Tutorial: Primera parte: Creación de un copiloto basado en la RAG con el SDK de flujo de avisos
En este tutorial de Inteligencia artificial de Azure Studio, usará el SDK de flujo de avisos (y otras bibliotecas) para compilar, configurar, evaluar e implementar un copiloto para su empresa minorista denominada Contoso Trek. Su empresa minorista se especializa en ropa y equipo de camping al aire libre. El copiloto debe responder a preguntas sobre sus productos y servicios. Por ejemplo, el copiloto puede responder preguntas como "¿qué tienda es la más impermeable?" o "¿cuál es el mejor saco de dormir para el clima frío?".
Este tutorial es la primera parte de un tutorial de dos partes.
Sugerencia
Asegúrese de reservar tiempo suficiente para reunir los requisitos previos antes de iniciar este tutorial. Si no está familiarizado con Azure AI Studio, es posible que tenga que dedicar más tiempo a conocer la plataforma.
En esta parte se muestra cómo mejorar una aplicación de chat básica mediante la adición de la generación aumentada de recuperación (RAG) para fundamentar las respuestas en los datos personalizados.
En esta primera parte, aprenderá a:
Prerrequisitos
Importante
Debe tener los permisos necesarios para agregar asignaciones de roles en la suscripción de Azure. La concesión de permisos por asignación de roles solo está permitida por el propietario de los recursos específicos de Azure. Es posible que tenga que pedir al propietario de la suscripción de Azure (que sea el administrador de TI) que le ayude a completar la sección de asignación de acceso.
Debe completar la Creación de una aplicación de chat personalizada en Python mediante el inicio rápido del SDK de flujo de avisos para configurar el entorno.
Importante
Este tutorial se basa en el código y el entorno que configuró en el inicio rápido.
Necesita una copia local de los datos del producto. El repositorio Azure-Samples/rag-data-openai-python-promptflow en GitHub contiene información de ejemplo de productos minoristas que es relevante para este escenario. Descargue los datos de productos minoristas de Contoso Trek de ejemplo en un archivo ZIP en la máquina local.
Estructura del código de la aplicación
Cree una carpeta denominada rag-tutorial en el equipo local. En esta serie de tutoriales se explica la creación del contenido de cada archivo. Si completa la serie de tutoriales, la estructura de carpetas tendrá este aspecto:
rag-tutorial/
│ .env
│ build_index.py
│ deploy.py
│ evaluate.py
│ eval_dataset.jsonl
| invoke-local.py
│
├───copilot_flow
│ └─── chat.prompty
| └─── copilot.py
| └─── Dockerfile
│ └─── flow.flex.yaml
│ └─── input_with_chat_history.json
│ └─── queryIntent.prompty
│ └─── requirements.txt
│
├───data
| └─── product-info/
| └─── [Your own data or sample data as described in the prerequisites.]
La implementación de este tutorial usa el flujo flexible del flujo de avisos, que es el enfoque de código primero para implementar flujos. Especifique una función de entrada (que se definirá en copilot.py) y, a continuación, use las funcionalidades de prueba, evaluación y seguimiento del flujo de avisos para el flujo. Este flujo está en el código y no tiene un DAG (Gráfico acíclico dirigido) u otro componente visual. Obtenga más información sobre cómo desarrollar un flujo flexible en la documentación del flujo de avisos en GitHub.
Establecimiento de variables de entorno iniciales
Hay una colección de variables de entorno que se usan en los distintos fragmentos de código. Vamos a establecerlos.
Ha creado un archivo .env con las siguientes variables de entorno a través de la Creación de una aplicación de chat personalizada en Python mediante el inicio rápido del SDK de flujo de avisos. Si aún no lo ha hecho, cree un archivo .env en la carpeta rag-tutorial con las siguientes variables de entorno:
AZURE_OPENAI_ENDPOINT=endpoint_value AZURE_OPENAI_DEPLOYMENT_NAME=chat_model_deployment_name AZURE_OPENAI_API_VERSION=api_versionCopie el archivo .env en la carpeta rag-tutorial.
En el archivo .env escriba más variables de entorno para la aplicación de copiloto:
- AZURE_SUBSCRIPTION_ID: identificador de suscripción de Azure
- AZURE_RESOURCE_GROUP: su grupo de recursos de Azure
- AZUREAI_PROJECT_NAME: nombre del proyecto de Inteligencia artificial de Azure Studio
- AZURE_OPENAI_CONNECTION_NAME: use la misma conexión AIServices o Azure OpenAI que usó para implementar el modelo de chat.
Puede encontrar el identificador de suscripción, el nombre del grupo de recursos y el nombre del proyecto en la vista del proyecto en AI Studio.
- En AI Studio, vaya al proyecto y seleccione Configuración en el panel izquierdo.
- En la sección Detalles del proyecto, puede encontrar el identificador de suscripción y el grupo de recursos.
- En la sección Configuración del proyecto, puede encontrar el nombre del proyecto.
Por ahora, debe tener las siguientes variables de entorno en el archivo .env:
AZURE_OPENAI_ENDPOINT=endpoint_value
AZURE_OPENAI_DEPLOYMENT_NAME=chat_model_deployment_name
AZURE_OPENAI_API_VERSION=api_version
AZURE_SUBSCRIPTION_ID=<your subscription id>
AZURE_RESOURCE_GROUP=<your resource group>
AZUREAI_PROJECT_NAME=<your project name>
AZURE_OPENAI_CONNECTION_NAME=<your AIServices or Azure OpenAI connection name>
Implementación de un modelo de inserción
Para la funcionalidad de generación aumentada de recuperación (RAG), es necesario poder insertar la consulta de búsqueda para buscar en el índice de Búsqueda de Azure AI que creamos.
Implemente un modelo de inserción de Azure OpenAI. Siga la guía implementación de modelos de Azure OpenAI e implemente el modelo text-embedding-ada-002. Use la misma conexión AIServices o Azure OpenAI que usó para implementar el modelo de chat.
Agregue variables de entorno del modelo de inserción en el archivo .env. Para el valor AZURE_OPENAI_EMBEDDING_DEPLOYMENT, escriba el nombre del modelo de inserción que implementó.
AZURE_OPENAI_EMBEDDING_DEPLOYMENT=embedding_model_deployment_name
Para más información sobre el modelo de inserción, consulte la documentación de inserciones de Azure OpenAI Service.
Creación de un índice de Búsqueda de Azure AI
El objetivo con esta aplicación basada en la RAG es fundamentar las respuestas del modelo en los datos personalizados. Use un índice de Búsqueda de Azure AI que almacene datos vectorizados del modelo de inserciones. El índice de búsqueda se usa para recuperar documentos relevantes en función de la pregunta del usuario.
Necesita un servicio y una conexión de Búsqueda de Azure AI para crear un índice de búsqueda.
Nota:
La creación de un servicio de Búsqueda de Azure AI y los índices de búsqueda posteriores tienen costos asociados. Puede ver detalles sobre los planes de tarifa y precios del servicio de Búsqueda de Azure AI en la página de creación para confirmar el costo antes de crear el recurso.
Creación de un servicio de Búsqueda de Azure AI
Si ya tiene un servicio de Búsqueda de Azure AI en la misma ubicación que el proyecto, puede ir directamente a la siguiente sección.
De lo contrario, puede crear un servicio de Búsqueda de Azure AI mediante Azure Portal o la CLI de Azure (que instaló anteriormente para el inicio rápido).
Importante
Use la misma ubicación que el proyecto para el servicio de Búsqueda de Azure AI. Busque la ubicación del proyecto en el selector de proyectos superior derecho de Inteligencia artificial de Azure Studio en la vista del proyecto.
- Vaya a Azure Portal.
- Creación de un servicio de Búsqueda de Azure AI en Azure Portal.
- Seleccione los detalles del grupo de recursos y de la instancia. Puede ver detalles sobre los planes de tarifa y precios en esta página.
- Continúe con el asistente y seleccione Revisar y asignar para crear el recurso.
- Confirme los detalles del servicio de Búsqueda de Azure AI, incluido el costo estimado.
Creación de una conexión de Búsqueda de Azure AI
Si ya tiene una conexión de Búsqueda de Azure AI en el proyecto, puede ir directamente a configurar el acceso para el servicio de Búsqueda de Azure AI. Use solo una conexión existente si se encuentra en la misma ubicación que el proyecto.
En Inteligencia artificial de Azure Studio, compruebe si hay un recurso conectado de Búsqueda de Azure AI.
- En AI Studio, vaya al proyecto y seleccione Configuración en el panel izquierdo.
- En la sección Recursos conectados, busque si tiene una conexión de tipo Búsqueda de Azure AI.
- Si tiene una conexión de Búsqueda de Azure AI, compruebe que se encuentra en la misma ubicación que el proyecto. Si es así, puede ir directamente a configurar el acceso para el servicio de Búsqueda de Azure AI.
- De lo contrario, seleccione Nueva conexión y, a continuación, Búsqueda de Azure AI.
- Busque el servicio de Búsqueda de Azure AI en las opciones y seleccione Agregar conexión.
- Continúe con el asistente para crear la conexión. Para obtener más información sobre cómo agregar conexiones, consulte esta guía paso a paso.
Configuración del acceso para el servicio de Búsqueda de Azure AI
Se recomienda usar Microsoft Entra ID en lugar de usar claves de API. Para usar esta autenticación, debe establecer los controles de acceso adecuados y asignar los roles adecuados para el servicio de Búsqueda de Azure AI.
Advertencia
Puede usar el control de acceso basado en rol localmente porque ejecutará az login más adelante en este tutorial. Pero cuando implementa la aplicación en la segunda parte del tutorial, la implementación se autentica mediante claves de API del servicio de Búsqueda de Azure AI. La compatibilidad con la autenticación de Microsoft Entra ID de la implementación estará disponible próximamente.
Para habilitar el control de acceso basado en rol para el servicio de Búsqueda de Azure AI, siga estos pasos:
En el servicio de Búsqueda de Azure AI de Azure Portal, seleccione Configuración > Claves en el panel izquierdo.
Seleccione Ambos para asegurarse de que las claves de API y el control de acceso basado en roles estén habilitados para el servicio de Búsqueda de Azure AI.
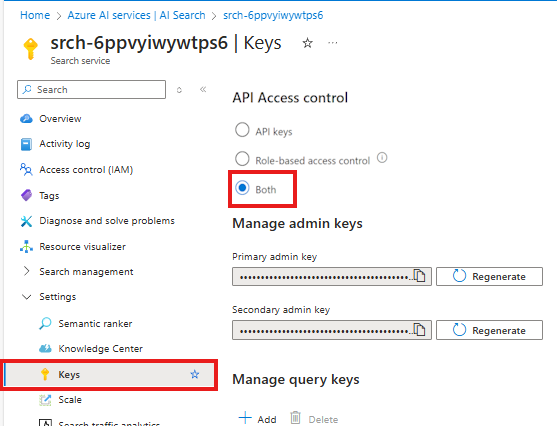
Usted o el administrador deben conceder a la identidad de usuario los roles Colaborador de datos del índice de búsqueda y Colaborador del servicio de búsqueda en el servicio de Búsqueda de Azure AI. Estos roles le permiten llamar al servicio de Búsqueda de Azure AI mediante su identidad de usuario.
Nota:
Estos pasos son similares a la forma en que asignó un rol a la identidad de usuario para usar Azure OpenAI Service en el inicio rápido.
En Azure Portal, siga estos pasos para asignar el rol Colaborador de datos del índice de búsqueda al servicio de Búsqueda de Azure AI:
- Seleccione el servicio de Búsqueda de Azure AI en Azure Portal.
- En la página izquierda de Azure Portal, seleccione Control de acceso (IAM)>+ Agregar>Agregar asignación de roles.
- Busque el rol Colaborador de datos del índice de búsqueda y, a continuación, selecciónelo. Luego, seleccione Siguiente.
- Seleccione Usuario, grupo o entidad de servicio. A continuación, seleccione Seleccionar miembros.
- En el panel Seleccionar miembros que se abre, busque el nombre del usuario para el que desea agregar la asignación de roles. Seleccione el usuario y luego seleccione Seleccionar.
- Continúe con el asistente y seleccione Revisar + asignar para agregar la asignación de roles.
Repita los pasos anteriores para agregar el rol Colaborador del servicio de búsqueda.
Importante
Después de asignar estos roles, ejecute az login en la consola para asegurarse de que los cambios se propagan en el entorno de desarrollo. Esto también garantiza que puede usar la identidad de usuario localmente para autenticarse con el servicio de Búsqueda de Azure AI.
Establecimiento de variables de entorno de búsqueda
Debe establecer variables de entorno para el servicio de Búsqueda de Azure AI y la conexión en el archivo .env.
En AI Studio, vaya al proyecto y seleccione Configuración en el panel izquierdo.
En la sección Recursos conectados, seleccione el vínculo para el servicio de Búsqueda de Azure AI que creó anteriormente.
Copie la dirección URL de destino para
<your Azure Search endpoint>.Copie el nombre en la parte superior de
<your Azure Search connection name>.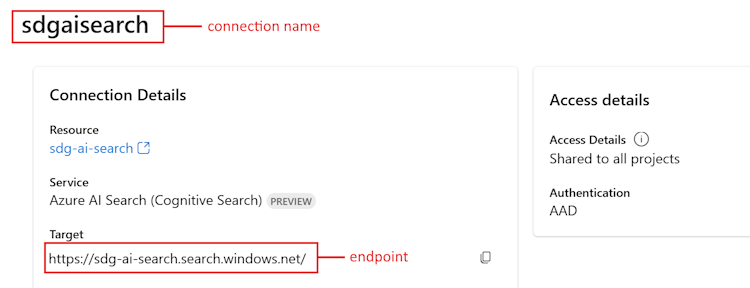
Agregue estas variables de entorno al archivo .env:
AZURE_SEARCH_ENDPOINT=<your Azure Search endpoint> AZURE_SEARCH_CONNECTION_NAME=<your Azure Search connection name>
Creación del índice de búsqueda
Si aún no tiene un índice de Búsqueda de Azure AI creado, se explica cómo crear uno. Si ya tiene un índice que se va a usar, puede ir a la secciónEstablecer las variables de entorno de búsqueda. El índice de búsqueda se crea en el servicio de Búsqueda de Azure AI que se ha creado o al que se hace referencia en el paso anterior.
Use sus propios datos o descargue los datos del ejemplo de productos minoristas de Contoso Trek de ejemplo en un archivo ZIP en la máquina local. Descomprima el archivo en la carpeta rag-tutorial. Estos datos son una colección de archivos de Markdown que representan información del producto. Los datos se estructuran de forma fácil de ingerir en un índice de búsqueda. Cree un índice de búsqueda a partir de estos datos.
El paquete de RAG de flujo de avisos permite ingerir los archivos de Markdown, crear localmente un índice de búsqueda y registrarlo en el proyecto en la nube. Instale el paquete RAG del flujo de avisos:
pip install promptflow-ragActualice el paquete azure-ai-ml a la versión más reciente. Ejecute el siguiente comando en el terminal:
pip install azure-ai-ml -UCree el archivo build_index.py en la carpeta rag-tutorial.
Copie y pegue el siguiente código en el archivo build_index.py.
import os from dotenv import load_dotenv load_dotenv() from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential from azure.ai.ml.entities import Index from promptflow.rag.config import ( LocalSource, AzureAISearchConfig, EmbeddingsModelConfig, ConnectionConfig, ) from promptflow.rag import build_index client = MLClient( DefaultAzureCredential(), os.getenv("AZURE_SUBSCRIPTION_ID"), os.getenv("AZURE_RESOURCE_GROUP"), os.getenv("AZUREAI_PROJECT_NAME"), ) import os # append directory of the current script to data directory script_dir = os.path.dirname(os.path.abspath(__file__)) data_directory = os.path.join(script_dir, "data/product-info/") # Check if the directory exists if os.path.exists(data_directory): files = os.listdir(data_directory) # List all files in the directory if files: print( f"Data directory '{data_directory}' exists and contains {len(files)} files." ) else: print(f"Data directory '{data_directory}' exists but is empty.") exit() else: print(f"Data directory '{data_directory}' does not exist.") exit() index_name = "tutorial-index" # your desired index name index_path = build_index( name=index_name, # name of your index vector_store="azure_ai_search", # the type of vector store - in this case it is Azure AI Search. Users can also use "azure_cognitive search" embeddings_model_config=EmbeddingsModelConfig( model_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), deployment_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_OPENAI_CONNECTION_NAME"), ), ), input_source=LocalSource(input_data=data_directory), # the location of your files index_config=AzureAISearchConfig( ai_search_index_name=index_name, # the name of the index store inside the azure ai search service ai_search_connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_SEARCH_CONNECTION_NAME"), ), ), tokens_per_chunk=800, # Optional field - Maximum number of tokens per chunk token_overlap_across_chunks=0, # Optional field - Number of tokens to overlap between chunks ) # register the index so that it shows up in the cloud project client.indexes.create_or_update(Index(name=index_name, path=index_path))- Establezca la variable
index_nameen el nombre del índice que desee. - Según sea necesario, puede actualizar la variable
path_to_dataa la ruta de acceso donde se almacenan los archivos de datos.
Importante
De forma predeterminada, el ejemplo de código espera la estructura de código de la aplicación como se describe anteriormente en este tutorial. La carpeta
datadebe estar en el mismo nivel que el build_index.py y la carpetaproduct-infodescargada con archivos md dentro de ella.- Establezca la variable
Desde la consola, ejecute el código para compilar el índice localmente y registrarlo en el proyecto en la nube:
python build_index.pyUna vez ejecutado el script, puede ver el índice recién creado en la página Índices del proyecto de Inteligencia artificial de Azure Studio. Para obtener más información, consulte Cómo compilar y consumir índices vectoriales en Inteligencia artificial de Azure Studio.
Si vuelve a ejecutar el script con el mismo nombre de índice, crea una nueva versión del mismo índice.
Establecimiento de la variable de entorno de índice de búsqueda
Una vez que tenga el nombre de índice que desea usar (ya sea creando uno nuevo o haciendo referencia a uno existente), agréguelo al archivo .env, de la siguiente manera:
AZUREAI_SEARCH_INDEX_NAME=<index-name>
Desarrollo de código de RAG personalizado
A continuación, cree código personalizado para agregar funcionalidades de generación aumentada de recuperación (RAG) a una aplicación de chat básica. En el inicio rápido, creó los archivos chat.py y chat.prompty. Aquí expandirá ese código para incluir funcionalidades de RAG.
El copiloto con la RAG implementa la siguiente lógica general:
- Genere una consulta de búsqueda basada en la intención de consulta de usuario y cualquier historial de chat
- Use un modelo de inserción para insertar la consulta
- Recupere documentos pertinentes del índice de búsqueda, dada la consulta
- Pase el contexto pertinente al modelo de finalización del chat de Azure OpenAI
- Devuelva la respuesta del modelo de Azure OpenAI
La lógica de implementación de un copiloto
La lógica de implementación del copiloto está en el archivo copilot.py. Este archivo contiene la lógica principal del copiloto basado en la RAG.
Cree una carpeta denominada copilot_flow en la carpeta rag-tutorial.
A continuación, cree un archivo denominado copilot.py en la carpeta copilot_flow.
Agregue el código siguiente al archivo copilot.py:
import os from dotenv import load_dotenv load_dotenv() from promptflow.core import Prompty, AzureOpenAIModelConfiguration from promptflow.tracing import trace from openai import AzureOpenAI # <get_documents> @trace def get_documents(search_query: str, num_docs=3): from azure.identity import DefaultAzureCredential, get_bearer_token_provider from azure.search.documents import SearchClient from azure.search.documents.models import VectorizedQuery token_provider = get_bearer_token_provider( DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default" ) index_name = os.getenv("AZUREAI_SEARCH_INDEX_NAME") # retrieve documents relevant to the user's question from Cognitive Search search_client = SearchClient( endpoint=os.getenv("AZURE_SEARCH_ENDPOINT"), credential=DefaultAzureCredential(), index_name=index_name, ) aoai_client = AzureOpenAI( azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_ad_token_provider=token_provider, api_version=os.getenv("AZURE_OPENAI_API_VERSION"), ) # generate a vector embedding of the user's question embedding = aoai_client.embeddings.create( input=search_query, model=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT") ) embedding_to_query = embedding.data[0].embedding context = "" # use the vector embedding to do a vector search on the index vector_query = VectorizedQuery( vector=embedding_to_query, k_nearest_neighbors=num_docs, fields="contentVector" ) results = trace(search_client.search)( search_text="", vector_queries=[vector_query], select=["id", "content"] ) for result in results: context += f"\n>>> From: {result['id']}\n{result['content']}" return context # <get_documents> from promptflow.core import Prompty, AzureOpenAIModelConfiguration from pathlib import Path from typing import TypedDict class ChatResponse(TypedDict): context: dict reply: str def get_chat_response(chat_input: str, chat_history: list = []) -> ChatResponse: model_config = AzureOpenAIModelConfiguration( azure_deployment=os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) searchQuery = chat_input # Only extract intent if there is chat_history if len(chat_history) > 0: # extract current query intent given chat_history path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/queryIntent.prompty" # pass absolute file path to prompty intentPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": { "max_tokens": 256, }, }, ) searchQuery = intentPrompty(query=chat_input, chat_history=chat_history) # retrieve relevant documents and context given chat_history and current user query (chat_input) documents = get_documents(searchQuery, 3) # send query + document context to chat completion for a response path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/chat.prompty" chatPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": {"max_tokens": 256, "temperature": 0.2}, }, ) result = chatPrompty( chat_history=chat_history, chat_input=chat_input, documents=documents ) return dict(reply=result, context=documents)
El archivo copilot.py contiene dos funciones clave: get_documents() y get_chat_response().
Observe que estas dos funciones tienen el decorador @trace, lo que le permite ver los registros de seguimiento de flujo de avisos de cada entrada y salida de llamada de función. @trace es un enfoque alternativo y extendido de la forma en que el inicio rápido mostraba las funcionalidades de seguimiento.
La función get_documents() es el núcleo de la lógica de RAG.
- Toma la consulta de búsqueda y el número de documentos que se van a recuperar.
- Inserta la consulta de búsqueda mediante un modelo de inserción.
- Consulta el índice de Azure Search para recuperar los documentos pertinentes para la consulta.
- Devuelve el contexto de los documentos.
La función get_chat_response() se compila a partir de la lógica anterior en el archivo chat.py:
- Toma el
chat_inputy cualquierchat_history. - Construye la consulta de búsqueda basada en intención
chat_inputychat_history. - Llama a
get_documents()para recuperar los documentos pertinentes. - Llama al modelo de finalización de chat con contexto para obtener una respuesta fundamentada a la consulta.
- Devuelve la respuesta y el contexto. Establecemos un diccionario tipado como objeto devuelto para nuestra función
get_chat_response(). Puede elegir cómo el código devuelve la respuesta para adaptarse mejor a su caso de uso.
La función get_chat_response() usa dos archivos Prompty para realizar las llamadas necesarias al modelo de lenguaje grande (LLM), que veremos a continuación.
Solicitud de plantilla para chat
El archivo chat.prompty es sencillo y similar al chat.prompty en el inicio rápido. La solicitud del sistema se actualiza para reflejar nuestro producto y las plantillas de aviso incluyen el contexto del documento.
Agregue el archivo chat.prompty en el directorio copilot_flow. El archivo representa la llamada al modelo de finalización del chat, con el símbolo del sistema, el historial de chat y el contexto del documento proporcionados.
Agregue este código al archivo chat.prompty:
--- name: Chat Prompt description: A prompty that uses the chat API to respond to queries grounded in relevant documents model: api: chat configuration: type: azure_openai inputs: chat_input: type: string chat_history: type: list is_chat_history: true default: [] documents: type: object --- system: You are an AI assistant helping users with queries related to outdoor outdooor/camping gear and clothing. If the question is not related to outdoor/camping gear and clothing, just say 'Sorry, I only can answer queries related to outdoor/camping gear and clothing. So, how can I help?' Don't try to make up any answers. If the question is related to outdoor/camping gear and clothing but vague, ask for clarifying questions instead of referencing documents. If the question is general, for example it uses "it" or "they", ask the user to specify what product they are asking about. Use the following pieces of context to answer the questions about outdoor/camping gear and clothing as completely, correctly, and concisely as possible. Do not add documentation reference in the response. # Documents {{documents}} {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} user: {{chat_input}}
Plantilla de solicitud para el historial de chats
Dado que estamos implementando una aplicación basada en la RAG, se requiere cierta lógica adicional para recuperar documentos relevantes no solo para la consulta actual del usuario, sino también teniendo en cuenta el historial de chat. Sin esta lógica adicional, la llamada al LLM tendría en cuenta el historial de chats. Pero no recuperaría los documentos adecuados para ese contexto, por lo que no obtendría la respuesta esperada.
Por ejemplo, si el usuario hace la pregunta "¿es impermeable?", necesitamos que el sistema examine el historial de chat para determinar a qué se refiere la palabra "es" e incluir ese contexto en la consulta de búsqueda que se va a insertar. De este modo, recuperamos los documentos adecuados para "es" (quizás la tienda de campaña Alpine Explorer) y su "costo".
En lugar de pasar solo la consulta del usuario para que se inserte, es necesario generar una nueva consulta de búsqueda que tenga en cuenta cualquier historial de chat. Usamos otro Prompty (que es otra llamada LLM) con una solicitud específica para interpretar la intención de consulta del usuario dado el historial de chat y construir una consulta de búsqueda que tenga el contexto necesario.
Cree el archivo queryIntent.prompty en la carpeta copilot_flow.
Escriba este código para obtener detalles específicos sobre el formato de la pregunta y ejemplos de pocas palabras.
--- name: Chat Prompt description: A prompty that extract users query intent based on the current_query and chat_history of the conversation model: api: chat configuration: type: azure_openai inputs: query: type: string chat_history: type: list is_chat_history: true default: [] --- system: - You are an AI assistant reading a current user query and chat_history. - Given the chat_history, and current user's query, infer the user's intent expressed in the current user query. - Once you infer the intent, respond with a search query that can be used to retrieve relevant documents for the current user's query based on the intent - Be specific in what the user is asking about, but disregard parts of the chat history that are not relevant to the user's intent. Example 1: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." } ] \``` User query: "how much do they cost?" Intent: "The user wants to know how much the Trailwalker Hiking Shoes cost." Search query: "price of Trailwalker Hiking Shoes" Example 2: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." }, { "role": "user", "content": "how much do they cost?" }, { "role": "assistant", "content": "The TrailWalker Hiking Shoes are priced at $110." }, { "role": "user", "content": "do you have waterproof tents?" }, { "role": "assistant", "content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?" }, { "role": "user", "content": "which is your most waterproof tent?" }, { "role": "assistant", "content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture." } ] \``` User query: "how much does it cost?" Intent: "the user would like to know how much the Alpine Explorer Tent costs" Search query: "price of Alpine Explorer Tent" {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} Current user query: {{query}} Search query:
El sencillo mensaje del sistema de nuestro archivo queryIntent.prompty logra el mínimo necesario para que la solución de RAG funcione con el historial de chat.
Configuración de paquetes necesarios
Cree el archivo requirements.txt en la carpeta copilot_flow. Agregue este contenido:
openai
azure-identity
azure-search-documents==11.4.0
promptflow[azure]==1.11.0
promptflow-tracing==1.11.0
promptflow-tools==1.4.0
promptflow-evals==0.3.0
jinja2
aiohttp
python-dotenv
Estos son los paquetes necesarios para que el flujo se ejecute localmente y en un entorno implementado.
Uso del flujo flexible
Como se mencionó anteriormente, esta implementación usa el flujo flexible del flujo de avisos, que es el enfoque primero en el código para implementar flujos. Especifique una función de entrada (que se define en copilot.py). Obtenga más información en Desarrollo de un flujo flexible.
Este YAML especifica la función de entrada, que es la función get_chat_response definida en copilot.py. También especifica los requisitos que debe ejecutar el flujo.
Cree el archivo flow.flex.yaml en la carpeta copilot_flow. Agregue este contenido:
entry: copilot:get_chat_response
environment:
python_requirements_txt: requirements.txt
Uso del flujo de avisos para probar el copiloto
Use la funcionalidad de prueba del flujo de avisos para ver cómo funciona el copiloto según lo previsto en las entradas de ejemplo. Con el archivo flow.flex.yaml, puede usar el flujo de avisos para probar con las entradas especificadas.
Ejecute el flujo mediante este comando de flujo de avisos:
pf flow test --flow ./copilot_flow --inputs chat_input="how much do the Trailwalker shoes cost?"
Como alternativa, puede ejecutar el flujo de forma interactiva con la marca --ui.
pf flow test --flow ./copilot_flow --ui
Al usar --ui, la experiencia interactiva de chat de ejemplo abre una ventana en el explorador local.
- La primera vez que se ejecuta con la marca
--ui, es necesario seleccionar manualmente las entradas y salidas del chat en las opciones. La primera vez que cree esta sesión, seleccione Configuración del campo de entrada y salida del chat y, a continuación, comience a chatear. - La próxima vez que se ejecute con la marca
--ui, la sesión recordará la configuración.

Cuando haya terminado con la sesión interactiva, escriba Ctrl + C en la ventana del terminal para detener el servidor.
Prueba con historial de chat
En general, el flujo de avisos y los Prompty admiten el historial de chats. Si prueba con la marca --ui en el front-end servido localmente, el flujo de avisos administra el historial del chat. Si prueba sin el --ui, puede especificar un archivo de entradas que incluya el historial de chat.
Dado que nuestra aplicación implementa la RAG, teníamos que agregar lógica adicional para controlar el historial de chat en el archivo queryIntent.prompty.
Para probar con el historial de chat, cree un archivo denominado input_with_chat_history.json en la carpeta copilot_flow y pegue este contenido:
{
"chat_input": "how much does it cost?",
"chat_history": [
{
"role": "user",
"content": "are the trailwalker shoes waterproof?"
},
{
"role": "assistant",
"content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions."
},
{
"role": "user",
"content": "how much do they cost?"
},
{
"role": "assistant",
"content": "The TrailWalker Hiking Shoes are priced at $110."
},
{
"role": "user",
"content": "do you have waterproof tents?"
},
{
"role": "assistant",
"content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?"
},
{
"role": "user",
"content": "which is your most waterproof tent?"
},
{
"role": "assistant",
"content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture."
}
]
}
Para probar con este archivo, ejecute:
pf flow test --flow ./copilot_flow --inputs ./copilot_flow/input_with_chat_history.json
La salida esperada es similar a: "La tienda de campaña Alpine Explorer tiene un precio de 350 USD".
Este sistema puede interpretar la intención de la consulta "¿Cuánto cuesta esto?" para saber que "esto" hace referencia a la tienda de campaña Alpine Explorer, que era el contexto más reciente del historial de chat. A continuación, el sistema construye una consulta de búsqueda para el precio de la tienda de campaña Alpine Explorer para recuperar los documentos pertinentes para el costo de la tienda de campaña Alpine Explorer y obtenemos la respuesta.
Si va al seguimiento desde esta ejecución de flujo, verá esto en acción. El vínculo de seguimientos locales muestra en la salida de la consola anterior el resultado de la ejecución de la prueba de flujo.

Limpieza de recursos
Para evitar incurrir en costos innecesarios de Azure, debe eliminar los recursos que creó en este tutorial si ya no son necesarios. Para administrar recursos, puede usar Azure Portal.
Pero aún no los elimine, si quiere implementar su copiloto en Azure en la siguiente parte de esta serie de tutoriales.