Choose the appropriate compute target
In Azure Machine Learning, compute targets are physical or virtual computers on which jobs are run.
Understand the available types of compute
Azure Machine Learning supports multiple types of compute for experimentation, training, and deployment. By having multiple types of compute, you can select the most appropriate type of compute target for your needs.
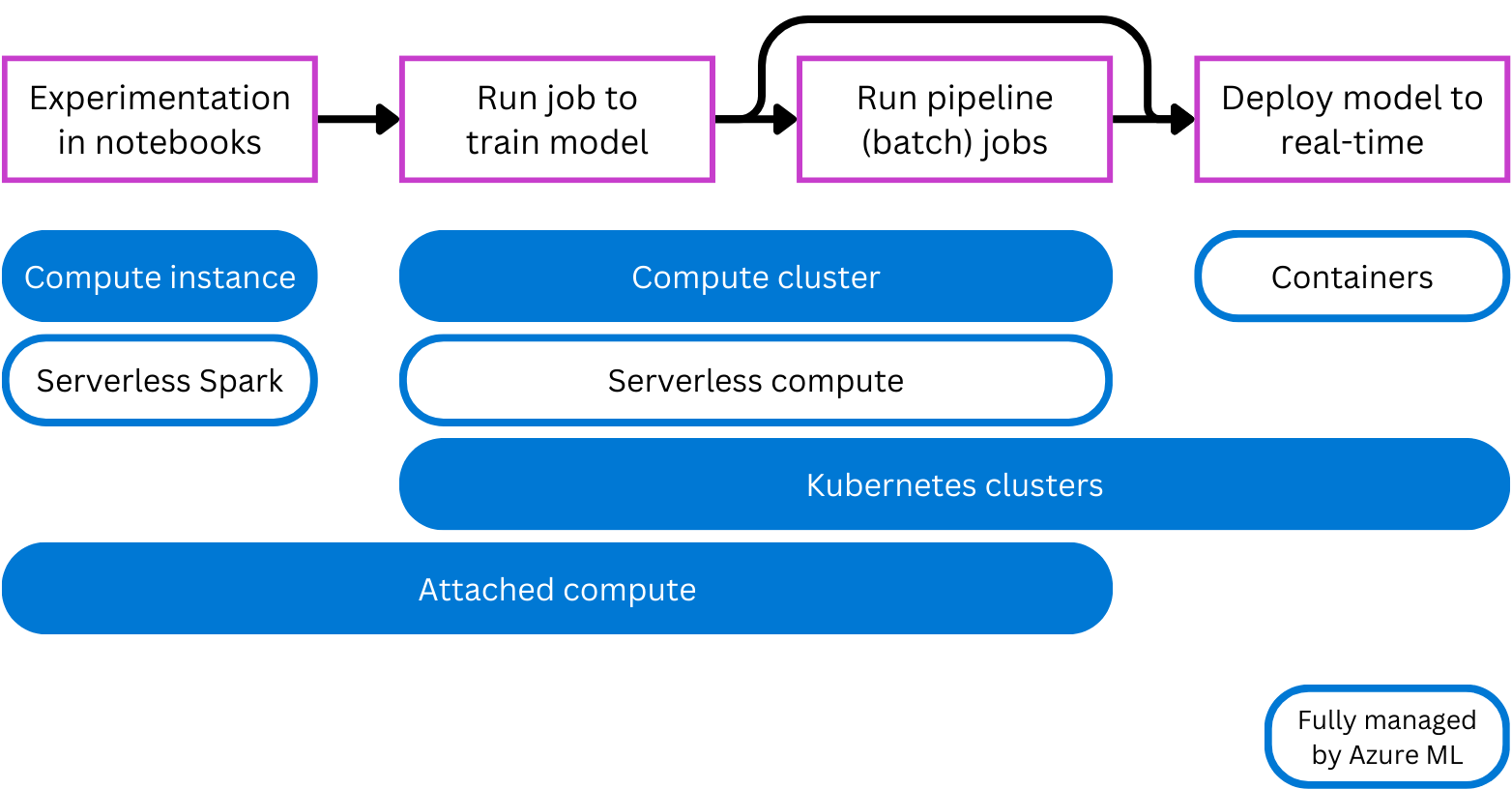
- Compute instance: Behaves similarly to a virtual machine and is primarily used to run notebooks. It's ideal for experimentation.
- Compute clusters: Multi-node clusters of virtual machines that automatically scale up or down to meet demand. A cost-effective way to run scripts that need to process large volumes of data. Clusters also allow you to use parallel processing to distribute the workload and reduce the time it takes to run a script.
- Kubernetes clusters: Cluster based on Kubernetes technology, giving you more control over how the compute is configured and managed. You can attach your self-managed Azure Kubernetes (AKS) cluster for cloud compute, or an Arc Kubernetes cluster for on-premises workloads.
- Attached compute: Allows you to attach existing compute like Azure virtual machines or Azure Databricks clusters to your workspace.
- Serverless compute: A fully managed, on-demand compute you can use for training jobs.
Note
Azure Machine Learning offers you the option to create and manage your own compute or to use compute that is fully managed by Azure Machine Learning.
When to use which type of compute?
In general, there are some best practices that you can follow when working with compute targets. To understand how to choose the appropriate type of compute, several examples are provided. Remember that which type of compute you use always depends on your specific situation.
Choose a compute target for experimentation
Imagine you're a data scientist and you're asked to develop a new machine learning model. You likely have a small subset of the training data with which you can experiment.
During experimentation and development, you prefer working in a Jupyter notebook. A notebook experience benefits most from a compute that is continuously running.
Many data scientists are familiar with running notebooks on their local device. A cloud alternative managed by Azure Machine Learning is a compute instance. Alternatively, you can also opt for Spark serverless compute to run Spark code in notebooks, if you want to make use of Spark's distributed compute power.
Choose a compute target for production
After experimentation, you can train your models by running Python scripts to prepare for production. Scripts will be easier to automate and schedule for when you want to retrain your model continuously over time. You can run scripts as (pipeline) jobs.
When moving to production, you want the compute target to be ready to handle large volumes of data. The more data you use, the better the machine learning model is likely to be.
When training models with scripts, you want an on-demand compute target. A compute cluster automatically scales up when the script(s) need to be executed, and scales down when the script finishes executing. If you want an alternative that you don't have to create and manage, you can use Azure Machine Learning's serverless compute.
Choose a compute target for deployment
The type of compute you need when using your model to generate predictions depends on whether you want batch or real-time predictions.
For batch predictions, you can run a pipeline job in Azure Machine Learning. Compute targets like compute clusters and Azure Machine Learning's serverless compute are ideal for pipeline jobs as they're on-demand and scalable.
When you want real-time predictions, you need a type of compute that is running continuously. Real-time deployments therefore benefit from more lightweight (and thus more cost-efficient) compute. Containers are ideal for real-time deployments. When you deploy your model to a managed online endpoint, Azure Machine Learning creates and manages containers for you to run your model. Alternatively, you can attach Kubernetes clusters to manage the necessary compute to generate real-time predictions.