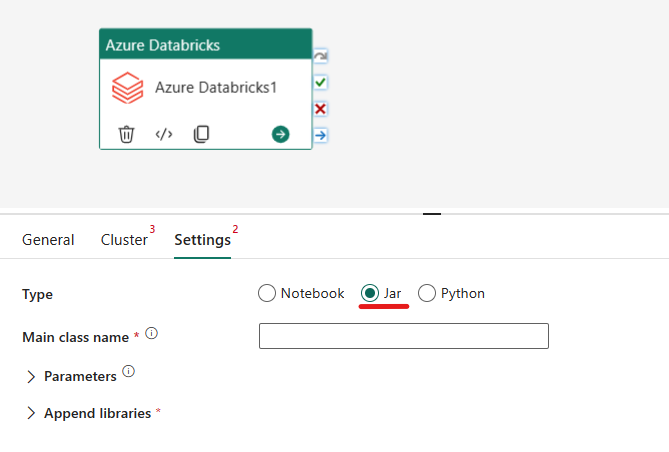
Orchestrating the Jar type in Azure Databricks activity:
Under the Settings tab, you can choose the Jar radio button to run a Jar. You will need to specify the class name to be executed on Azure Databricks, optional base parameters to be passed to the Jar, and any additional libraries to be installed on the cluster to execute the job.
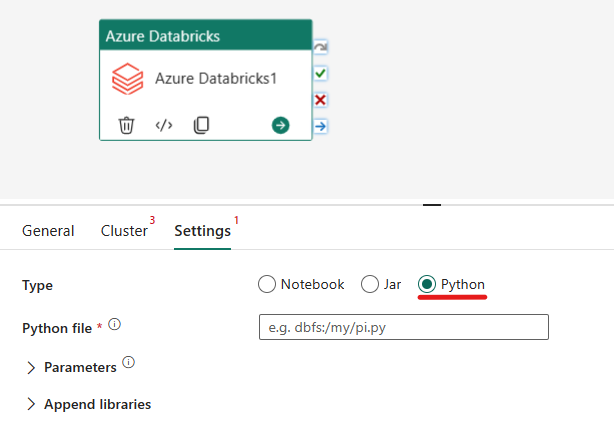
Orchestrating the Python type in Azure Databricks activity:
Under the Settings tab, you can choose the Python radio button to run a Python file. You will need to specify the path within Azure Databricks to a Python file to be executed, optional base parameters to be passed, and any additional libraries to be installed on the cluster to execute the job.
Supported Libraries for the Azure Databricks activity
In the above Databricks activity definition, you can specify these library types: jar, egg, whl, maven, pypi, cran.
For more information, see the Databricks documentation for library types.
Passing parameters between Azure Databricks activity and pipelines
You can pass parameters to notebooks using baseParameters property in databricks activity.
In certain cases, you might require to pass back certain values from notebook back to the service, which can be used for control flow (conditional checks) in the service or be consumed by downstream activities (size limit is 2 MB).
In your notebook, for example, you may call dbutils.notebook.exit("returnValue") and corresponding "returnValue" will be returned to the service.
You can consume the output in the service by using expression such as
@{activity('databricks activity name').output.runOutput}.
Save and run or schedule the pipeline
After you configure any other activities required for your pipeline, switch to the Home tab at the top of the pipeline editor, and select the save button to save your pipeline. Select Run to run it directly, or Schedule to schedule it. You can also view the run history here or configure other settings.

Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for