Guide to Net# neural network specification language for Machine Learning Studio (classic)
APPLIES TO:  Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Important
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
Beginning 1 December 2021, you will not be able to create new Machine Learning Studio (classic) resources. Through 31 August 2024, you can continue to use the existing Machine Learning Studio (classic) resources.
- See information on moving machine learning projects from ML Studio (classic) to Azure Machine Learning.
- Learn more about Azure Machine Learning
ML Studio (classic) documentation is being retired and may not be updated in the future.
Net# is a language developed by Microsoft that is used to define complex neural network architectures such as deep neural networks or convolutions of arbitrary dimensions. You can use complex structures to improve learning on data such as image, video, or audio.
You can use a Net# architecture specification in all neural network modules in Machine Learning Studio (classic):
This article describes the basic concepts and syntax needed to develop a custom neural network using Net#:
- Neural network requirements and how to define the primary components
- The syntax and keywords of the Net# specification language
- Examples of custom neural networks created using Net#
Neural network basics
A neural network structure consists of nodes that are organized in layers, and weighted connections (or edges) between the nodes. The connections are directional, and each connection has a source node and a destination node.
Each trainable layer (a hidden or an output layer) has one or more connection bundles. A connection bundle consists of a source layer and a specification of the connections from that source layer. All the connections in a given bundle share source and destination layers. In Net#, a connection bundle is considered as belonging to the bundle's destination layer.
Net# supports various kinds of connection bundles, which let you customize the way inputs are mapped to hidden layers and mapped to the outputs.
The default or standard bundle is a full bundle, in which each node in the source layer is connected to every node in the destination layer.
Additionally, Net# supports the following four kinds of advanced connection bundles:
Filtered bundles. You can define a predicate by using the locations of the source layer node and the destination layer node. Nodes are connected whenever the predicate is True.
Convolutional bundles. You can define small neighborhoods of nodes in the source layer. Each node in the destination layer is connected to one neighborhood of nodes in the source layer.
Pooling bundles and Response normalization bundles. These are similar to convolutional bundles in that the user defines small neighborhoods of nodes in the source layer. The difference is that the weights of the edges in these bundles are not trainable. Instead, a predefined function is applied to the source node values to determine the destination node value.
Supported customizations
The architecture of neural network models that you create in Machine Learning Studio (classic) can be extensively customized by using Net#. You can:
- Create hidden layers and control the number of nodes in each layer.
- Specify how layers are to be connected to each other.
- Define special connectivity structures, such as convolutions and weight sharing bundles.
- Specify different activation functions.
For details of the specification language syntax, see Structure Specification.
For examples of defining neural networks for some common machine learning tasks, from simplex to complex, see Examples.
General requirements
- There must be exactly one output layer, at least one input layer, and zero or more hidden layers.
- Each layer has a fixed number of nodes, conceptually arranged in a rectangular array of arbitrary dimensions.
- Input layers have no associated trained parameters and represent the point where instance data enters the network.
- Trainable layers (the hidden and output layers) have associated trained parameters, known as weights and biases.
- The source and destination nodes must be in separate layers.
- Connections must be acyclic; in other words, there cannot be a chain of connections leading back to the initial source node.
- The output layer cannot be a source layer of a connection bundle.
Structure specifications
A neural network structure specification is composed of three sections: the constant declaration, the layer declaration, the connection declaration. There is also an optional share declaration section. The sections can be specified in any order.
Constant declaration
A constant declaration is optional. It provides a means to define values used elsewhere in the neural network definition. The declaration statement consists of an identifier followed by an equal sign and a value expression.
For example, the following statement defines a constant x:
Const X = 28;
To define two or more constants simultaneously, enclose the identifier names and values in braces, and separate them by using semicolons. For example:
Const { X = 28; Y = 4; }
The right-hand side of each assignment expression can be an integer, a real number, a Boolean value (True or False), or a mathematical expression. For example:
Const { X = 17 * 2; Y = true; }
Layer declaration
The layer declaration is required. It defines the size and source of the layer, including its connection bundles and attributes. The declaration statement starts with the name of the layer (input, hidden, or output), followed by the dimensions of the layer (a tuple of positive integers). For example:
input Data auto;
hidden Hidden[5,20] from Data all;
output Result[2] from Hidden all;
- The product of the dimensions is the number of nodes in the layer. In this example, there are two dimensions [5,20], which means there are 100 nodes in the layer.
- The layers can be declared in any order, with one exception: If more than one input layer is defined, the order in which they are declared must match the order of features in the input data.
To specify that the number of nodes in a layer be determined automatically, use the auto keyword. The auto keyword has different effects, depending on the layer:
- In an input layer declaration, the number of nodes is the number of features in the input data.
- In a hidden layer declaration, the number of nodes is the number that is specified by the parameter value for Number of hidden nodes.
- In an output layer declaration, the number of nodes is 2 for two-class classification, 1 for regression, and equal to the number of output nodes for multiclass classification.
For example, the following network definition allows the size of all layers to be automatically determined:
input Data auto;
hidden Hidden auto from Data all;
output Result auto from Hidden all;
A layer declaration for a trainable layer (the hidden or output layers) can optionally include the output function (also called an activation function), which defaults to sigmoid for classification models, and linear for regression models. Even if you use the default, you can explicitly state the activation function, if desired for clarity.
The following output functions are supported:
- sigmoid
- linear
- softmax
- rlinear
- square
- sqrt
- srlinear
- abs
- tanh
- brlinear
For example, the following declaration uses the softmax function:
output Result [100] softmax from Hidden all;
Connection declaration
Immediately after defining the trainable layer, you must declare connections among the layers you have defined. The connection bundle declaration starts with the keyword from, followed by the name of the bundle's source layer and the kind of connection bundle to create.
Currently, five kinds of connection bundles are supported:
- Full bundles, indicated by the keyword
all - Filtered bundles, indicated by the keyword
where, followed by a predicate expression - Convolutional bundles, indicated by the keyword
convolve, followed by the convolution attributes - Pooling bundles, indicated by the keywords max pool or mean pool
- Response normalization bundles, indicated by the keyword response norm
Full bundles
A full connection bundle includes a connection from each node in the source layer to each node in the destination layer. This is the default network connection type.
Filtered bundles
A filtered connection bundle specification includes a predicate, expressed syntactically, much like a C# lambda expression. The following example defines two filtered bundles:
input Pixels [10, 20];
hidden ByRow[10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol[5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
In the predicate for
ByRow,sis a parameter representing an index into the rectangular array of nodes of the input layer,Pixels, anddis a parameter representing an index into the array of nodes of the hidden layer,ByRow. The type of bothsanddis a tuple of integers of length two. Conceptually,sranges over all pairs of integers with0 <= s[0] < 10and0 <= s[1] < 20, anddranges over all pairs of integers, with0 <= d[0] < 10and0 <= d[1] < 12.On the right-hand side of the predicate expression, there is a condition. In this example, for every value of
sanddsuch that the condition is True, there is an edge from the source layer node to the destination layer node. Thus, this filter expression indicates that the bundle includes a connection from the node defined bysto the node defined bydin all cases where s[0] is equal to d[0].
Optionally, you can specify a set of weights for a filtered bundle. The value for the Weights attribute must be a tuple of floating point values with a length that matches the number of connections defined by the bundle. By default, weights are randomly generated.
Weight values are grouped by the destination node index. That is, if the first destination node is connected to K source nodes, the first K elements of the Weights tuple are the weights for the first destination node, in source index order. The same applies for the remaining destination nodes.
It's possible to specify weights directly as constant values. For example, if you learned the weights previously, you can specify them as constants using this syntax:
const Weights_1 = [0.0188045055, 0.130500451, ...]
Convolutional bundles
When the training data has a homogeneous structure, convolutional connections are commonly used to learn high-level features of the data. For example, in image, audio, or video data, spatial or temporal dimensionality can be fairly uniform.
Convolutional bundles employ rectangular kernels that are slid through the dimensions. Essentially, each kernel defines a set of weights applied in local neighborhoods, referred to as kernel applications. Each kernel application corresponds to a node in the source layer, which is referred to as the central node. The weights of a kernel are shared among many connections. In a convolutional bundle, each kernel is rectangular and all kernel applications are the same size.
Convolutional bundles support the following attributes:
InputShape defines the dimensionality of the source layer for the purposes of this convolutional bundle. The value must be a tuple of positive integers. The product of the integers must equal the number of nodes in the source layer, but otherwise, it does not need to match the dimensionality declared for the source layer. The length of this tuple becomes the arity value for the convolutional bundle. Typically arity refers to the number of arguments or operands that a function can take.
To define the shape and locations of the kernels, use the attributes KernelShape, Stride, Padding, LowerPad, and UpperPad:
KernelShape: (required) Defines the dimensionality of each kernel for the convolutional bundle. The value must be a tuple of positive integers with a length that equals the arity of the bundle. Each component of this tuple must be no greater than the corresponding component of InputShape.
Stride: (optional) Defines the sliding step sizes of the convolution (one step size for each dimension), that is the distance between the central nodes. The value must be a tuple of positive integers with a length that is the arity of the bundle. Each component of this tuple must be no greater than the corresponding component of KernelShape. The default value is a tuple with all components equal to one.
Sharing: (optional) Defines the weight sharing for each dimension of the convolution. The value can be a single Boolean value or a tuple of Boolean values with a length that is the arity of the bundle. A single Boolean value is extended to be a tuple of the correct length with all components equal to the specified value. The default value is a tuple that consists of all True values.
MapCount: (optional) Defines the number of feature maps for the convolutional bundle. The value can be a single positive integer or a tuple of positive integers with a length that is the arity of the bundle. A single integer value is extended to be a tuple of the correct length with the first components equal to the specified value and all the remaining components equal to one. The default value is one. The total number of feature maps is the product of the components of the tuple. The factoring of this total number across the components determines how the feature map values are grouped in the destination nodes.
Weights: (optional) Defines the initial weights for the bundle. The value must be a tuple of floating point values with a length that is the number of kernels times the number of weights per kernel, as defined later in this article. The default weights are randomly generated.
There are two sets of properties that control padding, the properties being mutually exclusive:
Padding: (optional) Determines whether the input should be padded by using a default padding scheme. The value can be a single Boolean value, or it can be a tuple of Boolean values with a length that is the arity of the bundle.
A single Boolean value is extended to be a tuple of the correct length with all components equal to the specified value.
If the value for a dimension is True, the source is logically padded in that dimension with zero-valued cells to support additional kernel applications, such that the central nodes of the first and last kernels in that dimension are the first and last nodes in that dimension in the source layer. Thus, the number of "dummy" nodes in each dimension is determined automatically, to fit exactly
(InputShape[d] - 1) / Stride[d] + 1kernels into the padded source layer.If the value for a dimension is False, the kernels are defined so that the number of nodes on each side that are left out is the same (up to a difference of 1). The default value of this attribute is a tuple with all components equal to False.
UpperPad and LowerPad: (optional) Provide greater control over the amount of padding to use. Important: These attributes can be defined if and only if the Padding property above is not defined. The values should be integer-valued tuples with lengths that are the arity of the bundle. When these attributes are specified, "dummy" nodes are added to the lower and upper ends of each dimension of the input layer. The number of nodes added to the lower and upper ends in each dimension is determined by LowerPad[i] and UpperPad[i] respectively.
To ensure that kernels correspond only to "real" nodes and not to "dummy" nodes, the following conditions must be met:
Each component of LowerPad must be strictly less than
KernelShape[d]/2.Each component of UpperPad must be no greater than
KernelShape[d]/2.The default value of these attributes is a tuple with all components equal to 0.
The setting Padding = true allows as much padding as is needed to keep the "center" of the kernel inside the "real" input. This changes the math a bit for computing the output size. Generally, the output size D is computed as
D = (I - K) / S + 1, whereIis the input size,Kis the kernel size,Sis the stride, and/is integer division (round toward zero). If you set UpperPad = [1, 1], the input sizeIis effectively 29, and thusD = (29 - 5) / 2 + 1 = 13. However, when Padding = true, essentiallyIgets bumped up byK - 1; henceD = ((28 + 4) - 5) / 2 + 1 = 27 / 2 + 1 = 13 + 1 = 14. By specifying values for UpperPad and LowerPad you get much more control over the padding than if you just set Padding = true.
For more information about convolutional networks and their applications, see these articles:
- http://d2l.ai/chapter_convolutional-neural-networks/lenet.html
- https://research.microsoft.com/pubs/68920/icdar03.pdf
Pooling bundles
A pooling bundle applies geometry similar to convolutional connectivity, but it uses predefined functions to source node values to derive the destination node value. Hence, pooling bundles have no trainable state (weights or biases). Pooling bundles support all the convolutional attributes except Sharing, MapCount, and Weights.
Typically, the kernels summarized by adjacent pooling units do not overlap. If Stride[d] is equal to KernelShape[d] in each dimension, the layer obtained is the traditional local pooling layer, which is commonly employed in convolutional neural networks. Each destination node computes the maximum or the mean of the activities of its kernel in the source layer.
The following example illustrates a pooling bundle:
hidden P1 [5, 12, 12]
from C1 max pool {
InputShape = [ 5, 24, 24];
KernelShape = [ 1, 2, 2];
Stride = [ 1, 2, 2];
}
- The arity of the bundle is 3: that is, the length of the tuples
InputShape,KernelShape, andStride. - The number of nodes in the source layer is
5 * 24 * 24 = 2880. - This is a traditional local pooling layer because KernelShape and Stride are equal.
- The number of nodes in the destination layer is
5 * 12 * 12 = 1440.
For more information about pooling layers, see these articles:
- https://www.cs.toronto.edu/~hinton/absps/imagenet.pdf (Section 3.4)
- https://cs.nyu.edu/~koray/publis/lecun-iscas-10.pdf
- https://cs.nyu.edu/~koray/publis/jarrett-iccv-09.pdf
Response normalization bundles
Response normalization is a local normalization scheme that was first introduced by Geoffrey Hinton, et al, in the paper ImageNet Classification with Deep Convolutional Neural Networks.
Response normalization is used to aid generalization in neural nets. When one neuron is firing at a very high activation level, a local response normalization layer suppresses the activation level of the surrounding neurons. This is done by using three parameters (α, β, and k) and a convolutional structure (or neighborhood shape). Every neuron in the destination layer y corresponds to a neuron x in the source layer. The activation level of y is given by the following formula, where f is the activation level of a neuron, and Nx is the kernel (or the set that contains the neurons in the neighborhood of x), as defined by the following convolutional structure:
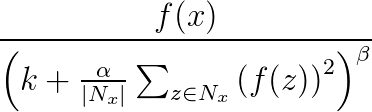
Response normalization bundles support all the convolutional attributes except Sharing, MapCount, and Weights.
If the kernel contains neurons in the same map as x, the normalization scheme is referred to as same map normalization. To define same map normalization, the first coordinate in InputShape must have the value 1.
If the kernel contains neurons in the same spatial position as x, but the neurons are in other maps, the normalization scheme is called across maps normalization. This type of response normalization implements a form of lateral inhibition inspired by the type found in real neurons, creating competition for big activation levels amongst neuron outputs computed on different maps. To define across maps normalization, the first coordinate must be an integer greater than one and no greater than the number of maps, and the rest of the coordinates must have the value 1.
Because response normalization bundles apply a predefined function to source node values to determine the destination node value, they have no trainable state (weights or biases).
Note
The nodes in the destination layer correspond to neurons that are the central nodes of the kernels. For example, if KernelShape[d] is odd, then KernelShape[d]/2 corresponds to the central kernel node. If KernelShape[d] is even, the central node is at KernelShape[d]/2 - 1. Therefore, if Padding[d] is False, the first and the last KernelShape[d]/2 nodes do not have corresponding nodes in the destination layer. To avoid this situation, define Padding as [true, true, …, true].
In addition to the four attributes described earlier, response normalization bundles also support the following attributes:
- Alpha: (required) Specifies a floating-point value that corresponds to
αin the previous formula. - Beta: (required) Specifies a floating-point value that corresponds to
βin the previous formula. - Offset: (optional) Specifies a floating-point value that corresponds to
kin the previous formula. It defaults to 1.
The following example defines a response normalization bundle using these attributes:
hidden RN1 [5, 10, 10]
from P1 response norm {
InputShape = [ 5, 12, 12];
KernelShape = [ 1, 3, 3];
Alpha = 0.001;
Beta = 0.75;
}
- The source layer includes five maps, each with a dimension of 12x12, totaling in 1440 nodes.
- The value of KernelShape indicates that this is a same map normalization layer, where the neighborhood is a 3x3 rectangle.
- The default value of Padding is False, thus the destination layer has only 10 nodes in each dimension. To include one node in the destination layer that corresponds to every node in the source layer, add Padding = [true, true, true]; and change the size of RN1 to [5, 12, 12].
Share declaration
Net# optionally supports defining multiple bundles with shared weights. The weights of any two bundles can be shared if their structures are the same. The following syntax defines bundles with shared weights:
share-declaration:
share { layer-list }
share { bundle-list }
share { bias-list }
layer-list:
layer-name , layer-name
layer-list , layer-name
bundle-list:
bundle-spec , bundle-spec
bundle-list , bundle-spec
bundle-spec:
layer-name => layer-name
bias-list:
bias-spec , bias-spec
bias-list , bias-spec
bias-spec:
1 => layer-name
layer-name:
identifier
For example, the following share-declaration specifies the layer names, indicating that both weights and biases should be shared:
Const {
InputSize = 37;
HiddenSize = 50;
}
input {
Data1 [InputSize];
Data2 [InputSize];
}
hidden {
H1 [HiddenSize] from Data1 all;
H2 [HiddenSize] from Data2 all;
}
output Result [2] {
from H1 all;
from H2 all;
}
share { H1, H2 } // share both weights and biases
- The input features are partitioned into two equal sized input layers.
- The hidden layers then compute higher level features on the two input layers.
- The share-declaration specifies that H1 and H2 must be computed in the same way from their respective inputs.
Alternatively, this could be specified with two separate share-declarations as follows:
share { Data1 => H1, Data2 => H2 } // share weights
<!-- -->
share { 1 => H1, 1 => H2 } // share biases
You can use the short form only when the layers contain a single bundle. In general, sharing is possible only when the relevant structure is identical, meaning that they have the same size, same convolutional geometry, and so forth.
Examples of Net# usage
This section provides some examples of how you can use Net# to add hidden layers, define the way that hidden layers interact with other layers, and build convolutional networks.
Define a simple custom neural network: "Hello World" example
This simple example demonstrates how to create a neural network model that has a single hidden layer.
input Data auto;
hidden H [200] from Data all;
output Out [10] sigmoid from H all;
The example illustrates some basic commands as follows:
- The first line defines the input layer (named
Data). When you use theautokeyword, the neural network automatically includes all feature columns in the input examples. - The second line creates the hidden layer. The name
His assigned to the hidden layer, which has 200 nodes. This layer is fully connected to the input layer. - The third line defines the output layer (named
Out), which contains 10 output nodes. If the neural network is used for classification, there is one output node per class. The keyword sigmoid indicates that the output function is applied to the output layer.
Define multiple hidden layers: computer vision example
The following example demonstrates how to define a slightly more complex neural network, with multiple custom hidden layers.
// Define the input layers
input Pixels [10, 20];
input MetaData [7];
// Define the first two hidden layers, using data only from the Pixels input
hidden ByRow [10, 12] from Pixels where (s,d) => s[0] == d[0];
hidden ByCol [5, 20] from Pixels where (s,d) => abs(s[1] - d[1]) <= 1;
// Define the third hidden layer, which uses as source the hidden layers ByRow and ByCol
hidden Gather [100]
{
from ByRow all;
from ByCol all;
}
// Define the output layer and its sources
output Result [10]
{
from Gather all;
from MetaData all;
}
This example illustrates several features of the neural networks specification language:
- The structure has two input layers,
PixelsandMetaData. - The
Pixelslayer is a source layer for two connection bundles, with destination layers,ByRowandByCol. - The layers
GatherandResultare destination layers in multiple connection bundles. - The output layer,
Result, is a destination layer in two connection bundles; one with the second level hidden layerGatheras a destination layer, and the other with the input layerMetaDataas a destination layer. - The hidden layers,
ByRowandByCol, specify filtered connectivity by using predicate expressions. More precisely, the node inByRowat [x, y] is connected to the nodes inPixelsthat have the first index coordinate equal to the node's first coordinate, x. Similarly, the node inByColat [x, y] is connected to the nodes inPixelsthat have the second index coordinate within one of the node's second coordinate, y.
Define a convolutional network for multiclass classification: digit recognition example
The definition of the following network is designed to recognize numbers, and it illustrates some advanced techniques for customizing a neural network.
input Image [29, 29];
hidden Conv1 [5, 13, 13] from Image convolve
{
InputShape = [29, 29];
KernelShape = [ 5, 5];
Stride = [ 2, 2];
MapCount = 5;
}
hidden Conv2 [50, 5, 5]
from Conv1 convolve
{
InputShape = [ 5, 13, 13];
KernelShape = [ 1, 5, 5];
Stride = [ 1, 2, 2];
Sharing = [false, true, true];
MapCount = 10;
}
hidden Hid3 [100] from Conv2 all;
output Digit [10] from Hid3 all;
The structure has a single input layer,
Image.The keyword
convolveindicates that the layers namedConv1andConv2are convolutional layers. Each of these layer declarations is followed by a list of the convolution attributes.The net has a third hidden layer,
Hid3, which is fully connected to the second hidden layer,Conv2.The output layer,
Digit, is connected only to the third hidden layer,Hid3. The keywordallindicates that the output layer is fully connected toHid3.The arity of the convolution is three: the length of the tuples
InputShape,KernelShape,Stride, andSharing.The number of weights per kernel is
1 + KernelShape\[0] * KernelShape\[1] * KernelShape\[2] = 1 + 1 * 5 * 5 = 26. Or26 * 50 = 1300.You can calculate the nodes in each hidden layer as follows:
NodeCount\[0] = (5 - 1) / 1 + 1 = 5NodeCount\[1] = (13 - 5) / 2 + 1 = 5NodeCount\[2] = (13 - 5) / 2 + 1 = 5The total number of nodes can be calculated by using the declared dimensionality of the layer, [50, 5, 5], as follows:
MapCount * NodeCount\[0] * NodeCount\[1] * NodeCount\[2] = 10 * 5 * 5 * 5Because
Sharing[d]is False only ford == 0, the number of kernels isMapCount * NodeCount\[0] = 10 * 5 = 50.
Acknowledgments
The Net# language for customizing the architecture of neural networks was developed at Microsoft by Shon Katzenberger (Architect, Machine Learning) and Alexey Kamenev (Software Engineer, Microsoft Research). It is used internally for machine learning projects and applications ranging from image detection to text analytics. For more information, see Neural Nets in Machine Learning studio - Introduction to Net#