Tutorial: Realización de búsquedas de similitud de vectores en las incrustaciones de Azure OpenAI mediante Azure Cache for Redis
En este tutorial, recorrerá un caso de uso básico de búsqueda de similitud de vectores. Usará incrustaciones generadas por Azure OpenAI Service y las funcionalidades de vector de búsqueda integradas del nivel Enterprise de Azure Cache for Redis para consultar un conjunto de datos de películas para buscar la coincidencia más relevante.
El tutorial usa el conjunto de datos de Wikipedia Movie Plots que incluye descripciones de los argumentos de más de 35 000 películas de Wikipedia que abarcan los años 1901 a 2017. El conjunto de datos incluye un resumen del argumento de cada película, además de metadatos como el año de estreno, el director o directores, el reparto principal y el género. Seguirá los pasos del tutorial para generar incrustaciones basadas en el resumen del argumento y usar los demás metadatos para ejecutar consultas híbridas.
En este tutorial, aprenderá a:
- Creación de una instancia de Azure Cache for Redis configurada para el vector de búsqueda
- Instale Azure OpenAI y otras bibliotecas de Python necesarias.
- Descargue el conjunto de datos de BillSum y prepárelo para su análisis.
- Use el modelo text-embeding-ada-002 (versión 2) para generar incrustaciones.
- Creación de un índice vectorial en Azure Cache for Redis
- Use la similitud coseno para clasificar los resultados de búsqueda.
- Use la funcionalidad de consulta híbrida a través de RediSearch para filtrar previamente los datos y hacer que el vector de búsqueda sea aún más eficaz.
Importante
Este tutorial le guiará a través de la creación de un Jupyter Notebook. Puede seguir este tutorial con un archivo de código de Python (.py) y obtener resultados similares, pero tendrá que agregar todos los bloques de código de este tutorial al archivo .py y ejecutar una vez para ver los resultados. En otras palabras, Jupyter Notebooks proporciona resultados intermedios a medida que se ejecutan celdas, pero este no es el comportamiento que debería esperar al trabajar en un archivo de código de Python.
Importante
Si en lugar de ello quiere seguir el tutorial en un cuaderno de Jupyter completo, descargue el archivo del cuaderno de Jupyter llamado tutorial.ipynb y guárdelo en la nueva carpeta redis-vector.
Requisitos previos
- Una suscripción a Azure: cree una cuenta gratuita.
- Acceso concedido a Azure OpenAI en la suscripción de Azure que quiera. Actualmente, debe hacer una solicitud para obtener acceso a Azure OpenAI. Para solicitar acceso a Azure OpenAI, rellene el formulario de https://aka.ms/oai/access.
- Python 3.7.1 o una versión posterior
- Jupyter Notebooks (opcional)
- Un recurso de Azure OpenAI con el modelo text-embedding-ada-002 (versión 2) implementado. Este modelo solo está disponible actualmente en determinadas regiones. Consulte la guía de implementación de recursos para obtener instrucciones sobre cómo implementar el modelo.
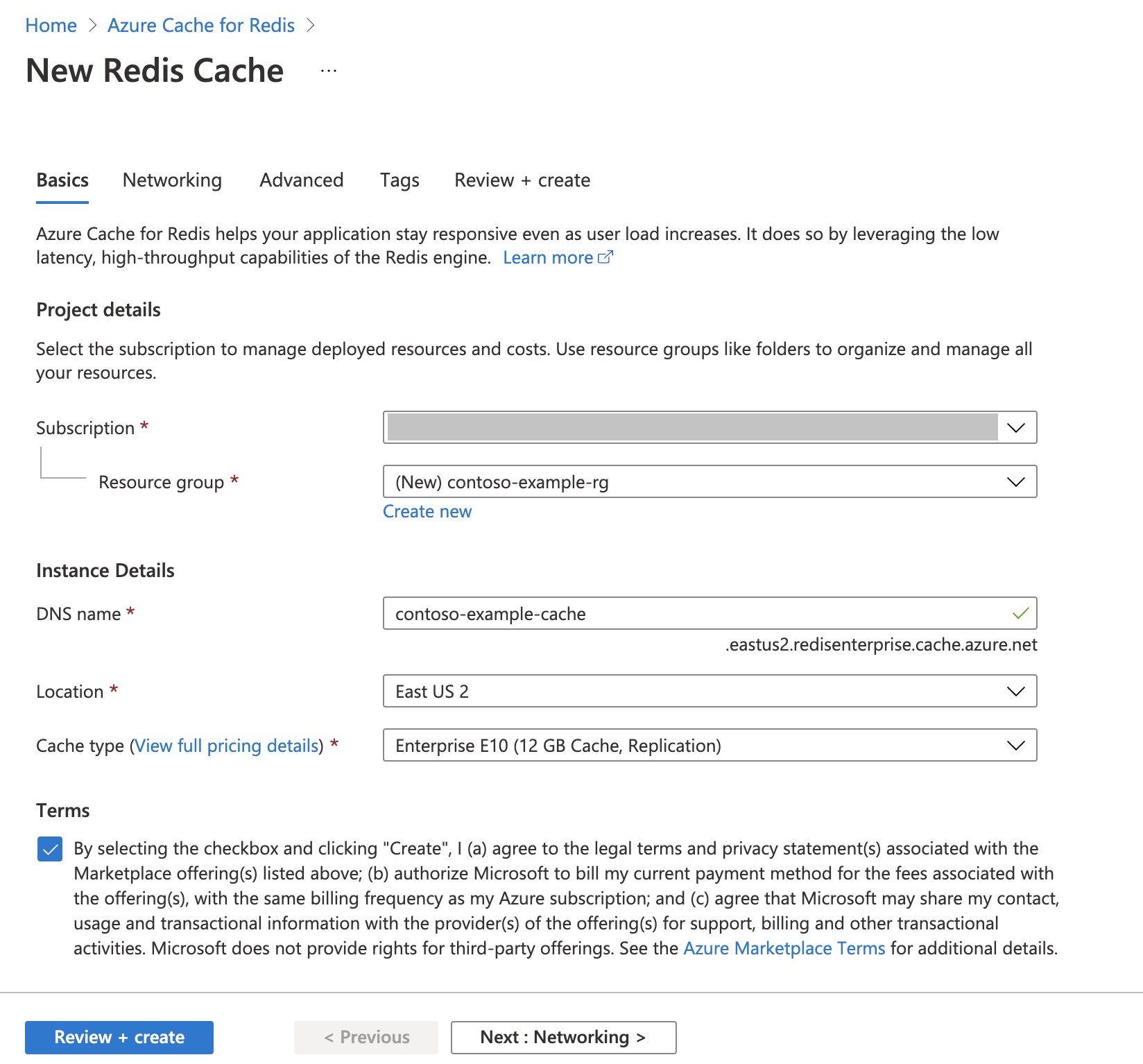
Creación de una instancia de Azure Cache for Redis
Siga la guía de Inicio rápido: Creación de una caché de Redis Enterprise. En la página Opciones avanzadas, asegúrese de que ha agregado el módulo RediSearch y ha elegido la directiva de clúster Enterprise. Todas las demás opciones de configuración pueden coincidir con el valor predeterminado descrito en el inicio rápido.
La caché tarda unos minutos en crearse. Mientras tanto, puede avanzar al siguiente paso.
Configurado su entorno de desarrollo
Cree una carpeta en el equipo local denominado redis-vector en la ubicación donde normalmente guarde los proyectos.
Cree un archivo de Python (tutorial.py) o un cuaderno de Jupyter Notebook (tutorial.ipynb) en la carpeta.
Instale los paquetes de Python necesarios:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Descarga del conjunto de datos
En un explorador web, vaya a https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots.
Inicie sesión o regístrese con Kaggle. El registro es necesario para descargar el archivo.
Seleccione el vínculo Descargar en Kaggle para descargar el archivo archive.zip.
Extraiga el archivo archive.zip y mueva wiki_movie_plots_deduped.csv a la carpeta redis-vector.
Importar bibliotecas y configurar la información de conexión
Para realizar correctamente una llamada en Azure OpenAI, necesita un punto de conexión y una clave. También necesita un punto de conexión y una clave para conectarse a Azure Cache for Redis.
Vaya al recurso de Azure OpenAI en Azure Portal.
Busque Punto de conexión y claves en la sección Administración de recursos. Copie el punto de conexión y la clave de acceso, ya que los necesitará para autenticar las llamadas API. Punto de conexión de ejemplo:
https://docs-test-001.openai.azure.com. Puede usarKEY1oKEY2.Vaya a la página de Información general de su recurso de Azure Cache for Redis en Azure Portal. Copie el punto de conexión.
Busque Claves de acceso en la sección Configuración. Copie la clave de acceso. Puede usar
PrimaryoSecondary.Agregue el código siguiente en una nueva celda de código:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"Actualice el valor de
API_KEYyRESOURCE_ENDPOINTcon los valores de clave y punto de conexión de la implementación de Azure OpenAI.DEPLOYMENT_NAMEdebería establecerse con el nombre de su implementación usando el modelo de incrustaciones detext-embedding-ada-002 (Version 2), yMODEL_NAMEdebería ser el modelo de incrustaciones específico usado.Actualice
REDIS_ENDPOINTyREDIS_PASSWORDcon el punto de conexión y el valor de clave de la instancia de Azure Cache for Redis.Importante
Se recomienda encarecidamente usar variables de entorno o un administrador de secretos, como Azure Key Vault, para pasar la información de clave de API, punto de conexión Y nombre de implementación. Estas variables se establecen en texto no cifrado aquí por motivos de simplicidad.
Ejecute la celda de código 2.
Importación de conjuntos de datos en Pandas y procesamiento de datos
A continuación, leerá el archivo csv en un DataFrame de Pandas.
Agregue el código siguiente en una nueva celda de código:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfEjecute la celda de código 3. Debería ver la salida siguiente:

A continuación, procese los datos añadiendo un índice
id, elimine los espacios de los títulos de las columnas y filtre las películas para tomar solo las realizadas después de 1970 y de países de habla inglesa. Este paso de filtrado reduce el número de películas del conjunto de datos, lo que reduce el costo y el tiempo necesarios para generar incrustaciones. Puede cambiar o quitar los parámetros de filtro en función de sus preferencias.Para filtrar los datos, agregue el código siguiente a una nueva celda de código:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfEjecute la celda de código 4. Debería ver los siguientes resultados:

Cree una función para limpiar los datos quitando los espacios en blanco y los signos de puntuación y, a continuación, úselo en el dataframe que contiene el argumento.
Agregue el código siguiente a una nueva celda de código y ejecútelo:
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Por último, quite las entradas que contengan descripciones de argumento que sean demasiado largas para el modelo de incrustaciones. (en otras palabras, requieren más tokens que el límite de tokens de 8 192). A continuación, calcule los números de tokens necesarios para generar incrustaciones. Esto también afecta a los precios de la generación de incrustaciones.
Agregue el código siguiente en una nueva celda de código:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))Ejecute la celda de código 6. Debería ver este resultado:
Number of movies: 11125 Number of tokens required:7044844Importante
Consulte precios de Azure OpenAI Service para calcular el costo de generar incrustaciones en función del número de tokens necesarios.


Carga de DataFrame en LangChain
Cargue el DataFrame en LangChain mediante la clase DataFrameLoader. Una vez que los datos están en los documentos de LangChain, es mucho más fácil usar las bibliotecas de LangChain para generar incrustaciones y realizar búsquedas de similitud. Establezca Argumento como page_content_column para que las incrustaciones se generen en esta columna.
Agregue el código siguiente a una nueva celda de código y ejecútelo:
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Generación de incrustaciones y carga en Redis
Ahora que los datos se han filtrado y cargado en LangChain, creará incrustaciones para que pueda consultar en el argumento de cada película. El código siguiente configura Azure OpenAI, genera incrustaciones y carga los vectores de incrustaciones en Azure Cache for Redis.
Agregue el código siguiente en una nueva celda de código:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Ejecute la celda de código 8. Esto puede tardar hasta 30 minutos en completarse. También se genera un archivo
redis_schema.yaml. Este archivo es útil si desea conectarse al índice en la instancia de Azure Cache for Redis sin volver a generar incrustaciones.
Importante
La velocidad a la que se generan incrustaciones depende de la cuota disponible para el modelo de Azure OpenAI. Con una cuota de 240 000 tokens por minuto, tardará unos 30 minutos en procesar los tokens de 7M del conjunto de datos.
Ejecución de consultas de vector de búsqueda
Ahora que el conjunto de datos, la API del servicio Azure OpenAI y la instancia de Redis están configuradas, puede buscar mediante vectores. En este ejemplo, se devuelven los 10 resultados principales de una consulta determinada.
Agregue el siguiente código a su archivo de código Python:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Ejecute la celda de código 9. Debería ver la siguiente salida:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)La puntuación de similitud se devuelve junto con la clasificación ordinal de películas por similitud. Observe que las puntuaciones de similitud de las consultas más específicas disminuyen más rápidamente en la lista.
Búsquedas híbridas
Dado que RediSearch también cuenta con una funcionalidad de búsqueda enriquecida sobre el vector de búsqueda, es posible filtrar los resultados por los metadatos del conjunto de datos, como el género de cine, el reparto, el año de lanzamiento o el director. En este caso, filtre según el género
comedy.Agregue el código siguiente en una nueva celda de código:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Ejecute la celda de código 10. Debería ver la siguiente salida:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Con Azure Cache for Redis y Azure OpenAI Service, puede usar incrustaciones y vector de búsqueda para agregar eficaces funcionalidades de búsqueda a la aplicación.
Limpieza de recursos
Si desea seguir usando los recursos que creó en este artículo, mantenga el grupo de recursos.
De lo contrario, para evitar cargos relacionados con los recursos, si ha terminado de usarlos, puede eliminar el grupo de recursos de Azure que creó.
Advertencia
La eliminación de un grupo de recursos es irreversible. Cuando elimine un grupo de recursos, todos los recursos del grupo se eliminan permanentemente. Asegúrese de no eliminar por accidente el grupo de recursos o los recursos equivocados. Si ha creado los recursos en un grupo de recursos existente que tiene recursos que desea conservar, puede eliminar cada recurso individualmente en lugar de eliminar el grupo de recursos.
Eliminación de un grupo de recursos
Inicie sesión en Azure Portal y después seleccione Grupos de recursos.
Seleccione el grupo de recursos que se eliminará.
Si hay muchos grupos de recursos, en Filtro para cualquier campo, escriba el nombre del grupo de recursos que creó para completar este artículo. En la lista de resultados de búsqueda, seleccione el grupo de recursos.

Seleccione Eliminar grupo de recursos.
En el panel Eliminar un grupo de recursos, escriba el nombre del grupo de recursos para confirmar y, a continuación, seleccione Eliminar.
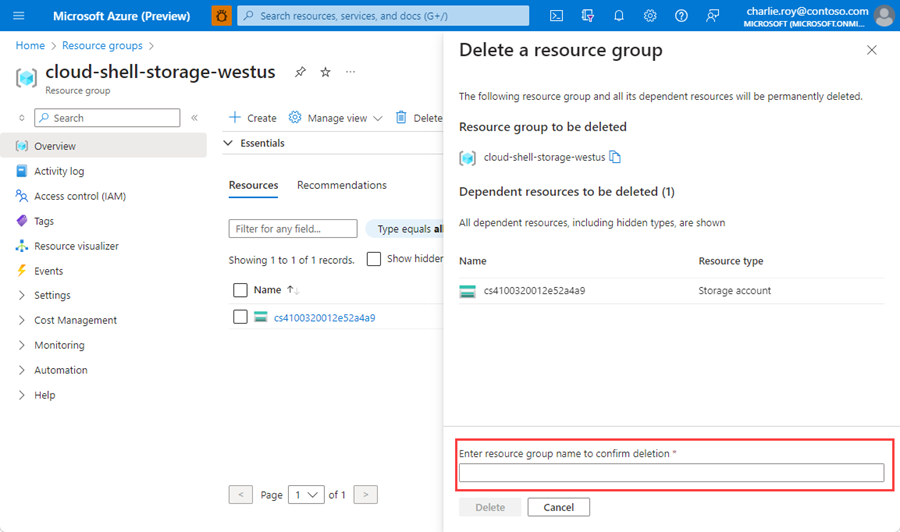
En unos instantes, el grupo de recursos y todos sus recursos se eliminan.
Contenido relacionado
- Más información sobre Azure Cache for Redis
- Más información sobre las funcionalidades de vector de búsqueda de Azure Cache for Redis
- Más información sobre las incrustaciones generadas por Azure OpenAI Service
- Más información sobre la similitud de coseno
- Lea cómo crear una aplicación con tecnología de inteligencia artificial con OpenAI y Redis
- Compilar una aplicación de preguntas y respuestas con respuestas semánticas