Configure a distributed Always On availability group
Applies to: ![]() SQL Server
SQL Server
To create a distributed availability group, you must create two availability groups each with its own listener. You then combine these availability groups into a distributed availability group. The following steps provide a basic example in Transact-SQL. This example doesn't cover all of the details of creating availability groups and listeners; instead, it focuses on highlighting the key requirements.
For a technical overview of distributed availability groups, see Distributed availability groups.
Prerequisites
To configure a distributed availability group, you must have the following:
- A supported version of SQL Server
Note
If you configured the listener for your availability group on your SQL Server on Azure VM by using a distributed network name (DNN), then configuring a distributed availability group on top of your availability group is not supported. To learn more, see SQL Server on Azure VM feature interoperability with AG and DNN listener.
Set the endpoint listeners to listen to all IP addresses
Make sure the endpoints can communicate between the different availability groups in the distributed availability group. If one availability group is set to a specific network on the endpoint, the distributed availability group does not work properly. On each server that hosts a replica in the distributed availability group, set the listener to listen on all IP addresses (LISTENER_IP = ALL).
Create an endpoint to listen to all IP addresses
For example, the following script creates a listener endpoint on TCP port 5022 that listens on all IP addresses.
CREATE ENDPOINT [aodns-hadr]
STATE=STARTED
AS TCP (LISTENER_PORT = 5022, LISTENER_IP = ALL)
FOR DATA_MIRRORING (
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
)
GO
Alter an endpoint to listen to all IP addresses
For example, the following script changes a listener endpoint to listen on all IP addresses.
ALTER ENDPOINT [aodns-hadr]
AS TCP (LISTENER_IP = ALL)
GO
Create first availability group
Create the primary availability group on the first cluster
Create an availability group on the first Windows Server Failover Cluster (WSFC). In this example, the availability group is named ag1 for the database db1. The primary replica of the primary availability group is known as the global primary in a distributed availability group. Server1 is the global primary in this example.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Note
The preceding example uses automatic seeding, where SEEDING_MODE is set to AUTOMATIC for both the replicas and the distributed availability group. This configuration sets the secondary replicas and secondary availability group to be automatically populated without requiring a manual backup and restore of primary database.
Join the secondary replicas to the primary availability group
Any secondary replicas must be joined to the availability group with ALTER AVAILABILITY GROUP with the JOIN option. Because automatic seeding is used in this example, you must also call ALTER AVAILABILITY GROUP with the GRANT CREATE ANY DATABASE option. This setting allows the availability group to create the database and begin seeding it automatically from the primary replica.
In this example, the following commands are run on the secondary replica, server2, to join the ag1 availability group. The availability group is then permitted to create databases on the secondary.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Note
When the availability group creates a database on a secondary replica, it sets the database owner as the account that ran the ALTER AVAILABILITY GROUP statement to grant permission to create any database. For complete information, see Grant create database permission on secondary replica to availability group.
Create a listener for the primary availability group
Next add a listener for the primary availability group on the first WSFC. In this example, the listener is named ag1-listener. For detailed instructions on creating a listener, see Create or Configure an Availability Group Listener (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Create second availability group
Then on the second WSFC, create a second availability group, ag2. In this case, the database is not specified, because it is automatically seeded from the primary availability group. The primary replica of the secondary availability group is known as the forwarder in a distributed availability group. In this example, server3 is the forwarder.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Note
The secondary availability group must use the same database mirroring endpoint (in this example port 5022). Otherwise, replication will stop after a local failover.
Join the secondary replicas to the secondary availability group
In this example, the following commands are run on the secondary replica, server4, to join the ag2 availability group. The availability group is then permitted to create databases on the secondary to support automatic seeding.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Create a listener for the secondary availability group
Next add a listener for the secondary availability group on the second WSFC. In this example, the listener is named ag2-listener. For detailed instructions on creating a listener, see Create or Configure an Availability Group Listener (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Create distributed availability group on first cluster
On the first WSFC, create a distributed availability group (named distributedag in this example). Use the CREATE AVAILABILITY GROUP command with the DISTRIBUTED option. The AVAILABILITY GROUP ON parameter specifies the member availability groups ag1 and ag2.
To create your distributed availability group using automatic seeding, use the following Transact-SQL code:
CREATE AVAILABILITY GROUP [distributedag]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Note
The LISTENER_URL specifies the listener for each availability group along with the database mirroring endpoint of the availability group. In this example, that is port 5022 (not port 60173 used to create the listener). If you are using a load balancer, for instance in Azure, add a load balancing rule for the distributed availability group port. Add the rule for the listener port, in addition to the SQL Server instance port.
Cancel automatic seeding to forwarder
If, for whatever reason, it becomes necessary to cancel the initialization of the forwarder before the two availability groups are synchronized, ALTER the distributed availability group by setting the forwarder's SEEDING_MODE parameter to MANUAL and immediately cancel the seeding. Run the command on the global primary:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedag]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Join distributed availability group on second cluster
Then join the distributed availability group on the second WSFC.
To join your distributed availability group using automatic seeding, use the following Transact-SQL code:
ALTER AVAILABILITY GROUP [distributedag]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Join the database on the secondary of the second availability group
If the second availability group was set up to use automatic seeding, then move to step 2.
- If the second availability group is using manual seeding, then restore the backup you took on the global primary to the secondary of the second availability group:
RESTORE DATABASE [db1]
FROM DISK = '<full backup location>' WITH NORECOVERY
RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY
- After the database on the secondary replica of the second availability group is in a restoring state, you have to manually join it to the availability group.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Fail over a distributed availability group
Since SQL Server 2022 (16.x) introduced distributed availability group support for the REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT setting, instructions to fail over a distributed availability are different for SQL Server 2022 and later versions than for SQL Server 2019 and earlier versions.
For a distributed availability group, the only supported failover type is a manual user-initiated FORCE_FAILOVER_ALLOW_DATA_LOSS. Therefore, to prevent data loss, you must take extra steps (described in detail in this section) to ensure data is synchronized between the two replicas before initiating the failover.
In the event of an emergency where data loss is acceptable, you can initiate a failover without ensuring data synchronization by running:
ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS
You can use the same command to fail over to the forwarder, as well as fail back to the global primary.
On SQL Server 2022 (16.x) and later you can configure the REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT setting for a distributed availability group, which is designed to guarantee no data loss when a distributed availability group fails over. If this setting is configured, follow the steps in this section to fail over your distributed availability group. If you don't want to use the REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT setting, then follow the instructions to fail over a distributed availability group in SQL Server 2019 and earlier.
To ensure there's no data loss, make sure to:
- Stop all transactions on the global primary databases (that is, databases of the primary availability group)
- Set the distributed availability group to synchronous commit.
- Wait until the distributed availability group is synchronized and has the same last_hardened_lsn per database.
Once data is synchronized, you can fail over the distributed availability group:
- On the global primary replica, set the distributed availability group role to
SECONDARY, which makes the distributed availability group unavailable. - Set the distributed availability group
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITsetting to 1 by using ALTER AVAILABILITY GROUP. - Test failover readiness.
- Fail over the primary availability group by using ALTER AVAILABILITY GROUP with
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Set distributed availability group REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT to 0.
The following Transact-SQL examples demonstrate detailed steps to fail over the distributed availability group named distributedag:
To ensure that no data is lost, stop all transactions on the global primary databases (that is, databases of the primary availability group). Then set the distributed availability group to synchronous commit by running the following code on both the global primary and the forwarder.
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedag] MODIFY AVAILABILITY GROUP ON 'ag1' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ), 'ag2' WITH ( AVAILABILITY_MODE = SYNCHRONOUS_COMMIT ); -- verifies the commit state of the distributed availability group select ag.name, ag.is_distributed, ar.replica_server_name, ar.availability_mode_desc, ars.connected_state_desc, ars.role_desc, ars.operational_state_desc, ars.synchronization_health_desc from sys.availability_groups ag join sys.availability_replicas ar on ag.group_id=ar.group_id left join sys.dm_hadr_availability_replica_states ars on ars.replica_id=ar.replica_id where ag.is_distributed=1 GONote
In a distributed availability group, the synchronization status between the two availability groups depends on the availability mode of both replicas. For synchronous commit mode, both the current primary availability group and the current secondary availability group must have
SYNCHRONOUS_COMMITavailability mode. For this reason, you must run the previous script on both the global primary replica and the forwarder.Wait until the status of the distributed availability group has changed to
SYNCHRONIZEDand all replicas have the same last_hardened_lsn (per database). Run the following query on both the global primary, which is the primary replica of the primary availability group, and the forwarder to check the synchronization_state_desc and last_hardened_lsn:-- Run this query on the Global Primary and the forwarder -- Check the results to see if synchronization_state_desc is SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder -- If not rerun the query on both side every 5 seconds until it is the case -- SELECT ag.name , drs.database_id , db_name(drs.database_id) as database_name , drs.group_id , drs.replica_id , drs.synchronization_state_desc , drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag on drs.group_id = ag.group_id;Proceed after the availability group synchronization_state_desc is
SYNCHRONIZED, and the last_hardened_lsn is the same per database on both the global primary and forwarder. If synchronization_state_desc is notSYNCHRONIZEDor last_hardened_lsn is not the same, run the command every five seconds until it changes. Do not proceed until the synchronization_state_desc =SYNCHRONIZEDand last_hardened_lsn is the same per database.On the global primary, set the distributed availability group role to
SECONDARY.ALTER AVAILABILITY GROUP distributedag SET (ROLE = SECONDARY);At this point, the distributed availability group is not available.
For SQL Server 2022 (16.x) and later, on the global primary, set REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.
ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Test the failover readiness. Run the following query on both the global primary and the forwarder:
-- Run this query on the Global Primary and the forwarder -- Check the results to see if the last_hardened_lsn is the same per database on both the global primary and forwarder -- The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database -- SELECT ag.name, drs.database_id, db_name(drs.database_id) as database_name, drs.group_id, drs.replica_id, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states drs INNER JOIN sys.availability_groups ag ON drs.group_id = ag.group_id;The availability group is ready to fail over when the last_hardened_lsn is the same for both availability groups per database. If the last_hardened_lsn is not the same after a period of time, to avoid data loss, fail back to the global primary by running this command on the global primary and then start over from the second step:
-- If the last_hardened_lsn is not the same after a period of time, to avoid data loss, -- we need to fail back to the global primary by running this command on the global primary -- and then start over from the second step: ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;Fail over from the primary availability group to the secondary availability group. Run the following command on the forwarder, the SQL Server that hosts the primary replica of the secondary availability group.
-- Once the last_hardened_lsn is the same per database on both sides -- We can Fail over from the primary availability group to the secondary availability group. -- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedag FORCE_FAILOVER_ALLOW_DATA_LOSS;After this step, the distributed availability group is available.
For SQL Server 2022 (16.x) and later, clear distributed availability group
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT.ALTER AVAILABILITY GROUP distributedag SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);
After completing these steps, the distributed availability group fails over without any data loss. If the availability groups are across a geographical distance that causes latency, change the availability mode back to ASYNCHRONOUS_COMMIT.
Remove a distributed availability group
The following Transact-SQL statement removes a distributed availability group named distributedag:
DROP AVAILABILITY GROUP [distributedag]
Create distributed availability group on failover cluster instances
You can create a distributed availability group using an availability group on a failover cluster instance (FCI). In this case, you don't need an availability group listener. Use the virtual network name (VNN) for the primary replica of the FCI instance. The following example shows a distributed availability group called SQLFCIDAG. One availability group is SQLFCIAG. SQLFCIAG has two FCI replicas. The VNN for the primary FCI replica is SQLFCIAG-1, and the VNN for the secondary FCI replica is SQLFCIAG-2. The distributed availability group also includes SQLAG-DR, for disaster recovery.
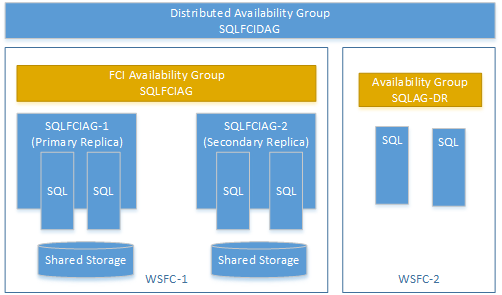
The following DDL creates this distributed availability group.
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
The listener URL is the VNN of the primary FCI instance.
Manually fail over FCI in distributed availability group
To manually fail over the FCI availability group, update the distributed availability group to reflect the change of listener URL. For example, run the following DDL on both the global primary of the distributed AG and the forwarder of the distributed AG of SQLFCIDAG:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)
Next steps
CREATE AVAILABILITY GROUP (Transact-SQL)
ALTER AVAILABILITY GROUP (Transact-SQL)