CQRS significa segregación de responsabilidades de comandos y consultas, un patrón que separa las operaciones de lectura y actualización de un almacén de datos. La implementación de CQRS en la aplicación puede maximizar el rendimiento, la escalabilidad y la seguridad. La flexibilidad creada al migrar a CQRS permite que un sistema evolucione mejor con el tiempo y evita que los comandos de actualización provoquen conflictos de combinación en el nivel de dominio.
Contexto y problema
En las arquitecturas tradicionales, se utiliza el mismo modelo de datos para consultar y actualizar una base de datos. Es sencillo y funciona bien para las operaciones CRUD básicas. Sin embargo, en aplicaciones más complejas, este enfoque puede resultar difícil de manejar. Por ejemplo, en el lado de lectura, la aplicación puede realizar muchas consultas diferentes y devolver objetos de transferencia de datos (DTO) con distintas formas. La asignación de objetos puede llegar a ser algo complicado. En el lado de escritura, el modelo puede implementar una validación y una lógica de negocios complejas. En consecuencia, puede acabar con un modelo excesivamente complejo que haga demasiado.
Las cargas de trabajo de lectura y escritura suelen ser asimétricas, con requisitos de rendimiento y escalabilidad muy diferentes.
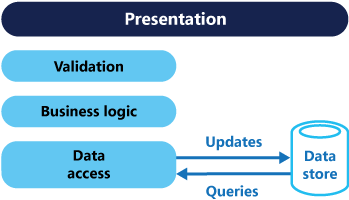
A menudo hay una incoherencia entre las representaciones de lectura y escritura de los datos, como columnas o propiedades adicionales que se deben actualizar correctamente incluso aunque no sean necesarias como parte de una operación.
La contención de datos puede producirse cuando las operaciones se realizan en paralelo en el mismo conjunto de datos.
El enfoque tradicional puede tener un impacto negativo en el rendimiento debido a la carga en el almacén de datos y al nivel de acceso a los datos, y la complejidad de las consultas necesarias para recuperar la información.
Esto puede hacer que la administración de la seguridad y los permisos se vuelva más compleja ya que cada entidad está sujeta a operaciones de lectura y de escritura, lo cual podría exponer los datos en el contexto equivocado.
Solución
CQRS separa las lecturas y las escrituras en diferentes modelos, usa comandos para actualizar los datos y consultas para leer los datos.
- Los comandos se deben basar en tareas, en lugar de centrarse en los datos. ("Book hotel room", no "set ReservationStatus to Reserved"). Esto puede requerir algunos cambios correspondientes en el estilo de interacción del usuario. La otra parte de esto es examinar la modificación de la lógica de negocios que procesa esos comandos para que se realicen correctamente con más frecuencia. Una técnica que admite esto es ejecutar algunas reglas de validación en el cliente incluso antes de enviar el comando, posiblemente deshabilitar botones, explicando por qué en la interfaz de usuario ("no quedan salas"). De esta manera, la causa de los errores de comandos del lado servidor se puede restringir a las condiciones de carrera (dos usuarios que intentan reservar la última sala), e incluso las que a veces se pueden solucionar con algunos datos y lógicas más (colocando a un invitado en una lista de espera).
- Los comandos se pueden colocar en una cola para su procesamiento asincrónico, en lugar de procesarse sincrónicamente.
- Las consultas nunca modifican la base de datos. Una consulta devuelve un DTO que no encapsula ningún conocimiento del dominio.
Posteriormente, se pueden aislar los modelos, como se indica en este diagrama, aunque eso no es un requisito imprescindible.

Tener modelos de consulta y de actualización independientes simplifica el diseño y la implementación. Sin embargo, una desventaja es que el código CQRS no se puede generar automáticamente a partir de un esquema de base de datos mediante mecanismos de scaffolding como herramientas de O/RM (sin embargo, podrá crear la personalización sobre el código generado).
Para lograr un mayor aislamiento, puede separar físicamente los datos de lectura de los datos de escritura. En ese caso, la base de datos de lectura puede utilizar su propio esquema de datos que está optimizado para las consultas. Por ejemplo, puede almacenar una vista materializada de los datos para evitar combinaciones complejas o asignaciones del asignador relacional de objetos complejas. Incluso puede usar un tipo de almacén de datos diferente. Por ejemplo, la base de datos de escritura puede ser relacional, mientras que la base de datos de lectura es una base de datos de documentos.
Si se utilizan bases de datos de escritura y de lectura independientes, se deben mantener sincronizados. Normalmente esto se consigue haciendo que el modelo de escritura publique un evento cada vez que actualiza la base de datos. Para más información sobre el uso de eventos, consulte Estilo de arquitectura basada en eventos. Dado que los agentes de mensajes y las bases de datos normalmente no se pueden inscribir en una sola transacción distribuida, puede haber desafíos para garantizar la coherencia al actualizar la base de datos y publicar eventos. Para obtener más información, consulte la guía sobre el procesamiento de mensajes idempotentes.

El almacén de lectura puede ser una réplica de solo lectura del almacén de escritura o los almacenes de lectura y escritura pueden tener una estructura diferente por completo. El uso de varias réplicas de solo lectura puede aumentar el rendimiento de las consultas, especialmente en escenarios distribuidos en los que las réplicas de solo lectura se encuentran cerca de las instancias de la aplicación.
La separación de los almacenes de lectura y escritura permite también que cada uno de ellos pueda escalarse adecuadamente para adaptarse a la carga. Por ejemplo, los almacenes de lectura normalmente se encuentran con una carga mayor que los de escritura.
Algunas implementaciones de CQRS utilizan el patrón Event Sourcing. Con este patrón, el estado de la aplicación se almacena como una secuencia de eventos. Cada evento representa un conjunto de cambios en los datos. El estado actual se construye mediante la reproducción de los eventos. En un contexto de CQRS, una ventaja de Event Sourcing es que se pueden utilizar los mismos eventos para notificar otros componentes, en particular, para notificar el modelo de lectura. El modelo de lectura utiliza los eventos para crear una instantánea del estado actual, que es más eficaz para las consultas. Sin embargo, Event Sourcing agrega complejidad al diseño.
Estas son algunas ventajas de CQRS:
- Escalado independiente. CQRS permite las cargas de trabajo de lectura y escritura que se escalen de forma independiente, lo que puede dar lugar a menos contenciones de bloqueo.
- Esquemas de datos optimizados. El lado de lectura puede usar un esquema que está optimizado para las consultas, mientras que el lado de escritura utiliza un esquema que está optimizado para las actualizaciones.
- Seguridad. Es más fácil asegurarse de que solo las entidades de dominio correctas realicen escrituras en los datos.
- Separación de cuestiones. La separación de los lados de lectura y escritura puede dar lugar a modelos que sean más flexibles y fáciles de mantener. La mayor parte de la lógica de negocios compleja entra en el modelo de escritura. El modelo de lectura puede ser relativamente sencillo.
- Consultas más sencillas. Al almacenar una vista materializada en la base de datos de lectura, la aplicación puede evitar combinaciones complejas cuando realiza consultas.
Consideraciones y problemas de implementación
Estos son algunos de los desafíos de la implementación de este patrón:
Complejidad. La idea básica de CQRS es sencilla. Pero puede generar un diseño de aplicación más complejo, especialmente si incluye el patrón Event Sourcing.
Mensajería. Aunque CQRS no requiere mensajería, es normal usarla para procesar comandos y publicar eventos de actualización. En ese caso, la aplicación debe gestionar errores de mensaje o mensajes duplicados. Consulte las instrucciones sobre la prioridad de las colas para trabajar con comandos que tienen diferentes prioridades.
Coherencia final. Si separa las bases de datos de lectura y escritura, los datos de lectura pueden estar obsoletos. El almacén de modelos de lectura debe actualizarse para reflejar los cambios del almacén de modelos de escritura, y puede ser difícil detectar cuándo un usuario ha emitido una solicitud basada en datos de lectura obsoletos.
Cuándo usar el patrón CQRS
Considere CQRS en estos escenarios:
Dominios colaborativos en los que muchos usuarios acceden a los mismos datos en paralelo. CQRS permite definir comandos con la suficiente granularidad para minimizar los conflictos de combinación en el nivel de dominio (cualquier conflicto que surja se podrá combinar mediante el comando).
Interfaces de usuario basadas en tareas en las que se guía al usuario a través de un complejo proceso como una serie de pasos o con modelos de dominio complejos. El modelo de escritura tiene una pila de procesamiento de comandos completa con lógica de negocios, validación de entrada y validación empresarial. El modelo de escritura puede tratar un conjunto de objetos asociados como una única unidad para los cambios de datos (un agregado, en la terminología de DDD) y asegurarse de que estos objetos siempre estén en un estado coherente. El modelo de lectura no tiene ninguna lógica de negocios ni pila de validación y solo devuelve un DTO para su uso en un modelo de vista. El modelo de lectura tiene coherencia final con el modelo de escritura.
Escenarios en los que el rendimiento de las lecturas de datos se debe ajustar por separado del rendimiento de las escrituras de datos, especialmente cuando el número de lecturas es mucho mayor que el número de escrituras. En este escenario, puede escalar horizontalmente el modelo de lectura, pero ejecutar el modelo de escritura solo en algunas instancias. Un número reducido de instancias de modelo de escritura también ayuda a minimizar la aparición de conflictos de combinación.
Escenarios en los que un equipo de desarrolladores pueda centrarse en el modelo de dominio complejo que forma parte del modelo de escritura, y otro equipo pueda centrarse en el modelo de lectura y en las interfaces de usuario.
Escenarios en los que se espera que el sistema evolucione con el tiempo y que podrían contener varias versiones del modelo, o en los que las reglas de negocio cambian con regularidad.
Integración con otros sistemas, especialmente en combinación con Event Sourcing, en los que el error temporal de un subsistema no debería afectar a la disponibilidad de los demás.
No se recomienda este patrón si:
El dominio o las reglas de negocio son simples.
Es suficiente con una interfaz de usuario simple, de estilo CRUD, y las operaciones relacionadas de acceso a datos.
Considere la posibilidad de aplicar CQRS a secciones limitadas del sistema donde será más valioso.
Diseño de cargas de trabajo
El arquitecto debe evaluar cómo se puede usar el patrón CQRS en el diseño de su carga de trabajo para abordar los objetivos y principios tratados en los pilares del Marco de la Well-Architected de Azure. Por ejemplo:
| Fundamento | Cómo apoya este patrón los objetivos de los pilares |
|---|---|
| La eficiencia del rendimiento ayuda a que la carga de trabajo satisfaga eficazmente las demandas mediante optimizaciones en el escalado, los datos y el código. | La separación de las operaciones de lectura y escritura en las cargas de trabajo de lectura-escritura intensiva permite optimizar el rendimiento y escalado específicos para el propósito concreto de cada operación. - PE:05 Escapado y particiones - PE:08 Rendimiento de datos |
Al igual que con cualquier decisión de diseño, hay que tener en cuenta las ventajas y desventajas con respecto a los objetivos de los otros pilares que podrían introducirse con este patrón.
Aprovisionamiento de eventos y patrón CQRS
El patrón CQRS se utiliza a menudo junto con el patrón Event Sourcing. Los sistemas basados en CQRS usan modelos de lectura y escritura de datos independientes, cada uno de ellos adaptado a las tareas correspondientes y, a menudo, ubicados en almacenes físicos independientes. Cuando se usa con el patrón Event Sourcing, el almacén de eventos es el modelo de escritura y es el origen oficial de información. El modelo de lectura de un sistema basado en CQRS proporciona vistas materializadas de los datos, normalmente como vistas altamente desnormalizadas. Estas vistas se adaptan a las interfaces y muestran los requisitos de la aplicación, lo cual ayuda a maximizar la apariencia y el rendimiento de las consultas.
Mediante el uso del flujo de eventos como almacén de escritura, en lugar de los datos reales en un momento dado, evita conflictos de actualización en un único agregado y maximiza el rendimiento y la escalabilidad. Los eventos se pueden utilizar para generar vistas materializadas de forma asincrónica de los datos que se usan para rellenar el almacén de lectura.
Dado que el almacén de eventos es el origen oficial de información, es posible eliminar las vistas materializadas y reproducir todos los eventos pasados para crear una nueva representación del estado actual cuando evolucione el sistema, o cuando deba cambiar el modelo de lectura. Las vistas materializadas constituyen, en efecto, una memoria caché duradera de solo lectura de los datos.
Cuando utilice CQRS en combinación con el patrón Event Sourcing, tenga en cuenta lo siguiente:
Al igual que con cualquier sistema en el que los almacenes de escritura y lectura son independientes, los sistemas basados en este patrón solo tienen coherencia final. Habrá un cierto retraso entre la generación del evento y la actualización del almacén de datos.
El patrón agrega complejidad porque se debe crear código para iniciar y controlar los eventos, y ensamblar o actualizar las vistas adecuadas o los objetos que necesitan las consultas o un modelo de lectura. La complejidad del patrón CQRS cuando se usa con el patrón Event Sourcing puede dificultar una implementación correcta y requiere un enfoque diferente para el diseño de sistemas. No obstante, Event Sourcing puede facilitar el modelado del dominio, y puede facilitar la recompilación de vistas o la creación de otras nuevas ya que se preserva la intención de los cambios de los datos.
La generación de vistas materializadas para su uso en el modelo de lectura o las proyecciones de los datos mediante la reproducción y control de eventos para entidades específicas o colecciones de estas, puede conllevar un tiempo de procesamiento y un uso de los recursos significativo. Esto es especialmente cierto si requiere la suma o el análisis de los valores durante períodos largos, ya que puede que se tengan que examinar todos los eventos asociados. Puede resolver este problema mediante la implementación de instantáneas de los datos a intervalos programados, por ejemplo, un recuento total del número de veces que se ha producido una acción específica o el estado actual de una entidad.
Ejemplo de patrón CQRS
El código siguiente muestra algunos extractos de un ejemplo de una implementación CQRS que usa definiciones diferentes para los modelos de lectura y de escritura. Las interfaces de los modelos no dictan ninguna característica de los almacenes de datos subyacentes, y pueden evolucionar y adaptarse de forma independiente ya que estas interfaces están separadas.
El código siguiente muestra la definición del modelo de lectura.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
El sistema permite a los usuarios valorar los productos. El código de la aplicación hace esto mediante el comando RateProduct que aparece en el código siguiente.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
El sistema usa la clase ProductsCommandHandler para controlar los comandos enviados por la aplicación. Normalmente, los clientes envían comandos al dominio a través de un sistema de mensajería como, por ejemplo, una cola. El controlador de comandos acepta estos comandos e invoca los métodos de la interfaz de dominio. La granularidad de cada comando está diseñada para reducir la posibilidad de que haya solicitudes en conflicto. El código siguiente muestra un esquema de la clase ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Pasos siguientes
Los patrones y las directrices siguientes son útiles a la hora de implementar este patrón:
Data Consistency Primer (Manual básico de coherencia de datos). Explica los problemas que normalmente se producen debido a la coherencia final entre los almacenes de datos de lectura y de escritura cuando se usa el patrón CQRS y cómo se pueden resolver estos problemas.
Creación de particiones de datos horizontales, verticales y funcionales Describe los procedimientos recomendados para dividir los datos en particiones que se pueden administrar y a las que se tiene acceso por separado para mejorar la escalabilidad, reducir la contención y optimizar el rendimiento.
La guía de patrones y prácticas CQRS Journey (Introducción a CQRS). En concreto, Introducing the Command Query Responsibility Segregation Pattern (Introducción al patrón de segregación de responsabilidades de la consulta de comandos) explora el patrón y cuándo es útil, y Epilogue: Lessons Learned (Epílogo: lecciones aprendidas) le ayudarán a conocer algunos de los problemas que surgen al utilizar este patrón.
Entradas de blog de Martin Fowler:
Recursos relacionados
Patrón Event Sourcing. Describe con más detalle como se puede usar Event Sourcing con el patrón CQRS para simplificar las tareas de dominios complejos al tiempo que se mejora el rendimiento, la escalabilidad y la capacidad de respuesta. También muestra cómo proporcionar coherencia a los datos transaccionales al tiempo que se mantienen registros de auditorías e historiales completos que pueden permitir acciones de compensación.
Patrón Materialized View. El modelo de lectura de una implementación de CQRS puede contener vistas materializadas de los datos del modelo de escritura o el modelo de lectura se puede utilizar para generar vistas materializadas.
Presentación sobre mejor CQRS mediante patrones de interacción de usuario asincrónicos