¿Qué es un lago de datos?
Un lago de datos es un repositorio de almacenamiento que contiene una gran cantidad de datos en su formato nativo y sin procesar. Los lagos de datos están optimizados para escalar a terabytes y petabytes de datos. Los datos provienen normalmente de varios orígenes y pueden incluir datos estructurados, semiestructurados o no estructurados. Un lago de datos le ayuda a almacenar todo en su estado original, no transformado. Este método difiere del almacenamiento de datos tradicional, que transforma y procesa los datos en el momento de la ingesta.
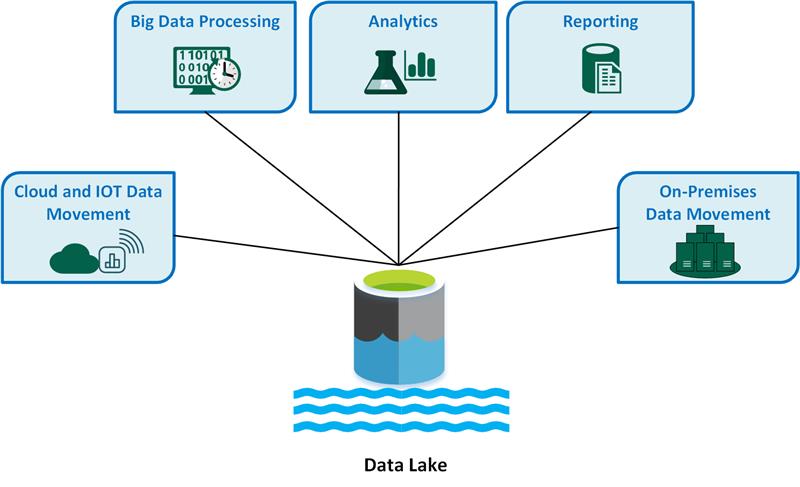
Entre los casos de uso clave de lagos de datos se incluyen:
- Movimiento de datos en la nube e Internet de las cosas (IoT).
- Procesamiento de macrodatos.
- Análisis.
- Generación de informes.
- Movimiento de datos locales.
Tenga en cuenta las siguientes ventajas de un lago de datos:
Un lago de datos nunca elimina los datos porque almacena los datos en su formato sin procesar. Esta función es especialmente útil en un entorno de macrodatos, porque puede que no se conozca de antemano qué información puede obtener a partir de los datos.
Los usuarios pueden explorar los datos y crear sus propias consultas.
Un lago de datos puede ser más rápido que las herramientas tradicionales de extracción, transformación y carga (ETL).
Un lago de datos es más flexible que un almacenamiento de datos, porque puede almacenar datos no estructurados y semiestructurados.
Una solución completa de lagos de datos consta de almacenamiento y procesamiento. El almacenamiento del lago de datos está diseñado para la tolerancia a errores, una escalabilidad infinita e ingesta de datos de alto rendimiento con diferentes formas y tamaños. El procesamiento del lago de datos implica uno o varios motores de procesamiento que pueden incorporar estos objetivos y pueden operar en los datos almacenados en un lago de datos a escala.
Cuándo debe usar un lago de datos
Le recomendamos que utilice un lago de datos para la exploración de datos, el análisis de datos y el aprendizaje automático.
Un lago de datos puede actuar como origen de datos para un almacenamiento de datos. Cuando se utiliza este método, el lago de datos ingiere datos sin procesar y, a continuación, los transforma en un formato estructurado que se puede consultar. Normalmente, esta transformación usa una canalización de extracción, carga y transformación (ELT), donde los datos se ingieren y se transforman en su lugar. Los datos de origen relacional pueden ir directamente al almacén de datos a través de un proceso ETL y omitir el lago de datos.
Puede usar almacenes del lago de datos en streaming de eventos o en escenarios de IoT, porque pueden guardar grandes cantidades de datos relacionales y no relacionales sin transformación o definición de esquema. Los lagos de datos pueden controlar grandes volúmenes de pequeñas operaciones de escritura en una latencia baja y se optimizan para que el rendimiento sea masivo.
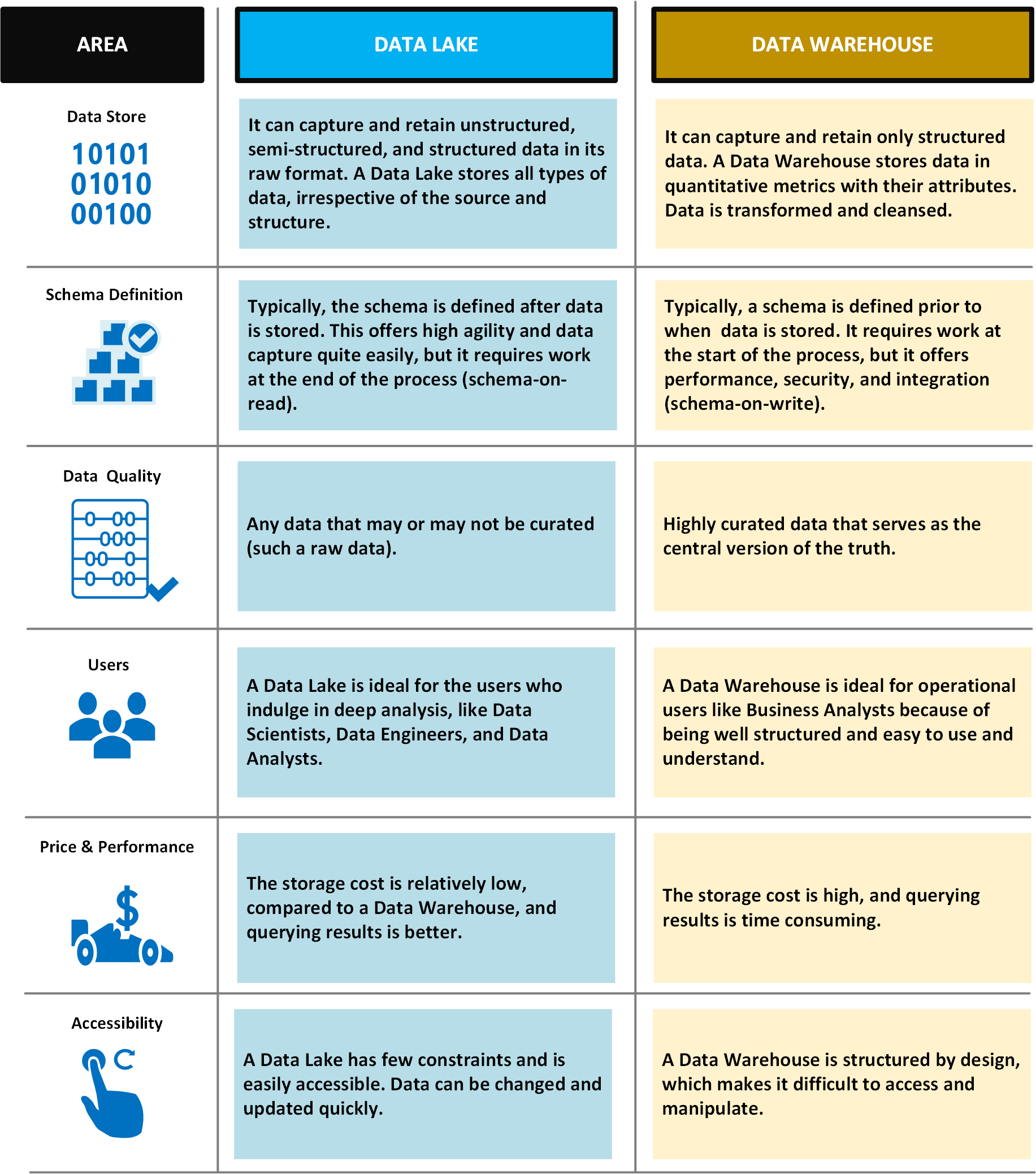
En la tabla siguiente se comparan lagos de datos y almacenamientos de datos.
Desafíos
Grandes volúmenes de datos: la administración de grandes cantidades de datos sin procesar y no estructurados puede ser compleja e intensiva en recursos, por lo que necesita una infraestructura y herramientas sólidas.
Posibles cuellos de botella: el procesamiento de datos puede introducir retrasos e ineficiencias, especialmente cuando tiene grandes volúmenes de datos y diversos tipos de datos.
Riesgos de daños en los datos: la validación y la supervisión incorrectas de datos presentan un riesgo de daños en los datos, lo que puede poner en peligro la integridad del lago de datos.
Problemas de control de calidad: la calidad de los datos adecuada es un desafío debido a la variedad de orígenes de datos y formatos. Debe implementar estrictas prácticas de gobernanza de datos.
Problemas de rendimiento: el rendimiento de las consultas puede degradarse a medida que crece el lago de datos, por lo que debe optimizar las estrategias de almacenamiento y procesamiento.
Opciones de tecnología
Al crear una solución completa de lago de datos en Azure, tenga en cuenta las siguientes tecnologías:
Azure Data Lake Storage combina Azure Blob Storage con funcionalidades de lago de datos, que proporciona acceso compatible con Apache Hadoop, funcionalidades jerárquicas de espacio de nombres y seguridad mejorada para un análisis eficaz de macrodatos.
Azure Databricks es una plataforma unificada que puede usar para procesar, almacenar, analizar y monetizar datos. Admite procesos ETL, paneles, seguridad, exploración de datos, aprendizaje automático e inteligencia artificial generativa.
Azure Synapse Analytics es un servicio unificado que puede usar para ingerir, explorar, preparar, transformar, administrar y servir datos para necesidades inmediatas de inteligencia empresarial y aprendizaje automático. Se integra profundamente con los lagos de datos de Azure para que pueda consultar y analizar grandes conjuntos de datos de forma eficaz.
Azure Data Factory es un servicio de integración de datos basado en la nube que puede usar para crear flujos de trabajo basados en datos, con el fin de orquestar y automatizar el movimiento y la transformación de datos.
Microsoft Fabric es una plataforma de datos completa que unifica la ingeniería de datos, la ciencia de datos, el almacenamiento de datos, el análisis en tiempo real y la inteligencia empresarial en una única solución.
Colaboradores
Microsoft mantiene este artículo. Originalmente lo escribieron los siguientes colaboradores.
Autor principal:
- Avijit Prasad | Consultor de la nube
Para ver los perfiles no públicos de LinkedIn, inicie sesión en LinkedIn.
Pasos siguientes
- ¿Qué es OneLake?
- Introducción a Data Lake Storage
- Documentación de Azure Data Lake Analytics
- Formación: Introducción a Azure Data Lake Storage
- Integración de Hadoop y Azure Data Lake Storage
- Conexión a Data Lake Storage y Blob Storage
- Carga de datos en Data Lake Storage con Azure Data Factory