Administración de recursos en Azure SQL Database
Se aplica a: ![]() Azure SQL Database
Azure SQL Database
En este artículo se proporciona información general sobre la administración de recursos en Azure SQL Database. Se proporciona información sobre lo que ocurre cuando se alcanzan los límites de recursos y se describen los mecanismos de gobernanza de recursos que se usan para aplicar dichos límites.
Para conocer los límites de recursos específicos por plan de tarifa para bases de datos únicas, consulte
- Límites de recursos basados en DTU para bases de datos únicas
- Límites de recursos basados en núcleos virtuales para bases de datos únicas
Para conocer los límites de recursos del grupo elástico, consulte:
- Límites de recursos basados en DTU para grupos elásticos
- Límites de recursos basados en núcleos virtuales para grupos elásticos
Para conocer los límites del grupo de SQL dedicado en Azure Synapse Analytics, consulte:
Límites de núcleos virtuales de la suscripción por región
A partir de marzo de 2024, las suscripciones tienen los siguientes límites de núcleo virtual por región y por suscripción:
| Tipo de suscripción | Límites de núcleo virtual predeterminados |
|---|---|
| Contrato Enterprise (EA) | 2000 |
| Pruebas gratuitas | 10 |
| Microsoft for Startups | 100 |
| MSDN / MPN / Imagine / AzurePass / Azure for Students | 40 |
| Pay-as-you-go (PAYG) | 150 |
Ten en cuenta lo siguiente:
- Estos límites son aplicables a las suscripciones nuevas y existentes.
- Las bases de datos y los grupos elásticos aprovisionados con el modelo de compra de DTU también se cuentan para la cuota de núcleos virtuales y viceversa. Cada núcleo virtual consumido se considera equivalente a 100 DTU consumidas para la cuota de nivel de servidor.
- Los límites predeterminados incluyen los núcleos virtuales configurados para las bases de datos de proceso aprovisionadas o los grupos elásticos, y los núcleos virtuales máximos configurados para bases de datos sin servidor.
- Puede usar la llamada a la API REST de usos de suscripciones: obtener para determinar el uso actual de núcleo virtual de la suscripción.
- Para solicitar una cuota de núcleo virtual mayor que la predeterminada, envíe una nueva solicitud de soporte técnico en Azure Portal. Para más información, consulte Solicitud de aumentos de cuota para Azure SQL Database.
Límites del servidor lógico
| Resource | Límite |
|---|---|
| Bases de datos por servidor lógico | 5000 |
| Número predeterminado de servidores lógicos por suscripción en una región | 250 |
| Número máximo de servidores lógicos por suscripción en una región | 250 |
| Número máximo de grupos elásticos por servidor lógico | Limitado por el número de DTU o núcleos virtuales. Por ejemplo, si cada grupo tiene 1000 DTU, un servidor puede admitir 54 grupos. |
Importante
Cuando el número de bases de datos se aproxima al límite por servidor lógico, puede ocurrir lo siguiente:
- Aumento de la latencia de las consultas en ejecución en la
masterbase de datos. Esto incluye las vistas de las estadísticas del uso de los recursos comosys.resource_stats. - Aumento de la latencia en las operaciones de administración y presentación de las perspectivas del portal que implican enumerar las bases de datos del servidor.
¿Qué ocurre cuando se alcanzan los límites de recursos?
CPU de proceso
Cuando la utilización de CPU de proceso de base de datos es elevada, la latencia de las consultas aumenta y se puede agotar su tiempo de espera. En estas condiciones, el servicio puede poner en cola las consultas y se proporcionan recursos para la ejecución a medida que los recursos están disponibles.
Si observa un uso de proceso elevado, las opciones de mitigación incluyen:
- Aumentar el tamaño de proceso de la base de datos o del grupo elástico para proporcionar a la base de datos más recursos de proceso. Consulte Scale single database resources (Escala de recursos de bases de datos únicas) y Scale elastic pool resources (Escala de recursos de grupos elásticos).
- Optimice las consultas para reducir el uso de recursos de CPU de cada consulta. Para más información, consulte Optimización y sugerencias de consultas.
Storage
Cuando el espacio de datos usado alcanza el límite máximo de tamaño de datos, ya sea en el nivel de base de datos o en el nivel de grupo elástico, se produce un error en las inserciones y actualizaciones que aumentan el tamaño de los datos, y los clientes reciben un mensaje de error. Las instrucciones SELECT y DELETE no se ven afectadas.
En los niveles de servicio Premium y Crítico para la empresa, los clientes también reciben un mensaje de error si el consumo de almacenamiento combinado en función de los datos, el registro de transacciones y tempdb para una sola base de datos o un grupo elástico supera el tamaño máximo de almacenamiento local. Para más información, consulte la sección Gobernanza del espacio de almacenamiento.
Si observa un uso de espacio de almacenamiento elevado, las opciones de mitigación incluyen:
- Aumente el tamaño máximo de los datos de la base de datos o el grupo elástico, o bien escale verticalmente a un objetivo de servicio con un límite de tamaño máximo de datos mayor. Consulte Scale single database resources (Escala de recursos de bases de datos únicas) y Scale elastic pool resources (Escala de recursos de grupos elásticos).
- Si la base de datos está en un grupo elástico, se puede mover fuera del grupo para que su espacio de almacenamiento no se comparta con otras bases de datos.
- Reduzca una base de datos para reclamar el espacio no utilizado. Para obtener más información, consulte Administración del espacio de archivo en Azure SQL Database.
- En los grupos elásticos, la reducción de una base de datos proporciona más almacenamiento para otras bases de datos del grupo.
- Compruebe si el uso elevado de espacio se debe a un pico en el tamaño del almacén de versiones persistentes (PVS). PVS es una parte de cada base de datos y se utiliza para implementar la Recuperación acelerada de la base de datos. Para determinar el tamaño actual del PVS, consulte Solución de problemas de PVS. Un motivo común para un tamaño grande de PVS es una transacción abierta durante mucho tiempo (horas), lo que impide la limpieza de registros de versiones anteriores en PVS.
- En el caso de bases de datos y grupos elásticos en los niveles de servicio Premium y Crítico para la empresa que consumen grandes cantidades de almacenamiento, es posible que reciba un error de que no hay suficiente espacio, aunque el espacio utilizado en la base de datos o el grupo elástico esté por debajo de su límite máximo de tamaño de datos. Esto puede ocurrir si
tempdbo los archivos de registro de transacciones consumen una gran cantidad de almacenamiento hacia el límite máximo de almacenamiento local. Conmute por error la base de datos o el grupo elástico para restablecertempdba su tamaño más pequeño inicial o reduzca el registro de transacciones para reducir el consumo de almacenamiento local.
Sesiones, trabajos y solicitudes
Las sesiones, los trabajos y las solicitudes se definen de la siguiente manera:
- Una sesión representa un proceso conectado al motor de base de datos.
- Una solicitud es la representación lógica de una consulta o lote. Un cliente conectado a una sesión emite una solicitud. Con el tiempo, se pueden emitir varias solicitudes en la misma sesión.
- Un subproceso de trabajo, también conocido como trabajo o subproceso, es una representación lógica de un subproceso de sistema operativo. Una solicitud puede tener muchos trabajos cuando se ejecuta con un plan de ejecución de consultas en paralelo, o bien un único trabajo cuando se ejecuta con un plan de ejecución en serie (de un único subproceso). También es necesario que los trabajos admitan actividades fuera de las solicitudes: por ejemplo, se requiere que un trabajo procese una solicitud de inicio de sesión al conectarse una sesión.
Para obtener más información sobre estos conceptos, vea la Guía de arquitectura de subprocesos y tareas.
El número máximo de trabajos se determina por el nivel de servicio y el tamaño de proceso. Las nuevas solicitudes se rechazan cuando se alcanzan los límites de sesión o de trabajo y los clientes reciben un mensaje de error. Aunque el número de conexiones se puede controlar mediante la aplicación, el número de trabajos simultáneos suele ser más difícil de calcular y controlar. Esto es especialmente cierto durante los períodos de carga máxima, cuando se alcanzan los límites de recursos de base de datos y los trabajos se apilan debido a consultas de larga duración, cadenas de bloqueo de gran tamaño o excesivo paralelismo de las consultas.
Nota:
La oferta inicial de Azure SQL Database solo admitía consultas de un único subproceso. En ese momento, el número de solicitudes siempre equivalía al número de trabajos. El mensaje de error 10928 en Azure SQL Database contiene el texto The request limit for the database is *N* and has been reached solo con fines de compatibilidad con versiones anteriores. El límite alcanzado es, en realidad, el número de trabajos.
Si el valor de grado máximo de paralelismo (MAXDOP) es igual a cero o es mayor que uno, el número de trabajos puede ser mucho mayor que el número de solicitudes y el límite podría alcanzarse mucho antes que cuando MAXDOP es igual a uno.
- Obtenga más información sobre el error 10928 en Errores de gobernanza de recursos.
- Más información sobre el agotamiento del límite de solicitudes en Errores 10928 y 10936.
Puede mitigar el hecho de acercarse a los límites de la sesión o el trabajo, o alcanzarlos, mediante las acciones enumeradas a continuación:
- Aumentar el nivel de servicio o el tamaño de proceso de la base de datos o del grupo elástico. Consulte Scale single database resources (Escala de recursos de bases de datos únicas) y Scale elastic pool resources (Escala de recursos de grupos elásticos).
- Optimizar las consultas para reducir el uso de recursos si la causa del aumento de los trabajos es la contención de los recursos de proceso. Para más información, consulte Optimización y sugerencias de consultas.
- Optimizar la carga de trabajo de consultas para reducir el número de repeticiones y la duración del bloqueo de consultas. Para obtener más información, consulte Descripción y resolución de problemas de bloqueo en Azure SQL.
- Reducir la configuración MAXDOP cuando sea necesario.
Busque los límites de la sesión y el trabajo para Azure SQL Database por nivel de servicio y tamaño de proceso:
- Límites de recursos para bases de datos únicas que utilizan el modelo de compra en núcleos virtuales
- Límites de recursos para grupos elásticos que usan el modelo de compra de núcleo virtual
- Límites de recursos para bases de datos únicas que usan el modelo de compra de DTU
- Límites de recursos para grupos elásticos que utilizan el modelo de compra de DTU
Obtenga más información sobre cómo solucionar errores específicos para los límites del trabajo o la sesión en Errores de gobernanza de recursos.
Conexiones externas
El número de conexiones simultáneas a puntos de conexión externos realizadas a través de sp_invoke_external_rest_endpoint se limita al 10 % de los subprocesos de trabajo, con un límite máximo de 150 trabajos.
Memoria
A diferencia de otros recursos (CPU, nodos de trabajo, almacenamiento), el hecho de alcanzar el límite de memoria no afecta negativamente al rendimiento de las consultas y no provoca errores. Como se describe con detalle en Guía de la arquitectura de administración de memoria, el motor de base de datos usa a menudo toda la memoria disponible, por diseño. La memoria se usa principalmente para el almacenamiento en caché de los datos, para evitar un acceso más lento al almacenamiento. Por lo tanto, un mayor uso de memoria suele mejorar el rendimiento de las consultas debido a lecturas más rápidas de la memoria, en lugar de lecturas más lentas del almacenamiento.
Después del inicio del motor de base de datos, a medida que la carga de trabajo comienza a leer datos del almacenamiento, el motor de base de datos almacena en memoria caché los datos de forma agresiva. Después de este período inicial de crecimiento, es habitual y se espera ver que las columnas avg_memory_usage_percent y avg_instance_memory_percent de sys.dm_db_resource_stats y la métrica sql_instance_memory_percent de Azure Monitor estén cerca del 100 %, especialmente en el caso de las bases de datos que no están inactivas y no caben completas en memoria.
Nota:
La métrica sql_instance_memory_percent refleja el consumo total de memoria por parte del motor de base de datos. Esta métrica podría no alcanzar el 100 % incluso cuando se ejecutan cargas de trabajo de alta intensidad. Esto se debe a que una pequeña parte de la memoria disponible está reservada para asignaciones de memoria críticas distintas de la caché de datos, como pilas de subprocesos y módulos ejecutables.
Además de la memoria caché de datos, la memoria se utiliza en otros componentes del motor de base de datos. Cuando hay demanda de memoria y la caché de datos ha utilizado toda la memoria disponible, el motor de base de datos reduce dinámicamente el tamaño de la caché de datos para poner la memoria a disposición de otros componentes, y la caché de datos crece dinámicamente cuando otros componentes liberan memoria.
En raras ocasiones, una carga de trabajo suficientemente exigente puede producir una condición de memoria insuficiente, lo que provoca errores de memoria insuficiente. Los errores de memoria insuficiente pueden producirse en cualquier nivel de uso de memoria entre el 0 % y el 100 %. Es más probable que se produzcan en tamaños de proceso más pequeños que tienen límites de memoria proporcionalmente menores, o bien con cargas de trabajo que usan más memoria para el procesamiento de consultas, como en los grupos elásticos densos.
Si recibe errores de memoria insuficiente, las opciones de mitigación incluyen:
- Revise los detalles de la condición de OOM en sys.dm_os_out_of_memory_events.
- Aumentar el nivel de servicio o el tamaño de proceso de la base de datos o del grupo elástico. Consulte Scale single database resources (Escala de recursos de bases de datos únicas) y Scale elastic pool resources (Escala de recursos de grupos elásticos).
- Optimizar las consultas y la configuración para reducir el uso de memoria. Las soluciones más comunes se describen en la tabla siguiente.
| Solución | Descripción |
|---|---|
| Reducir el tamaño de las concesiones de memoria | Para más información sobre las concesiones de memoria, consulte la entrada de blog Descripción de la concesión de memoria de SQL Server. Una solución común para evitar concesiones de memoria excesivamente grandes es mantener las estadísticas actualizadas. Esto da como resultado estimaciones más precisas del consumo de memoria por parte del motor de consultas y se evitan concesiones de memoria grandes. En las bases de datos que usan el nivel de compatibilidad 140 y superior, el motor de base de datos puede ajustar automáticamente el tamaño de la concesión de memoria mediante Comentarios de concesión de memoria del modo de proceso por lotes. Igualmente, en las bases de datos que usan el nivel de compatibilidad 150 y superiores, el motor de base de datos también usa los Comentarios de concesión de memoria del modo de fila para las consultas del modo de fila más comunes. Esta funcionalidad integrada ayuda a evitar errores de memoria insuficiente debidos a concesiones de memoria grandes. |
| Reducir el tamaño de la memoria caché del plan de consulta | El motor de base de datos almacena en memoria caché los planes de consulta para evitar la compilación de un plan de consulta para cada ejecución de la consulta. Para evitar la saturación de la caché del plan de consulta que causan los planes de almacenamiento en caché que solo se usan una vez, asegúrese de usar consultas parametrizadas y considere la posibilidad de habilitar la configuración con ámbito de base de datos OPTIMIZE_FOR_AD_HOC_WORKLOADS. |
| Reducir el tamaño de la memoria de bloqueos | El motor de base de datos utiliza memoria para los bloqueos. Cuando sea posible, evite transacciones grandes que puedan adquirir un gran número de bloqueos y provoquen un alto consumo de la memoria de bloqueos. |
Consumo de recursos por cargas de trabajo de usuario y procesos internos
Azure SQL Database necesita recursos de proceso para implementar características de servicio principales, como alta disponibilidad y recuperación ante desastres, copia de seguridad y restauración de bases de datos, supervisión, Almacén de consultas, ajuste automático, etc. El sistema reserva una parte limitada de los recursos generales para estos procesos internos mediante mecanismos de gobernanza de recursos, lo que permite que el resto de los recursos estén disponibles para las cargas de trabajo de usuario. A veces, cuando los procesos internos no usan recursos de proceso, el sistema los pone a disposición de las cargas de trabajo de usuario.
El consumo total de CPU y memoria de las cargas de trabajo de usuario y de los procesos internos se indica en las vistas sys.dm_db_resource_stats y sys.resource_stats, en las columnas avg_instance_cpu_percent y avg_instance_memory_percent. Estos datos también se indican a través de las métricas de Azure Monitor sql_instance_cpu_percent y sql_instance_memory_percent para sql_instance_cpu_percent y sql_instance_memory_percent en el nivel de grupo.
Nota
Las métricas de Azure Monitor sql_instance_cpu_percent y sql_instance_memory_percent están disponibles desde julio de 2023. Son totalmente equivalentes a las métricas sqlserver_process_core_percent y sqlserver_process_memory_percent disponibles anteriormente, respectivamente. Las dos últimas métricas siguen estando disponibles, pero se quitarán en el futuro. Para evitar una interrupción en la supervisión de la base de datos, no use las métricas anteriores.
Estas métricas no están disponibles para las bases de datos que usan los niveles de servicio Básico, S1 y S2. Los mismos datos están disponibles en las vistas de administración dinámica a continuación.
El consumo de CPU y memoria de las cargas de trabajo de usuario en cada base de datos se indica en las vistas sys.dm_db_resource_stats y sys.resource_stats, en las columnas avg_cpu_percent y avg_memory_usage_percent. En el caso de los grupos elásticos, el consumo de recursos a nivel de grupo se notifica en la vista de sys.elastic_pool_resource_stats (para escenarios de informes históricos) y en sys.dm_elastic_pool_resource_stats para la supervisión en tiempo real. El consumo de CPU de la carga de trabajo de usuario también se indica a través de la métrica de Azure Monitor cpu_percent, para cpu_percent y grupos elásticos en el nivel de grupo.
En las vistas sys.dm_resource_governor_resource_pools_history_ex y sys.dm_resource_governor_workload_groups_history_ex, se muestra un desglose más detallado del consumo reciente de recursos por parte de cargas de trabajo de usuario y procesos internos. Para obtener más información sobre los grupos de recursos y los grupos de cargas de trabajo a los que se hace referencia en estas vistas, consulte Regulación de recursos. Estas vistas informan sobre el uso de recursos por parte de cargas de trabajo de usuario y procesos internos específicos en los grupos de recursos y grupos de cargas de trabajo asociados.
Sugerencia
Al supervisar o solucionar de problemas de rendimiento de carga de trabajo, es importante tener en cuenta el consumo de CPU del usuario (avg_cpu_percent, cpu_percent) y el consumo de CPU total de las cargas de trabajo de usuario y los procesos internos (avg_instance_cpu_percent,sql_instance_cpu_percent). Es posible que el rendimiento se vea afectado notablemente si cualquiera de estas métricas está en el intervalo del 70 al 100 %.
El consumo de CPU del usuario se define como un porcentaje del límite de CPU de carga de trabajo del usuario en cada objetivo de servicio. Del mismo modo, el consumo total de CPU se define como el porcentaje del límite de CPU para todas las cargas de trabajo. Como los dos límites son diferentes, el usuario y el consumo total de CPU se miden en escalas diferentes y no son directamente comparables entre sí.
Si el consumo de CPU del usuario alcanza el 100 %, significa que la carga de trabajo del usuario usa completamente la capacidad de CPU disponible en el objetivo de servicio seleccionado, aunque el consumo total de CPU permanezca por debajo del 100 %.
Cuando el consumo de CPU total alcanza el intervalo del 70-100 %, es posible ver una reducción del rendimiento de la carga de trabajo de usuario y un aumento de la latencia de las consultas, aunque se indique un consumo de CPU del usuario bastante por debajo del 100 %. Esto es más probable que suceda si se usan objetivos de servicio menores con una asignación moderada de recursos de proceso, pero cargas de trabajo de usuario relativamente intensas, como en grupos elásticos densos. Esto también puede suceder con objetivos de servicio menores si los procesos internos requieren temporalmente recursos adicionales, como, por ejemplo, al crear una nueva réplica de la base de datos o al realizar la copia de seguridad de la base de datos.
Del mismo modo, cuando el consumo de CPU del usuario alcanza el intervalo del 70-100 %, el rendimiento de la carga de trabajo del usuario se aplanará y aumentará la latencia de las consultas, aunque el consumo total de CPU pueda estar muy por debajo de su límite.
Si el consumo de CPU del usuario o el consumo de CPU total es alto, las opciones de mitigación son las mismas que las indicadas en la sección CPU de proceso, e incluyen el aumento del objetivo de servicio o la optimización de la carga de trabajo de usuario.
Nota:
Incluso en una base de datos o un grupo elástico completamente inactivos, el consumo total de CPU nunca está en cero debido a las actividades del motor de base de datos en segundo plano. Puede fluctuar en un amplio rango en función de las actividades en segundo plano específicas, el tamaño de proceso y la carga de trabajo de usuario anterior.
Gobernanza de recursos
Para aplicar límites de recursos, Azure SQL Database usa una implementación de regulación de recursos basada en Resource Governor de SQL Server, modificada y extendida para ejecutarse en la nube. En SQL Database, hay varios grupos de recursos y grupos de cargas de trabajo con límites de recursos que se establecen en el nivel de grupo para proporcionar una base de datos como servicio equilibrada. La carga de trabajo de usuario y las cargas de trabajo internas se clasifican en grupos de recursos y grupos de cargas de trabajo distintos. La carga de trabajo de usuario de las réplicas primarias y secundaria de lectura, incluidas las réplicas geográficas, se clasifica en el grupo de recursos SloSharedPool1 y en el grupo de cargas de trabajo UserPrimaryGroup.DBId[N], donde [N] representa el valor del identificador de base de datos. Además, hay varios grupos de recursos y grupos de cargas de trabajo para varias cargas de trabajo internas.
Además de usar Resource Governor para regular los recursos dentro del motor de base de datos, Azure SQL Database también emplea objetos de trabajo de Windows para la regulación de los recursos de nivel de proceso, y el Administrador de recursos del servidor de archivos (FSRM) de Windows para la administración de la cuota de almacenamiento.
La regulación de recursos de Azure SQL Database es jerárquica por naturaleza. De arriba a abajo, los límites se aplican en el nivel de sistema operativo y en el nivel de volumen de almacenamiento mediante mecanismos de regulación de recursos del sistema operativo y Resource Governor; en el nivel de grupo de recursos mediante Resource Governor; y en el nivel de grupo de cargas de trabajo mediante Resource Governor. Los límites de regulación de recursos en vigor para la base de datos o el grupo elástico actuales se notifican en la vista sys.dm_user_db_resource_governance.
Gobernanza de E/S de datos
La gobernanza de E/S de los datos es un proceso de Azure SQL Database que se usa para limitar la E/S física de lectura y escritura en los archivos de datos de una base de datos. Para cada nivel de servicio se establecen límites de IOPS con el fin de minimizar el efecto "vecino ruidoso", para proporcionar igualdad en la asignación de recursos en un servicio multiinquilino y para permanecer dentro de las capacidades del hardware y el almacenamiento subyacentes.
Para bases de datos únicas, se aplican los límites del grupo de cargas de trabajo a toda la E/S de almacenamiento de la base de datos. En el caso de los grupos elásticos, los límites de grupo de cargas de trabajo se aplican a cada base de datos del grupo. Además, el límite del grupo de recursos se aplica además a la E/S acumulativa del grupo elástico. En tempdb, la E/S está sujeta a límites de grupo de cargas de trabajo, con la excepción del nivel de servicio Básico, Estándar y De uso general, donde se aplican límites de E/S tempdb más altos. En general, es posible que la carga de trabajo no pueda lograr los límites del grupo de recursos em una base de datos (sola o agrupada), porque los límites del grupo de cargas de trabajo son inferiores a los límites del grupo de recursos y limitan antes el número de IOPS y el rendimiento. Pero la carga de trabajo combinada puede alcanzar los límites del grupo en varias bases de datos del mismo grupo.
Por ejemplo, si una consulta genera 1000 IOPS sin gobernanza de recursos de E/S, pero el límite máximo de IOPS del grupo de cargas de trabajo se establece en 900 IOPS, la consulta no puede generar más de 900 IOPS. Pero si el límite máximo de IOPS del grupo de recursos se establece en 1500 IOPS y la E/S total de todos los grupos de cargas de trabajo asociados con el grupo de recursos supera los 1500 IOPS, la E/S de la misma consulta podría reducirse por debajo del límite del grupo de trabajo de 900 IOPS.
El número de IOPS y los valores máximos de rendimiento que devuelve la vista sys.dm_user_db_resource_governance actúan como límites, no como garantías. Además, la gobernanza de recursos no garantiza ninguna latencia de almacenamiento específica. Los mejores logros en cuanto a latencia, IOPS y rendimiento para una carga de trabajo de usuario determinada no dependen solo de los límites de gobernanza de los recursos de E/S, sino también de la mezcla de tamaños de E/S usados y de las capacidades del almacenamiento subyacente. SQL Database usa operaciones de E/S con un tamaño que varía de 512 bytes a 4 MB. Con el fin de aplicar los límites de IOPS, se cuenta cada E/S, con independencia de su tamaño, a excepción de las bases de datos con archivos de datos de Azure Storage. En ese caso, las E/S de más de 256 KB se cuentan como varias E/S de 256 KB, para alinearse con el recuento de E/S de Azure Storage.
En las bases de datos Básico, Estándar y De uso general, que usan archivos de datos de Azure Storage, es posible que el valor primary_group_max_io no sea factible si una base de datos no tiene suficientes archivos de datos para proporcionar de forma acumulativa este número de IOPS, o si los datos no se distribuyen uniformemente entre los archivos o si el nivel de rendimiento de los blobs subyacentes limita el número de IOPS o el rendimiento por debajo del límite de gobernanza de los recursos. Igualmente, con las operaciones de E/S de registros pequeños generadas por la confirmación frecuente de transacciones, es posible que el valor primary_max_log_rate no sea factible para una carga de trabajo debido al límite de IOPS en el blob de Azure Storage subyacente. En el caso de las bases de datos que usan Azure Premium Storage, Azure SQL Database usa blobs de almacenamiento lo suficientemente grandes como para obtener el número de IOPS o el rendimiento necesarios, con independencia del tamaño de la base de datos. En el caso de bases de datos más grandes, se crean varios archivos de datos para aumentar la capacidad total de IOPS y rendimiento.
Los valores de uso de recursos, como avg_data_io_percent y avg_log_write_percent, notificados en las vistas sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_statsy sys.elastic_pool_resource_stats, se calculan como porcentajes de los límites máximos de gobernanza de recursos. Por lo tanto, cuando otros factores que no son la gobernanza de recursos limitan el número de IOPS o el rendimiento, es posible que se reduzcan estos y que aumenten las latencias a medida que se incrementa la carga de trabajo, incluso aunque la utilización de los recursos notificada permanezca por debajo del 100 %.
Para supervisar el número de IOPS, el rendimiento y la latencia de lectura y escritura por cada archivo de base de datos, utilice la función sys.dm_io_virtual_file_stats(). Esta función muestra toda la E/S en la base de datos, incluida la que se produce en segundo plano que no se tiene en cuenta en avg_data_io_percent, pero usa el número de IOPS y el rendimiento del almacenamiento subyacente, y puede afectar a la latencia de almacenamiento observada. La función notifica una latencia adicional, en las columnas io_stall_queued_read_ms y io_stall_queued_write_ms, respectivamente, que podría deberse a la gobernanza de los recursos de E/S de lecturas y escrituras.
Regulación de la tasa de registro de transacciones
La gobernanza de las tasas de registros de transacciones es un proceso en Azure SQL Database que se usa para limitar las altas tasas de ingesta de cargas de trabajo como la inserción masiva, SELECT INTO y compilaciones de índice. Se realiza el seguimiento de estos límites y se aplican en el nivel de fracciones de segundo a la tasa de generación de registros, lo que limita el rendimiento sin importar cuántas E/S se pueden emitir para los archivos de datos. Actualmente, las tasas de generación del registro de transacciones se escalan linealmente hasta un punto que depende del hardware y del nivel de servicio.
Las tasas de registro se establecen de manera que se puedan alcanzar y sostener en diversos escenarios, mientras que el sistema global puede mantener su funcionalidad con un impacto mínimo en la carga del usuario. La gobernanza de las tasas de registro garantiza que las copias de seguridad del registro de transacciones se mantendrán dentro de los contratos de nivel de servicio de la capacidad de recuperación publicados. Esta gobernanza también evita un trabajo pendiente excesivo en las réplicas secundarias, lo que podría provocar un tiempo de inactividad mayor que el previsto durante las conmutaciones por error.
No se controlan ni limitan las E/S físicas reales para los archivos de registro de transacciones. A medida que se generan los registros, se evalúa cada operación para ver si se debe retrasar a fin de mantener una tasa máxima de registro deseada (MB/s por segundo). No se agregan retrasos cuando los registros se vacían en el almacenamiento. En lugar de eso, la gobernanza de tasas de registro se aplica durante la propia generación de registros.
Las tasas reales de generación de registros impuestas en tiempo de ejecución también podrían verse afectadas por los mecanismos de comentarios, lo que reduce de manera temporal las tasas de registros permitidas para que el sistema se pueda estabilizar. La administración del espacio de los archivos de registro, para evitar la falta de espacio para registros, y los mecanismos de replicación de datos pueden disminuir temporalmente los límites generales del sistema.
El modelado de tráfico del regulador de las tasas de registros se expone a través de los tipos de espera siguiente (expuesto en las vistas sys.dm_exec_requests y sys.dm_os_wait_stats):
| Tipo de espera | Notas |
|---|---|
LOG_RATE_GOVERNOR |
Limitación de la base de datos |
POOL_LOG_RATE_GOVERNOR |
Limitación del grupo |
INSTANCE_LOG_RATE_GOVERNOR |
Limitación del nivel de instancia |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Control de comentarios, la replicación física del grupo de disponibilidad en el nivel de servicio Crítico para la empresa/Premium no está al día |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Control de comentarios, limitación de las tasas para evitar quedarse sin espacio para registros |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Control de comentarios de replicación geográfica, limitación de la velocidad de registro para evitar una alta latencia de los datos y la no disponibilidad de replicaciones geográficas secundarias |
Cuando encuentre un límite para las tasas de registros que dificulte la alcanzar la escalabilidad deseada, considere estas opciones:
- Escale verticalmente hasta un nivel de servicio superior para obtener la velocidad máxima de registro de un nivel de servicio, o cambie a otro nivel de servicio. El nivel de servicio Hiperescala proporciona una velocidad de registro de 100 MB/s por base de datos y 125 MB/s por grupo elástico, independientemente del nivel de servicio elegido. La tasa de generación de registros de 150 MB/s está disponible como característica en vista previa (GB) opcional. Para más información y participar en 150 MB/s, vea Blog: Mejoras de Hiperescala de noviembre de 2024.
- Si los datos que se cargan son transitorios, como los datos de ensayo de un proceso de ETL, se pueden cargar en
tempdb(que genera un mínimo de registros). - En el caso de escenarios analíticos, cargue en una tabla de almacén de columnas en clústeres o en una tabla con índices que usen la compresión de datos. Esto disminuye la tasa de registros necesaria. Esta técnica sí aumenta la utilización de la CPU y solo se aplica a los conjuntos de datos que se benefician de los índices de almacén de columnas en clúster o la compresión de datos.
Gobernanza del espacio de almacenamiento
En los niveles de servicio Premium y Crítico para la empresa, los datos del cliente, incluidos los archivos de datos, los archivos de registro de transacciones y los archivos tempdb, se guardan en el almacenamiento SSD local de la máquina que hospeda la base de datos o el grupo elástico. El almacenamiento SSD local proporciona un número elevado de IOPS y un alto rendimiento, así como una baja latencia de E/S. Además de los datos del cliente, el almacenamiento local se usa para el sistema operativo, el software de administración, los datos y registros de supervisión y otros archivos necesarios para el funcionamiento del sistema.
El tamaño del almacenamiento local es finito y depende de las funcionalidades de hardware, que determinan el límite de almacenamiento local máximo, o el almacenamiento local reservado para los datos del cliente. Este límite se establece para maximizar el almacenamiento de datos del cliente, a la vez que se garantiza un funcionamiento seguro y confiable del sistema. Para encontrar el valor máximo de almacenamiento local para cada objetivo de servicio, consulte la documentación sobre los límites de recursos para bases de datos únicas y grupos elásticos.
También puede encontrar este valor y la cantidad de almacenamiento local que usa actualmente una base de datos determinada o un grupo elástico mediante la consulta siguiente:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Columna | Descripción |
|---|---|
server_name |
Nombre del servidor lógico |
database_name |
Nombre de la base de datos |
slo_name |
Nombre del objetivo de servicio, incluida la generación de hardware |
user_data_directory_space_quota_mb |
Almacenamiento local máximo, en MB |
user_data_directory_space_usage_mb |
Consumo de almacenamiento local actual por archivos de datos, archivos de registro de transacciones y archivos tempdb, en MB. Se actualiza cada cinco minutos. |
Esta consulta debe ejecutarse en la base de datos de usuario, no en la base de datos master. En el caso de los grupos elásticos, la consulta se puede ejecutar en cualquier base de datos del grupo. Los valores notificados se aplican a todo el grupo.
Importante
En los niveles de servicio Premium y Crítico para la empresa, si la carga de trabajo intenta aumentar el consumo de almacenamiento local combinado por archivos de datos, archivos de registro de transacciones y archivos tempdb por encima del límite máximo de almacenamiento local, se producirá un error de espacio insuficiente. Esto ocurrirá incluso si el espacio usado en un archivo de base de datos no ha alcanzado el tamaño máximo del archivo.
El almacenamiento SSD local también se usa en bases de datos de niveles de servicio distintos del Premium y Crítico para la empresa para la base de datos tempdb y la caché RBPEX de Hiperescala. A medida que las bases de datos se crean, eliminan y aumentan o disminuyen de tamaño, el consumo total de almacenamiento local en una máquina fluctúa con el tiempo. Si el sistema detecta que el almacenamiento local disponible en una máquina es bajo y una base de datos o un grupo elástico corren el riesgo de quedarse sin espacio, mueve la base de datos o el grupo elástico a otra máquina con suficiente espacio de almacenamiento local disponible.
Este movimiento se produce en línea, de forma similar a una operación de escalado de bases de datos, y tiene un efecto parecido, por ejemplo, se produce una conmutación por error de corta duración (segundos) al final de la operación. Esta conmutación por error finaliza las conexiones abiertas y revierte las transacciones, lo que podría afectar a las aplicaciones que usan la base de datos en ese momento.
Como todos los datos se copian en volúmenes de almacenamiento local en diferentes máquinas, mover bases de datos más grandes en los niveles de servicio Premium y Crítico para la empresa puede requerir una cantidad considerable de tiempo. Durante ese tiempo, si el consumo de espacio local por una base de datos de usuarios o un grupo elástico, o por la base de datos tempdb, crece con rapidez, el riesgo de quedarse sin espacio aumenta. El sistema inicia el movimiento de la base de datos de manera equilibrada para minimizar errores de espacio insuficiente mientras se evitan las conmutaciones por error innecesarias.
Tamaños tempdb
Los límites de tamaño de tempdb en Azure SQL Database dependen del modelo de compra e implementación.
Para más información, revise los límites de tamaño de tempdb para:
- Modelo de compra de núcleo virtual: bases de datos únicas, bases de datos agrupadas
- Modelo de compra de DTU: bases de datos únicas, bases de datos agrupadas.
Hardware disponible anteriormente
En esta sección se incluyen detalles sobre el hardware disponible anteriormente.
- El hardware Gen4 ha sido retirado y no está disponible para el aprovisionamiento o el escalado vertical. Migre la base de datos a una generación de hardware compatible para obtener una gama más amplia de escalabilidad de almacenamiento y núcleos virtuales, redes aceleradas, un mejor rendimiento de E/S y una latencia mínima. Para obtener más información, consulte Finaliza la compatibilidad con el hardware de Gen 4 en Azure SQL Database.
Puede usar el Explorador de Azure Resource Graph para identificar todos los recursos de Azure SQL Database que usan actualmente hardware Gen4, o puede comprobar el hardware usado por los recursos de un servidor lógico específico en Azure Portal.
Debe tener al menos read permisos para el objeto o grupo de objetos de Azure para ver los resultados en el Explorador de Azure Resource Graph.
Para usar el Explorador de Resource Graph para identificar recursos de Azure SQL que todavía usan hardware Gen4, siga estos pasos:
Vaya a Azure Portal.
Busque
Resource graphen el cuadro de búsqueda y elija el servicio Explorador de Resource Graph en los resultados de búsqueda.En la ventana de consulta, escriba la siguiente consulta y, a continuación, seleccione Ejecutar consulta:
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"En el panel Resultados se muestran todos los recursos implementados actualmente en Azure que usan hardware Gen4.
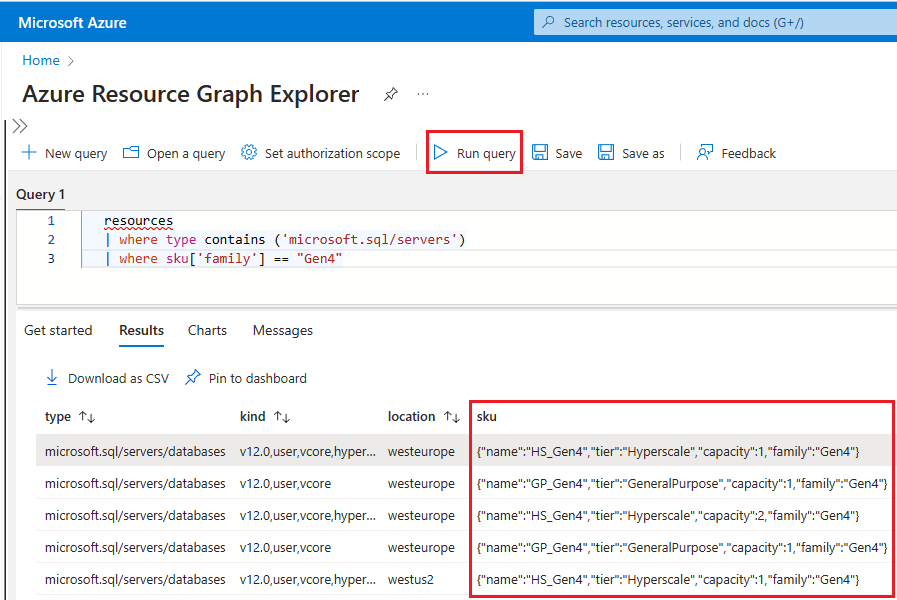
Para comprobar el hardware usado por los recursos de un servidor lógico específico en Azure, siga estos pasos:
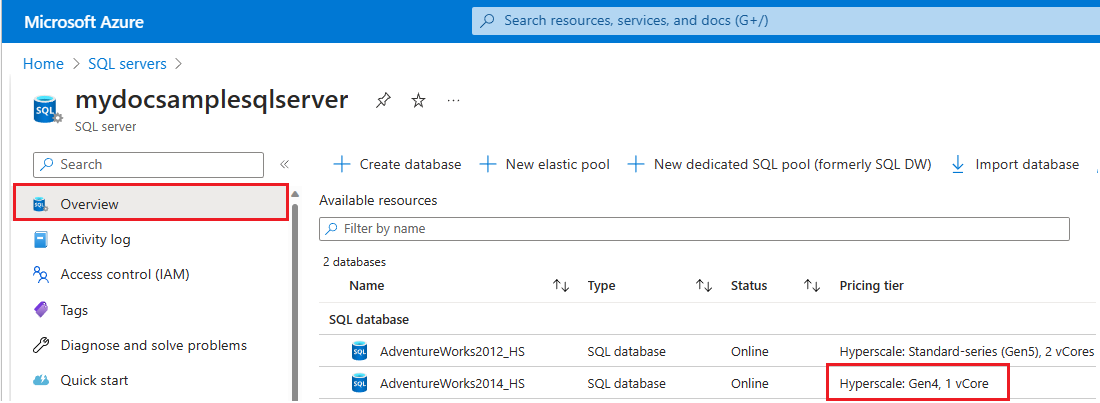
- Vaya a Azure Portal.
- Busque
SQL serversen el cuadro de búsqueda y elija Servidores SQL en los resultados de búsqueda para abrir la página Servidores SQL y ver todos los servidores de las suscripciones elegidas. - Seleccione el servidor de interés para abrir la página Información general del servidor.
- Desplácese hacia abajo hasta los recursos disponibles y compruebe la columna Plan de tarifa de los recursos que usan hardware gen4.
Para migrar recursos al hardware de la serie estándar, consulte Cambio de hardware.
Contenido relacionado
- Para más información sobre los límites generales de Azure, consulte Límites, cuotas y restricciones de suscripción y servicios de Microsoft Azure.
- Para más información sobre las DTU y eDTU, consulte DTU y eDTU.
- Para más información sobre los límites de tamaño de
tempdb, consulte bases de datos de un solo núcleo virtual, bases de datos de núcleos virtuales agrupados, bases de datos con una DTU y bases de datos con DTU agrupadas.