What is scalability?
In the business world, growth can be beneficial. However, when growth happens too quickly, and when you haven’t adequately prepared for it, growth can create issues. One of these issues is the effect of growth on the reliability of applications and services that weren’t designed to handle a large increase in traffic.
To your customers and users, an outage is an outage. They don’t know or care whether they’re unable to access your site because of buggy code or because too many other people are trying to use your perfectly coded site at the same time.
Scalability is the ability to adapt to increased demands or changing needs. Your applications and services must be able to handle a larger amount of workload to accommodate growth. Scalable applications are able to handle an expanding number of requests over time without a negative effect on availability or performance.
In this unit, you learn about the relationship between scalability and reliability, the importance of capacity planning in achieving scalability, and briefly review some basic concepts and terms related to scaling.
Scalability/reliability relationship
The good news is that making your app more scalable may also make it more reliable. For example, if your system autoscales, then given a component failure on a single virtual machine, the autoscaling service provisions another instance to meet your minimum virtual machine (VM) count requirements. Your system becomes more reliable. In another example, you're using a higher-level service like Azure Storage that's inherently scalable. If you have a storage issue, the service is built to be reliable, so your data is replicated.
Here's an analogy: Think of the accessibility ramps that you often see outside buildings that were initially designed to accommodate people in wheelchairs. They serve that purpose. But, they’re also used by parents with babies in strollers or carriages, or by small children for whom the stair steps are too deep or high. This usage is a secondary benefit.
Reliability is often a secondary benefit of scalability. If you design your systems to be scalable, they're likely to be more reliable, too.
Scalability and capacity planning
Capacity planning involves determining the resources you need to meet both present and future demands. You do this planning by analyzing your current resource usage and then projecting for future growth.
To estimate capacity needs in the future, you should consider such factors as:
- Expected business growth
- Periodic fluctuations (seasonal, and so on)
- Application constraints
- Identification of bottlenecks and limiting factors
You also need to set service level objectives so you can create a capacity management plan that reliably meets or exceeds those objectives as the workload and environment change.
Capacity planning is an iterative process. As we go through this module, you learn how to map out resource requirements for application components.
Concepts and terminology
Before you can fully understand the concepts and strategies you encounter in this module, you need some prerequisite knowledge of a few basic concepts and fundamental terms related to scaling.
- Scaling up: Making a component bigger so as to handle an increased workload. Also referred to as vertical scaling.
- Scaling out: Adding more components or resources to spread out the load over a distributed architecture. For example, using a simple architecture that has multiple back ends behind a set of front ends. As load increases, we add more back end (and front end) servers to handle it. Also referred to as horizontal scaling.
- Manually scaling: Human action is necessary to increase the amount of resources.
- Autoscaling: The system automatically adjusts the amount of resources based on the load. To be clear, the amount is adjusted both up and down based on either an increased or decreased load.
- DIY scale: Do-it-yourself scaling whereby you have to configure the autoscaling.
- Inherent scale: Services that were built to be scalable and handle this scaling for you behind the scenes without any intervention on your part. From your perspective, they look almost infinitely scalable because you can just consume more resources without needing to manually provision them.
Tailwind Traders architecture
In this module, we're going to use an example architecture from a fictional hardware company called Tailwind Traders. Their e-commerce platform looks like this:
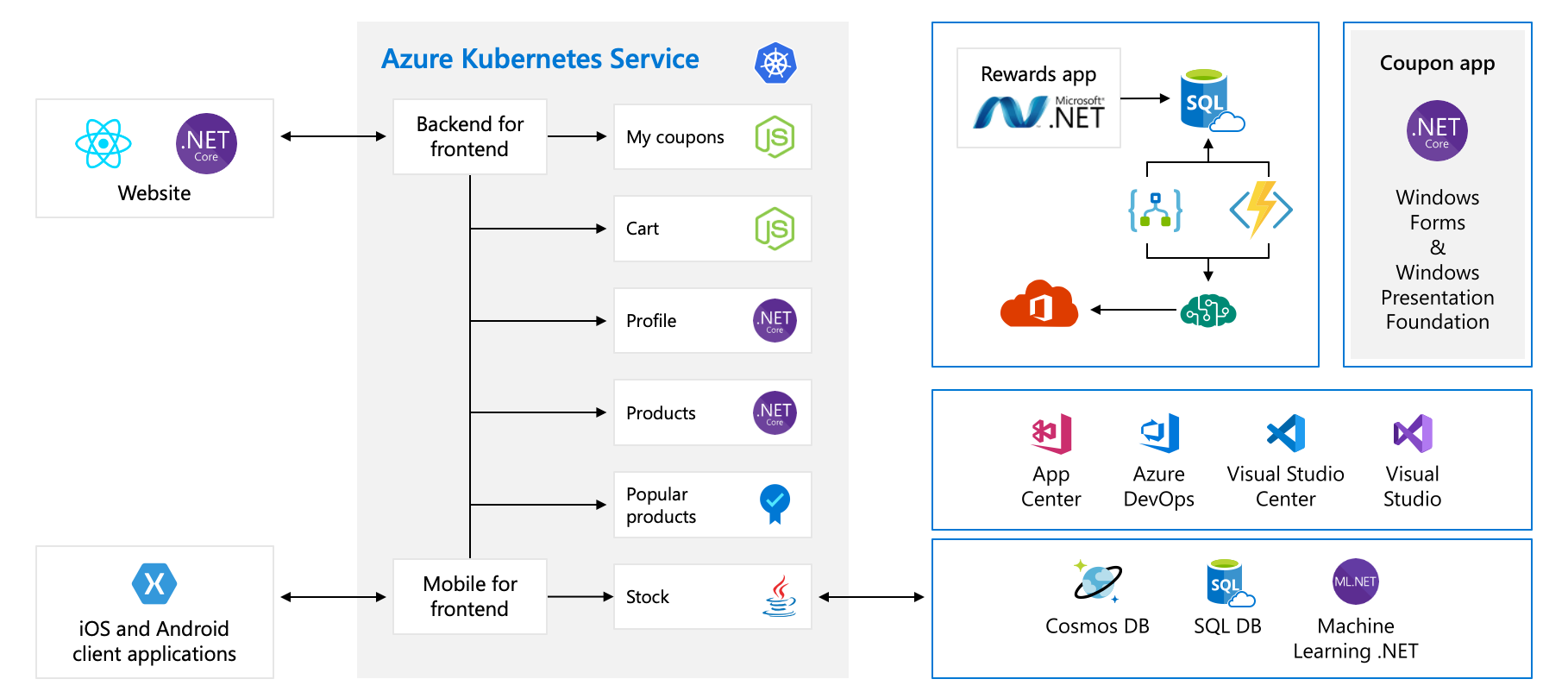
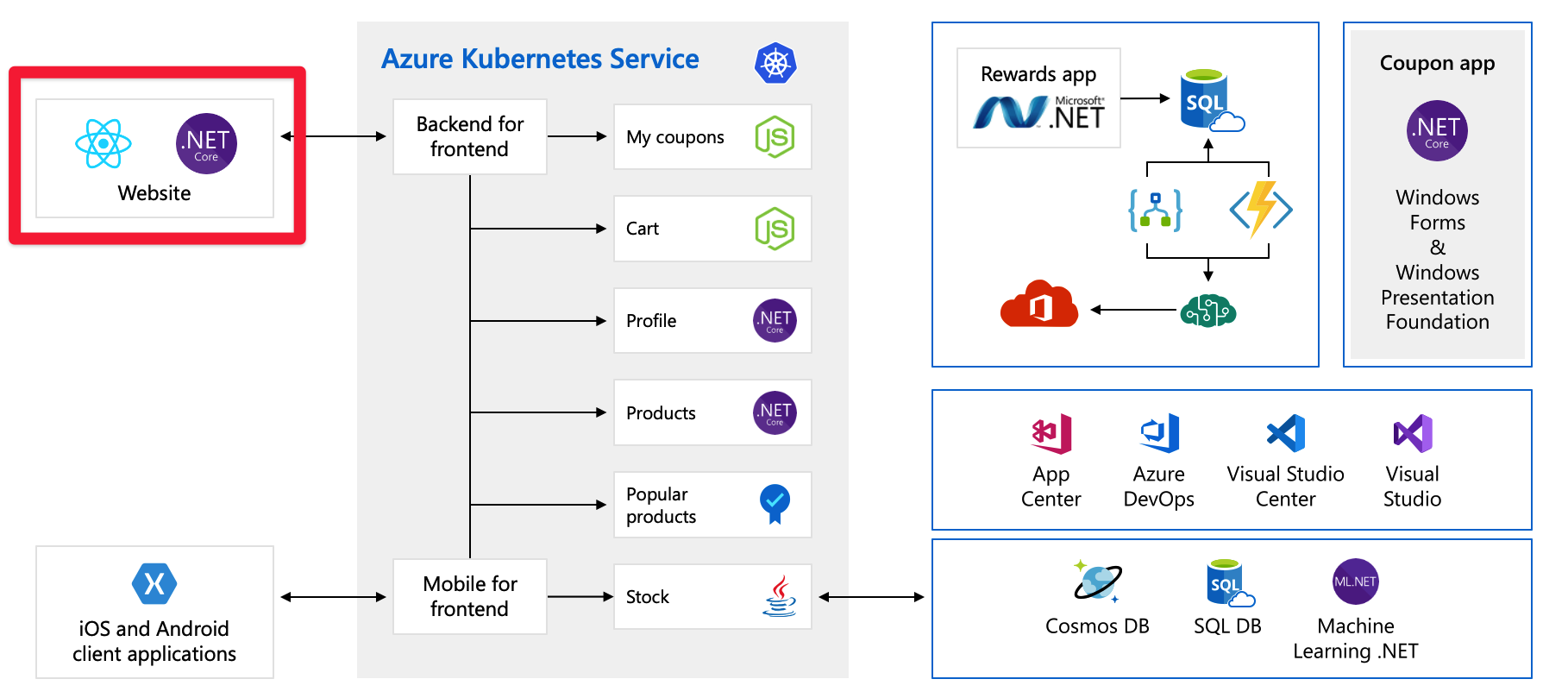
This diagram is fairly complex at first glance, so let's walk through it. The website has a front end. that's what you talk to if you go to tailwindtraders.com.
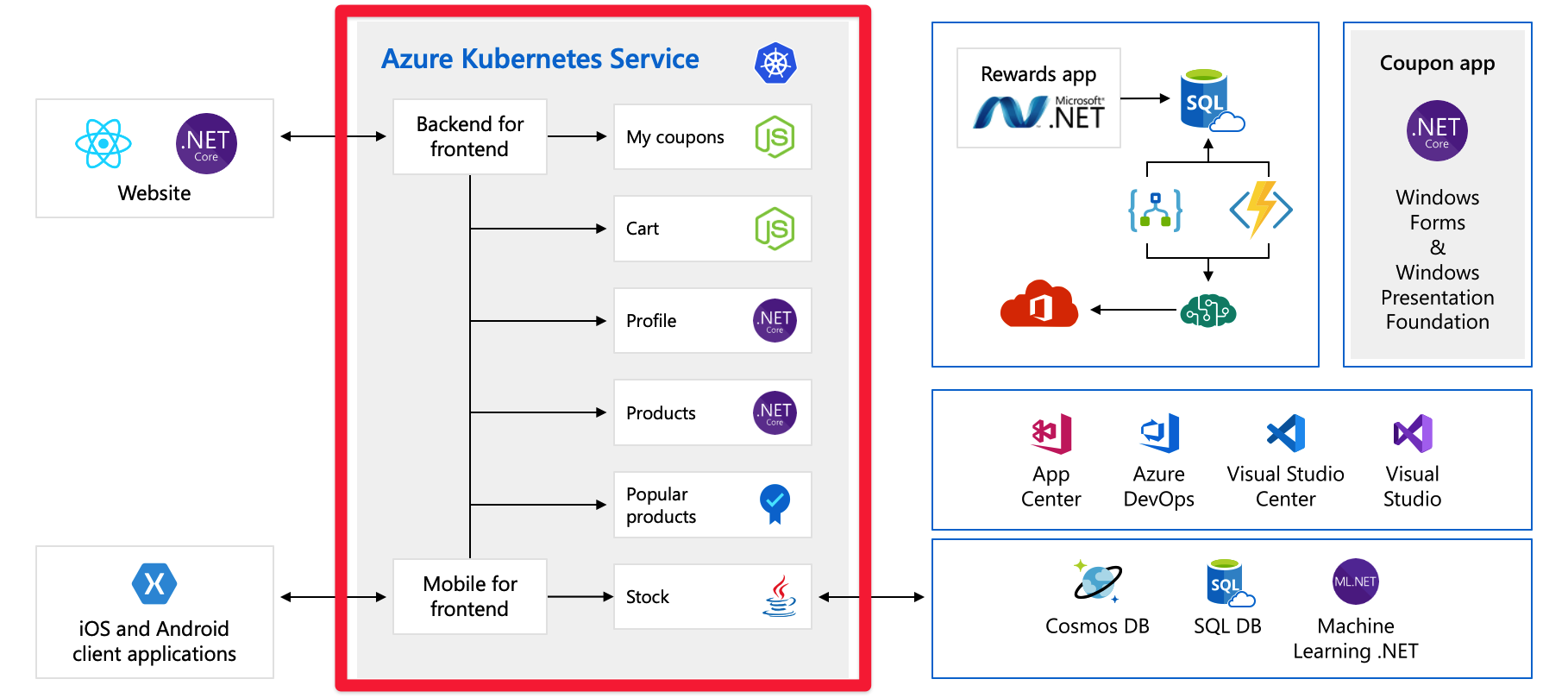
The front end talks to a set of back end services. These back end services include the common items such as a coupon service, a shopping cart service, an inventory service, and so on. They're all running in Azure Kubernetes Service. There are other parts and technologies at play with this application. All you need to focus on is the front end and the back end services running on Kubernetes.
Single points of failure
Now that you have seen the whole architecture, let's take a moment to examine the single points of failure and the places we might put our attention when thinking about scaling.
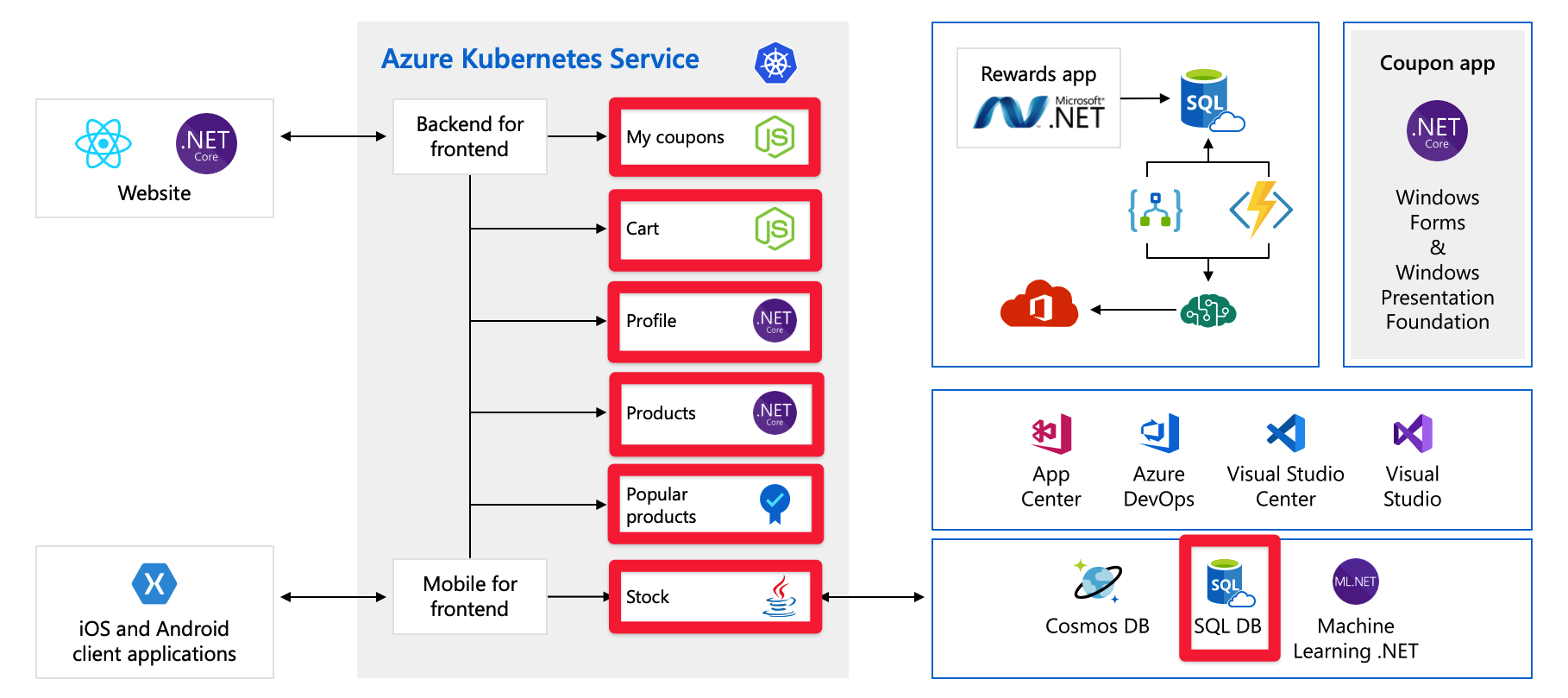
All of these services are a single point of failure - they’re not built for resiliency, or for scale. If one of them gets overloaded, it’s likely to crash, and there's no easy way to resolve that in the moment.
Later in this module, we look at other ways to design theses service to be more scalable and reliable.
Pre-provisioned capacity
Let's take a look at another issue that could prove troublesome. Here are the services/components that require us to pre-provision capacity:
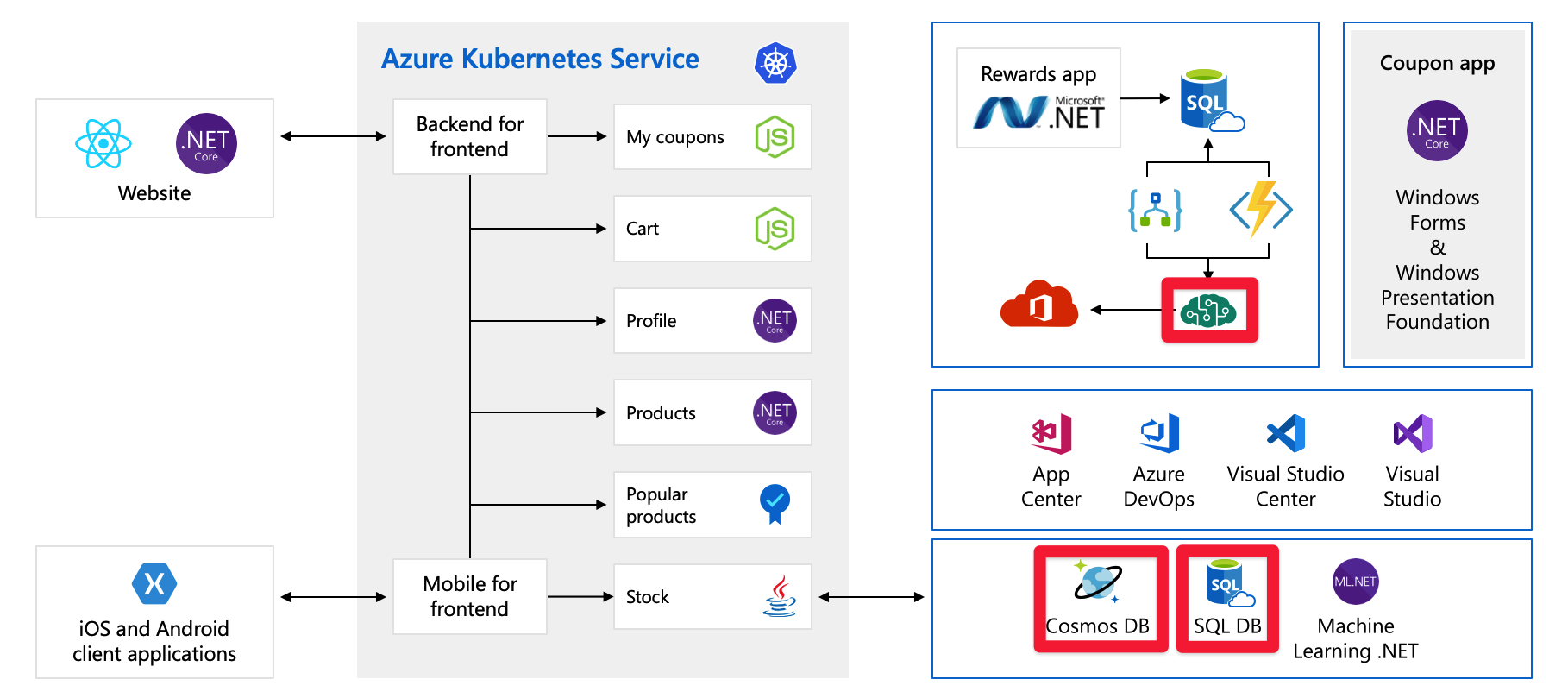
For example, with Cosmos DB, we pre-provision the throughput. If we exceed those limits, we’re going to start returning error messages to our customers. With Azure AI services, we select the tier and that tier has a maximum number of requests per second. After we reach either of limits, clients are going to be throttled.
Will a significant spike in traffic, like launching a new product, make us hit these limits? Right now, we don’t know. This matter is another that we review later in this module.
Costs
Even when we do things right, we still need to plan for growth. Here are the pay-per-use services:
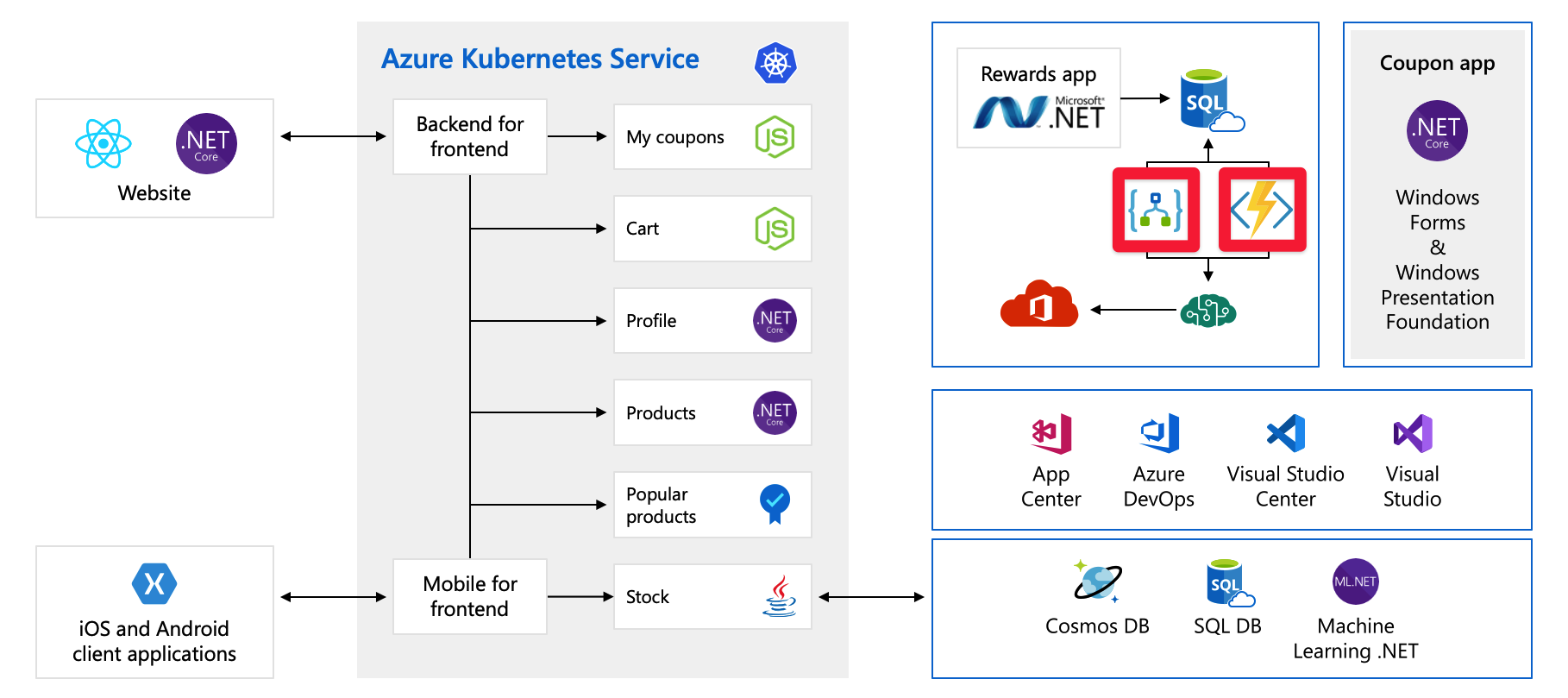
Here, we’re using Azure Logic Apps and Azure Functions, which are both examples of serverless technology. These services scale automatically, and we pay per request. Your bill grows as your customer base does. We should at least be aware of the impact upcoming events like a product launch may have on our cloud spend. We work on understanding and predicting our cloud spend later in this module as well.