Model small lookup entities
Our data model includes two small reference data entities, ProductCategory and ProductTag. These entities are used for reference values and are related to other entities though a 1:Many relationship.
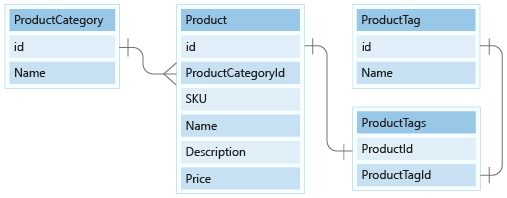
In this unit, we'll model the ProductCategory and ProductTag entities in our document model.
Model product categories
Firstly for categories, we'll model the data with its id and name columns as the only properties and put it in a new container called ProductCategory.
Next we need to choose a partition key. Let's explore the operations that we need to perform on this data.
We'll create a new product category, edit a product category, and then list all product categories. Creating and editing product categories are not frequently run operations. Our e-commerce application will often list all product categories when customers visit the website. So the last operation is the one we'll run the most.
The query for this last operation will look like this: SELECT * FROM c.
With id as the selected partition key this query will now be cross-partition, even though we want to try to optimize these read-heavy operations use only a single partition if possible. We also know that the data for product category will never grow near 20 GB in size, so how would this information help us in modeling the data in a way that will result in a single partition query when we list all product categories.
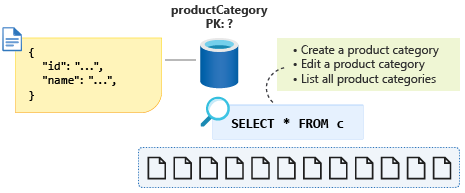
In order to coerce this small amount of data back into a single partition, we can add an entity discriminator property to our schema and use this as the partition key for this container. By assigning this property a constant value for all documents of this type in the container, we ensure that we now have a single partition query. In this case, we will call the property type and give a constant value of category. Our query would now look like: SELECT * FROM c WHERE c.type = ”category”.
Model product tags
Next up is the ProductTag entity. This entity is nearly identical in function to ProductCategory entity we discussed in the previous section. Let's take the same approach here and model the document to contain ID and name properties and create an entity discriminator property called type, in this case with a constant value of tag. Let's create a new container called ProductTag and make type the new partition key.
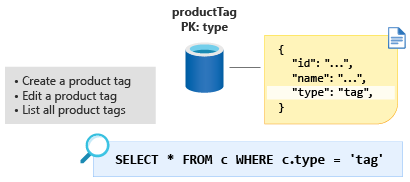
Some people find this technique for modeling small lookup tables strange. However, modeling our data this way gives us an opportunity to make a further optimization in the next module.