Run Spark code
To edit and run Spark code in Microsoft Fabric, you can use notebooks, or you can define a Spark job.
Notebooks
When you want to use Spark to explore and analyze data interactively, use a notebook. Notebooks enable you to combine text, images, and code written in multiple languages to create an interactive item that you can share with others and collaborate.
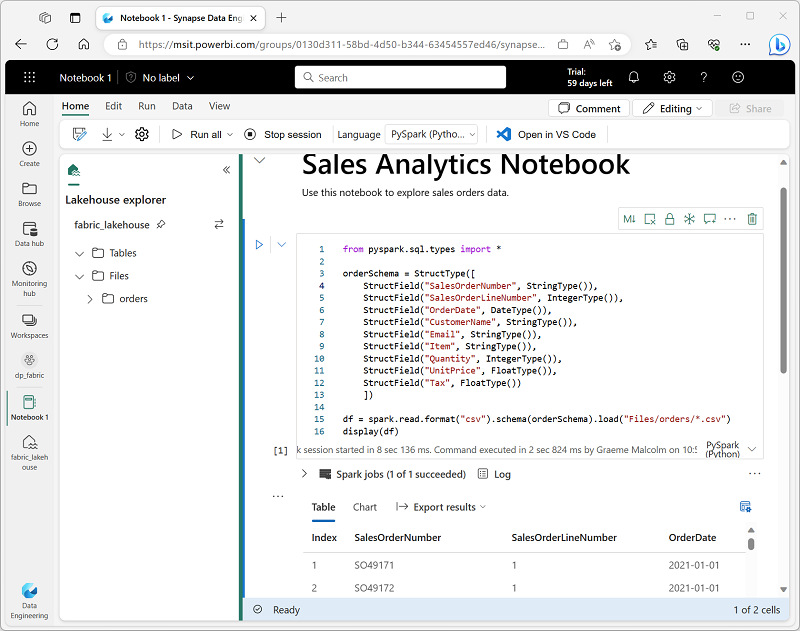
Notebooks consist of one or more cells, each of which can contain markdown-formatted content or executable code. You can run the code interactively in the notebook and see the results immediately.
Code and markdown cells
Notebooks cells contain either code or markdown text, but not both. To convert an existing code cell to markdown, select M. To convert a markdown cell to code, select </>.
Markdown cells include a text toolbar to allow you to format text and add images. The ability to add markdown cells to a notebook is powerful. It allows you to add explanations about your code, document why certain things are being done, why, and what you are trying to achieve. Not only does this feature make a notebook more useful later, but also improves collaboration.
Code languages
PySpark (a Spark-specific implementation of Python) is the default language for Microsoft Fabric notebooks, but you can also select Scala (a Java-based interpreted language)), Spark SQL, or SparkR. Most data engineering and analytics workloads are accomplished using a combination of PySpark and Spark SQL.
You can change the default language for a notebook (affecting all code cells), or you can use a magic command in a cell to override the default language for just that cell. For example, the %%sql magic command in the following code changes the programming language for the cell to Spark SQL:
%%sql
SELECT YEAR(OrderDate) AS OrderYear,
SUM((UnitPrice * Quantity) + Tax) AS GrossRevenue
FROM salesorders
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear;
Use %%pyspark to change the programming language back to PySpark. Or %%spark to change the programming language to Scala. The drop-down menu in the bottom right of the cell can also be used to add a magic command.
Note
Magic commands are case sensitive.
Code in notebook is usually run interactively, either by running individual cells or by running all cells in the notebook. You can also schedule a notebook to be run non-interactively.
Spark job definitions
If you want to use Spark to ingest and transform data as part of an automated process, you can define a Spark job to run a script on-demand or based on a schedule.
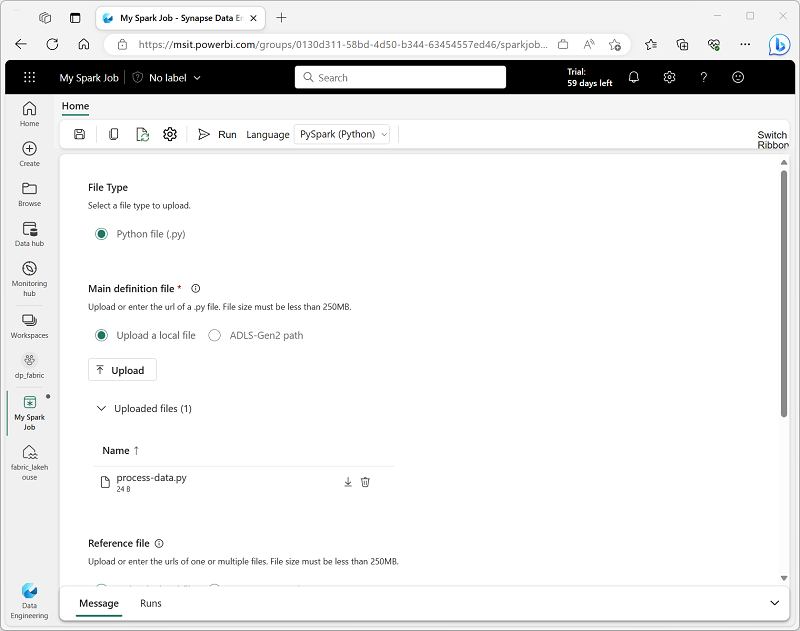
To configure a Spark job, create a Spark Job Definition in your workspace and specify the script it should run. You can also specify a reference file (for example, a Python code file containing definitions of functions that are used in your script) and a reference to a specific lakehouse containing data that the script processes.
You can also specify command line arguments, which enable you to vary the behavior of the script depending on the arguments passed to it. This approach can be useful when the same Spark job will be used in multiple contexts (for example, you could use a single script to load data from files into tables, varying the file path and table name when you run it).
Scheduling notebook and job execution
You can define a schedule for a notebook or Spark job definition to have it run unattended at a specific interval. This approach may be useful for simple automated tasks that can be scripted and which are not part of a more complex data ingestion or processing workload. In most production environments, a more manageable solution is to include the notebook or Spark job definition in a pipeline, where it can be integrated into a more complex orchestration solution.
Note
When you run code in a notebook or a Spark job definition interactively, the code runs in the security context of the currently logged in user. When run using a schedule, the code assumes the identity of the user who created the schedule. When run in a pipeline, the code uses the identity of the user who owns the pipeline.
Regardless of how the code is run, you must ensure that the identity used in the security context has sufficient permissions to access any resources referenced by the code, including tables or files in a lakehouse.