Data quality for Microsoft Fabric mirrored databases
As a data replication solution, mirroring in Fabric is a low-cost and low-latency solution to bring data from various systems together into a single analytics platform. You can continuously replicate your existing data estate directly into Fabric's OneLake, including data from Azure SQL Database, Azure Cosmos DB, and Snowflake.
Mirroring in Fabric allows users to enjoy an end-to-end product that is designed to simplify your analytics needs. Built for openness and collaboration between Microsoft and technology solutions that can read the open-source delta lake table format, mirroring is a low-cost, and low-latency solution that allows you to create a replica of your data in OneLake, which can be used for all your analytical needs. For more details about Fabric mirroring review the Fabric documentation.
Configure data quality for a Fabric mirrored database
Enable mirroring in your Fabric tenant. Power BI administrators can enable or disable Mirroring for the entire organization or for specific security groups, using the setting found in the Power BI admin portal. Mirroring is enabled by creating a secure connection to your operational data source. You choose whether to replicate an entire database or individual tables and mirroring will automatically keep your data in sync. Once set up, data will continuously replicate into the OneLake for analytics consumption.
After enabled mirroring and initiated replication, confirm that mirroring replication successfully completes.
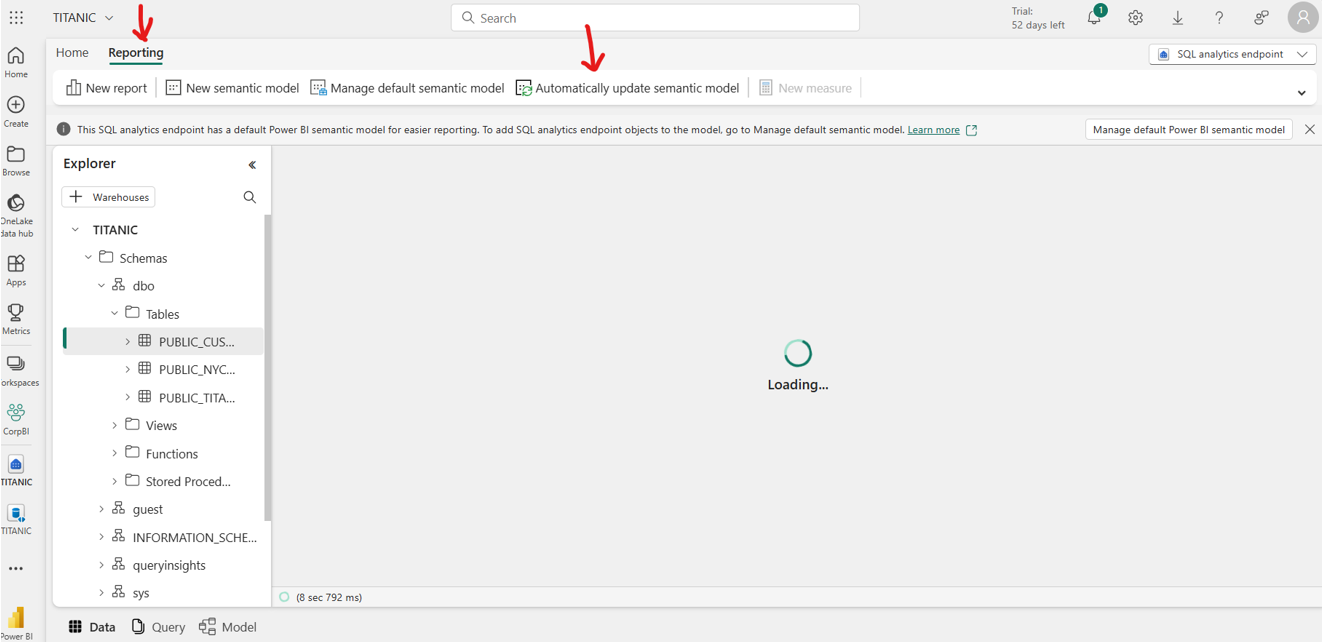
Open the SQL analytics endpoint.

On the Reporting tab, select Automatically update semantic model.
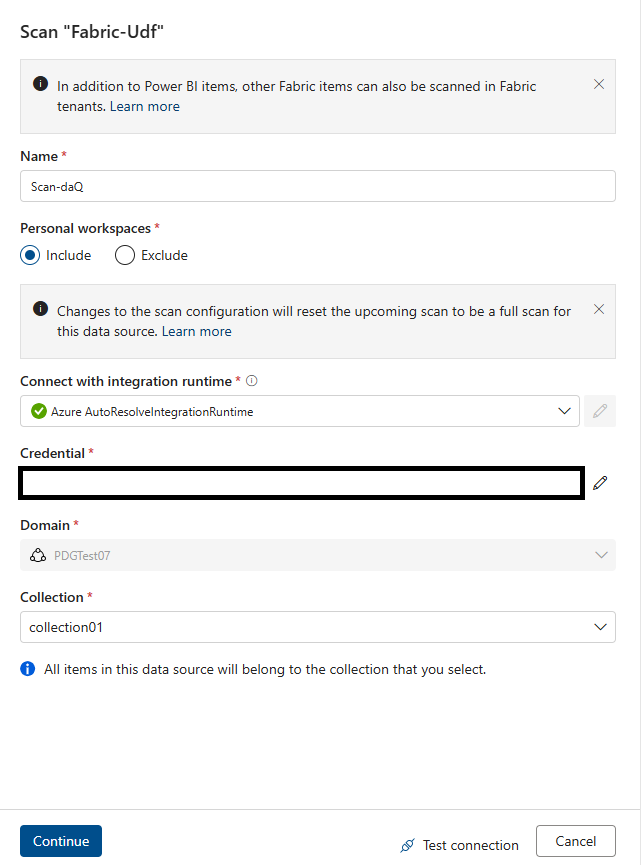
Go to Microsoft Purview Data Map and scan the data source. Use service principal authentication.
When the scan is complete, associate the new data assets with a data product in Microsoft Purview Unified Catalog for curation and data quality assessment.
In your data product, select the mirrored database (not individual tables) from the catalog. It should be available as a Power BI dataset.

All the tables inside your mirrored database should be added automatically to the data product as OneLake Delta Tables.

In the Data quality area of Heath management in Unified Catalog, run a data quality scan or profile your data as usual.


Important
- Use service principals for data map scans, and a managed identity for data quality scans.
- Select the mirrored database instead of individual tables.
- Update semantic model every time.
- If your mirrored database tables aren't available in the Fabric Lakehouse then contact with Fabric support.
- Data quality scanning is supported only for Lakehouse delta, iceberg, and parquet files format.
- There's a dependency on Fabric team to differentiate shortcut items from native items in the OneLake SDK for Lakehouse subartifacts. For now all shortcut items (tables and files) will be considered as native items in scanning.