Tune nonclustered indexes with missing index suggestions
Applies to: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
The missing indexes feature is a lightweight tool for finding missing indexes that might significantly improve query performance. This article describes how to use missing index suggestions to effectively tune indexes and improve query performance.
Limitations of the missing index feature
When the query optimizer generates a query plan, it analyzes what the best indexes are for a particular filter condition. If the best indexes don't exist, the query optimizer still generates a query plan using the least-costly access methods available, but also stores information about these indexes. The missing indexes feature enables you to access that information about best possible indexes so you can decide whether they should be implemented.
Query optimization is a time sensitive process, so there are limitations to the missing index feature. Limitations include:
- Missing index suggestions are based on estimates made during the optimization of a single query, prior to query execution. Missing index suggestions aren't tested or updated after query execution.
- The missing index feature suggests only nonclustered disk-based rowstore indexes. Unique and filtered indexes aren't suggested.
- Key columns are suggested, but the suggestion doesn't specify an order for those columns. For information on ordering columns, see the Apply missing index suggestions section of this article.
- Included columns are suggested, but SQL Server performs no cost-benefit analysis regarding the size of the resulting index when a large number of included columns are suggested.
- Missing index requests might offer similar variations of indexes on the same table and column(s) across queries. It's important to review index suggestions and combine where possible.
- Suggestions aren't made for trivial query plans.
- Cost information is less accurate for queries involving only inequality predicates.
- Suggestions are gathered for a maximum of 600 missing index groups. After this threshold is reached, no more missing index group data is gathered.
Due to these limitations, missing index suggestions are best treated as one of several sources of information when performing index analysis, design, tuning, and testing. Missing index suggestions are not prescriptions to create indexes exactly as suggested.
Note
Azure SQL Database offers automatic index tuning. Automatic index tuning uses machine learning to learn horizontally from all databases in Azure SQL Database through AI and dynamically improve its tuning actions. Automatic index tuning includes a verification process to ensure there is a positive improvement to the workload performance from indexes created.
View missing index recommendations
The missing indexes feature consists of two components:
- The
MissingIndexeselement in the XML of execution plans. This allows you to correlate indexes that the query optimizer considers missing with the queries for which they are missing. - A set of dynamic management views (DMVs) that can be queried to return information about missing indexes. This allows you to view all of the missing index recommendations for a database.
View missing index suggestions in execution plans
Query execution plans can be generated or obtained in multiple ways:
- When writing or tuning a query, you can use SQL Server Management Studio (SSMS) to display the estimated execution plan without running the query, or execute the query and display an actual execution plan.
- Query Store, when enabled, collects execution plans.
- You can identify cached execution plans by querying DMVs such as sys.dm_exec_text_query_plan.
For example, you can use the following query to generate missing index requests against the AdventureWorks sample database.
SELECT City, StateProvinceID, PostalCode
FROM Person.Address as a
JOIN Person.BusinessEntityAddress as ba on
a.AddressID = ba.AddressID
JOIN Person.Person as p on
ba.BusinessEntityID = p.BusinessEntityID
WHERE p.FirstName like 'K%' and
StateProvinceID = 9;
GO
To generate and view the missing index requests:
Open SSMS and connect a session to your copy of the AdventureWorks sample database.
Paste the query into the session and generate an estimated execution plan in SSMS for the query by selecting the Display Estimated Execution Plan toolbar button. The execution plan will display in a pane in the current session. A green Missing Index statement will appear near the top of the graphic plan.
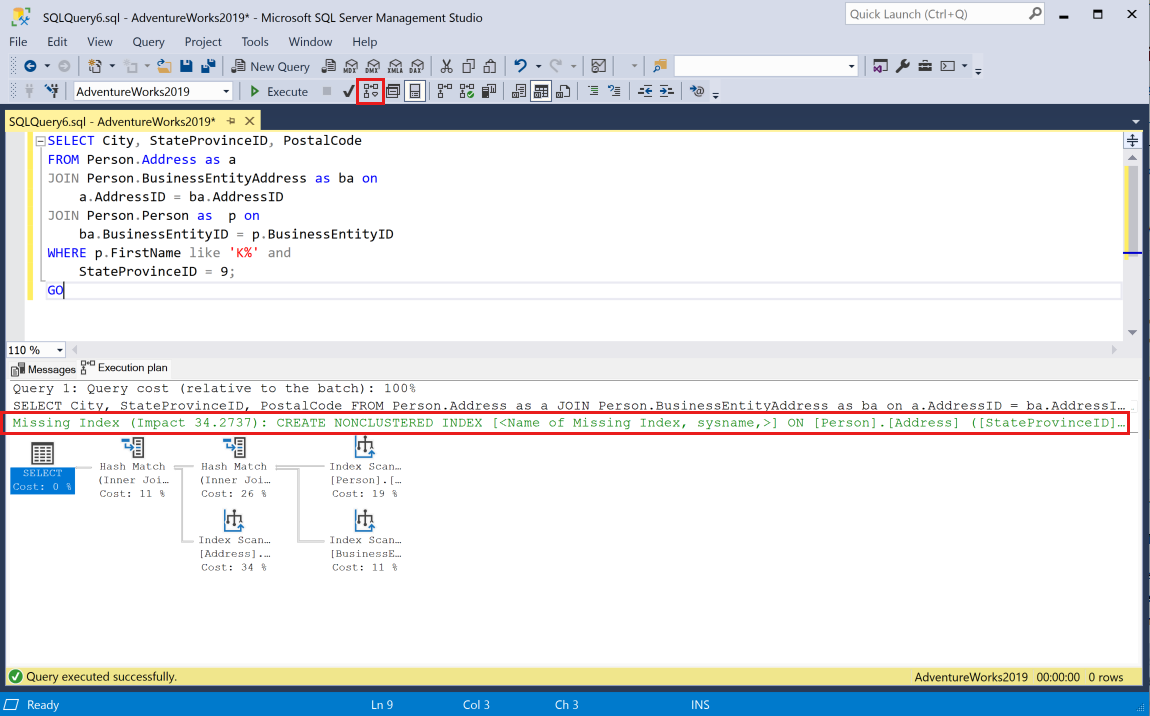
A single execution plan might contain multiple missing index requests, but only one missing index request can be displayed in the graphic execution plan. One option to view a full list of missing indexes for an execution plan is to view the execution plan XML.
Right-click on the execution plan and select Show Execution Plan XML... from the menu.
The execution plan XML will open as a new tab inside SSMS.
Note
Only a single missing index suggestion will be shown in the Missing Index Details... menu option, even if multiple suggestions are present in the execution plan XML. The missing index suggestion displayed might not be the one with the highest estimated improvement for the query.
Display the Find dialog by using the CTRL+f shortcut.
Search for
MissingIndex.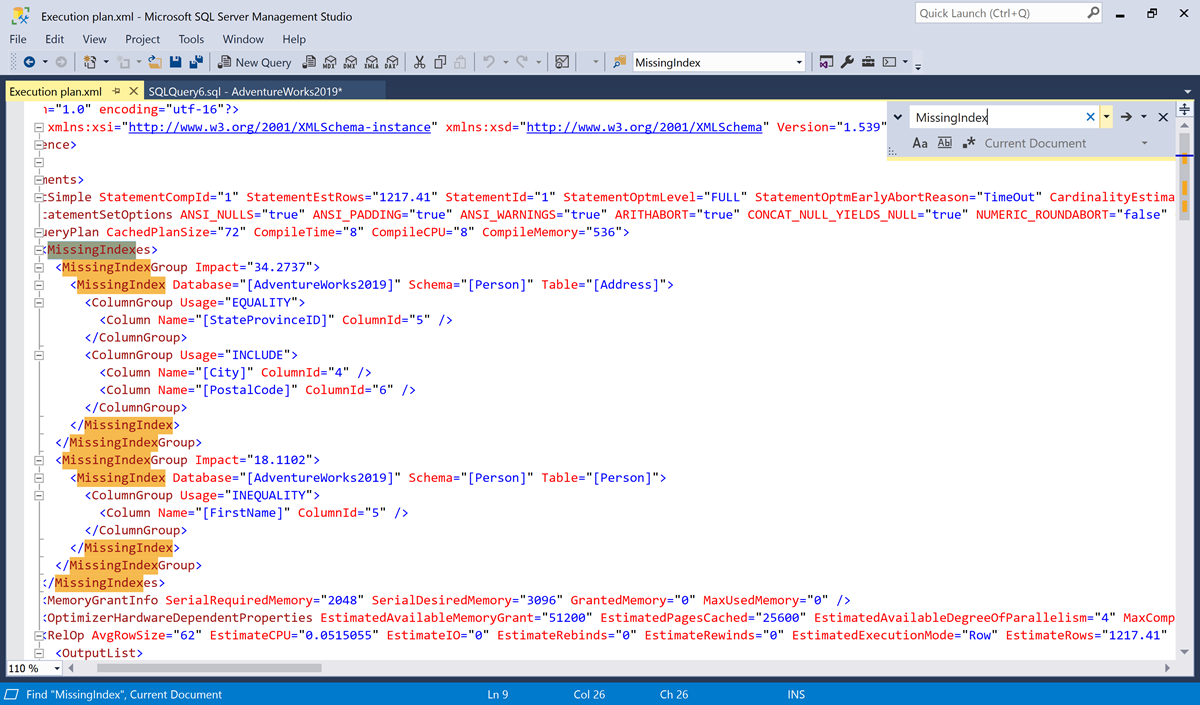
In this example, there are two
MissingIndexelements.- The first missing index suggests the query might use an index on the
Person.Addresstable that supports an equality search on theStateProvinceIDcolumn, which includes two more columns,CityandPostalCode'. At the time of optimization, the query optimizer believed that this index might reduce the estimated cost of the query by 34.2737%. - The second missing index suggests the query might use an index on the
Person.Persontable that supports an inequality search on the FirstName column. At the time of optimization, the query optimizer believed that this index might reduce the estimated cost of the query by 18.1102%.
- The first missing index suggests the query might use an index on the


Each disk-based nonclustered index in your database takes up space, adds overhead for inserts, updates, and deletes, and might require maintenance. For these reasons, it's a best practice to review all the missing index requests for a table and the existing indexes on a table before adding an index based on a query execution plan.
View missing index suggestions in DMVs
You can retrieve information about missing indexes by querying the dynamic management objects listed in the following table.
| Dynamic management view | Information returned |
|---|---|
| sys.dm_db_missing_index_group_stats (Transact-SQL) | Returns summary information about missing index groups, for example, the performance improvements that could be gained by implementing a specific group of missing indexes. |
| sys.dm_db_missing_index_groups (Transact-SQL) | Returns information about a specific group of missing indexes, such as the group identifier and the identifiers of all missing indexes that are contained in that group. |
| sys.dm_db_missing_index_details (Transact-SQL) | Returns detailed information about a missing index; for example, it returns the name and identifier of the table where the index is missing, and the columns and column types that should make up the missing index. |
| sys.dm_db_missing_index_columns (Transact-SQL) | Returns information about the database table columns that are missing an index. |
The following query uses the missing index DMVs to generate CREATE INDEX statements. The index creation statements here are intended to assist you in crafting your own DDL after examining all of the requests for the table along with existing indexes on the table.
SELECT TOP 20
CONVERT (varchar(30), getdate(), 126) AS runtime,
CONVERT (decimal (28, 1),
migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)
) AS estimated_improvement,
'CREATE INDEX missing_index_' +
CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' +
mid.statement + ' (' + ISNULL (mid.equality_columns, '') +
CASE
WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL THEN ','
ELSE ''
END + ISNULL (mid.inequality_columns, '') + ')' +
ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
FROM sys.dm_db_missing_index_groups mig
JOIN sys.dm_db_missing_index_group_stats migs ON
migs.group_handle = mig.index_group_handle
JOIN sys.dm_db_missing_index_details mid ON
mig.index_handle = mid.index_handle
ORDER BY estimated_improvement DESC;
GO
This query orders the suggestions by a column named estimated_improvement. The estimated improvement is based on a combination of:
- The estimated query cost of queries associated with the missing index request.
- The estimated impact of adding the index. This is an estimate of how much the nonclustered index would reduce the query cost.
- The sum of executions of query operators (seeks and scans) that have been run for queries associated with the missing index request. As we discuss in persist missing indexes with Query Store, this information is periodically cleared.
Note
The Index-Creation script in Microsoft's Tiger Toolbox examines missing index DMVs and automatically removes any redundant suggested indexes, parses out low impact indexes, and generates index creation scripts for your review. As in the query above, it does NOT execute index creation commands. The Index-Creation script is suitable for SQL Server and Azure SQL Managed Instance. For Azure SQL Database, consider implementing automatic index tuning.
Review Limitations of the missing index feature and how to apply missing index suggestions before creating indexes, and modify the index name to match the naming convention for your database.
Persist missing indexes with Query Store
Missing index suggestions in DMVs are cleared by events such as instance restarts, failovers, and setting a database offline. Additionally, when the metadata for a table changes, all missing index information about that table is deleted from these dynamic management objects. Table metadata changes can occur when columns are added or dropped from a table, for example, or when an index is created on a column of a table. Performing an ALTER INDEX REBUILD operation on an index on a table also clears missing index requests for that table.
Similarly, execution plans stored in the plan cache are cleared by events such as instance restarts, failovers, and setting a database offline. Execution plans might be removed from cache due to memory pressure and recompilations.
Missing index suggestions in execution plans can be persisted across these events by enabling Query Store.
The following query retrieves the top 20 query plans containing missing index requests from Query Store based on a rough estimate of total logical reads for the query. The data is limited to query executions within the past 48 hours.
SELECT TOP 20
qsq.query_id,
SUM(qrs.count_executions) * AVG(qrs.avg_logical_io_reads) as est_logical_reads,
SUM(qrs.count_executions) AS sum_executions,
AVG(qrs.avg_logical_io_reads) AS avg_avg_logical_io_reads,
SUM(qsq.count_compiles) AS sum_compiles,
(SELECT TOP 1 qsqt.query_sql_text FROM sys.query_store_query_text qsqt
WHERE qsqt.query_text_id = MAX(qsq.query_text_id)) AS query_text,
TRY_CONVERT(XML, (SELECT TOP 1 qsp2.query_plan from sys.query_store_plan qsp2
WHERE qsp2.query_id=qsq.query_id
ORDER BY qsp2.plan_id DESC)) AS query_plan
FROM sys.query_store_query qsq
JOIN sys.query_store_plan qsp on qsq.query_id=qsp.query_id
CROSS APPLY (SELECT TRY_CONVERT(XML, qsp.query_plan) AS query_plan_xml) AS qpx
JOIN sys.query_store_runtime_stats qrs on
qsp.plan_id = qrs.plan_id
JOIN sys.query_store_runtime_stats_interval qsrsi on
qrs.runtime_stats_interval_id=qsrsi.runtime_stats_interval_id
WHERE
qsp.query_plan like N'%<MissingIndexes>%'
and qsrsi.start_time >= DATEADD(HH, -48, SYSDATETIME())
GROUP BY qsq.query_id, qsq.query_hash
ORDER BY est_logical_reads DESC;
GO
Apply missing index suggestions
To effectively use missing index suggestions, follow nonclustered index design guidelines. When tuning nonclustered indexes with missing index suggestions, review the base table structure, carefully combine indexes, consider key column order, and review included column suggestions.
Review the base table structure
Before creating nonclustered indexes on a table based on missing index suggestions, review the table's clustered index.
One way to check for a clustered index is by using the sp_helpindex system stored procedure. For example, we can view a summary of the indexes on the Person.Address table by executing the following statement:
exec sp_helpindex 'Person.Address';
GO
Review the index_description column. A table can have only one clustered index. If a clustered index has been implemented for the table, the index_description will contain the word 'clustered'.

If no clustered index is present, the table is a heap. In this case, review if the table was intentionally created as a heap to solve a specific performance problem. Most tables benefit from clustered indexes: often, tables are implemented as heaps by accident. Consider implementing a clustered index based on the clustered index design guidelines.
Review missing indexes and existing indexes for overlap
Missing indexes might offer similar variations of nonclustered indexes on the same table and column(s) across queries. Missing indexes might also be similar to existing indexes on a table. For optimal performance, it is best to examine missing indexes and existing indexes for overlap and avoid creating duplicate indexes.
Script out existing indexes on a table
One way to examine the definition of existing indexes on a table is to script out the indexes with Object Explorer Details:
- Connect Object Explorer to your instance or database.
- Expand the node for the database in question in Object Explorer.
- Expand the Tables folder.
- Expand the table for which you would like to script out indexes.
- Select the Indexes folder.
- If the Object Explorer Details pane is not already open, on the View menu, select Object Explorer Details or press F7.
- Select all indexes listed on the Object Explorer Details pane with the shortcut CTRL+a.
- Right-click anywhere in the selected region and select the menu option Script index as, then CREATE To and New Query Editor Window.

Review indexes and combine where possible
Review the missing index recommendations for a table as a group, along with the definitions of existing indexes on the table. Remember that when defining indexes, generally equality columns should be put before the inequality columns, and together they should form the key of the index. To determine an effective order for the equality columns, order them based on their selectivity: list the most selective columns first (leftmost in the column list). Unique columns are most selective, while columns with many repeating values are less selective.
Included columns should be added to the CREATE INDEX statement using the INCLUDE clause. The order of included columns doesn't affect query performance. Therefore, when combining indexes, included columns might be combined without worrying about order. Learn more in included columns guidelines.
For example, you might have a table, Person.Address, with an existing index on the key column StateProvinceID. You might see missing index recommendations for the Person.Address table for the following columns:
- EQUALITY filters for
StateProvinceIDandCity - EQUALITY filters for
StateProvinceIDandCity, INCLUDEPostalCode
Modifying the existing index to match the second recommendation, an index with keys on StateProvinceID and City including PostalCode, would likely satisfy the queries that generated both index suggestions.
Tradeoffs are common in index tuning. It is likely that for many datasets, the City column is more selective than the StateProvinceID column. However, if our existing index on StateProvinceID is heavily used, and other requests largely search on both StateProvinceID and City, it is lower overhead for the database in general to have a single index with both columns in the key, leading on StateProvinceID, although it is not the most selective column.
Indexes might be modified in multiple ways:
- You can use the CREATE INDEX Statement with the DROP_EXISTING clause. You might wish to rename the indexes following the modification so that the name still accurately describes the index definition, depending on your naming convention.
- You can use the DROP INDEX (Transact-SQL) statement followed by a CREATE INDEX Statement.
The order of index keys matters when combining the index suggestions: City as a leading column is different from StateProvinceID as a leading column. Learn more in nonclustered index design guidelines.
When creating indexes, consider using online index operations when they are available.
While indexes can dramatically improve query performance in some cases, indexes also have overhead and management costs. Review general index design guidelines to help assess the benefit of indexes before creating them.
Verify if your index change is successful
It's important to confirm if your index changes have been successful: is the query optimizer using your indexes?
One way to validate your index changes is to use Query Store to identify queries with missing index requests. Note the query_id for the queries. Use the Tracked Queries view in Query Store to check if execution plans have changed for a query and if the optimizer is using your new or modified index. Learn more about Tracked Queries in start with query performance troubleshooting.
Related content
Learn more about index and performance tuning in the following articles: