Resistencia y recuperación ante desastres en el servicio Azure Web PubSub
La resistencia y la recuperación ante desastres son necesidades comunes de los sistemas en línea. El servicio Azure Web PubSub ya garantiza una disponibilidad del 99,9 %, pero sigue siendo un servicio regional. Cuando se produce una interrupción en toda la región, es esencial que el servicio siga procesando mensajes en tiempo real en otra región.
Para la recuperación ante desastres regional, se recomiendan los dos enfoques siguientes:
- Habilite la replicación geográfica (manera sencilla). Esta característica controlará automáticamente la conmutación por error regional. Cuando está habilitada, solo hay una instancia de Azure SignalR y no se introduce ningún cambio de código. Compruebe la replicación geográfica para obtener más información.
- Use varios puntos de conexión. En este documento aprenderá a hacerlo .
Arquitectura de alta disponibilidad del servicio Web PubSub
Hay dos patrones típicos mediante el servicio Web PubSub:
- Uno es el patrón de servidor cliente que los clientes envían eventos al servidor y al servidor insertan mensajes a los clientes.
- Otro es el patrón cliente-cliente que los clientes pub/sub mensajes a través del servicio Web PubSub a otros clientes.
En las secciones siguientes se describen diferentes formas de realizar estas dos formas de realizar la recuperación ante desastres.
Arquitectura de alta disponibilidad para el patrón de cliente-servidor
Para conseguir resistencia entre regiones con el servicio Web PubSub, deberá configurar varias instancias de servicio en diferentes regiones. De manera que cuando una región esté inactiva, las demás se puedan usar como reserva.
Una configuración típica de un escenario interregional es tener dos (o más) pares de instancias de servicio Web PubSub y servidores de aplicaciones.
Dentro de cada par, el servidor de aplicaciones y el servicio Web PubSub se encuentran en la misma región y el servicio Web PubSub establece el controlador de eventos ascendente hacia el servidor de aplicaciones de la misma región.
Para ilustrar mejor la arquitectura, designamos el servicio Web PubSub como servicio principal para el servidor de aplicaciones del mismo par. Y designamos los servicios Web PubSub de otros pares como servicios secundarios para el servidor de aplicaciones.
El servidor de aplicaciones puede usar la API de comprobación de estado del servicio para detectar si sus servicios principal y secundario son correctos o no. Por ejemplo, para un servicio Web PubSub denominado demo, el punto de conexión https://demo.webpubsub.azure.com/api/health devuelve 200 cuando el estado del servicio es correcto. El servidor de aplicaciones puede llamar periódicamente a los puntos de conexión o llamar a los puntos de conexión a petición para comprobar si los puntos de conexión están en buen estado. Los clientes de WebSocket normalmente negocian primero con su servidor de aplicaciones para obtener la dirección URL que se conecta al servicio Web PubSub y la aplicación usa este paso de negociación para conmutar por error los clientes a otros servicios secundarios en buen estado. Los pasos detallados se indican a continuación:
- Cuando un cliente negocia con el servidor de aplicaciones, este solo DEBE devolver los puntos de conexión del servicio Web PubSub, por lo que, en caso normal, los clientes solo se conectan a los puntos de conexión principales.
- Cuando la instancia principal está inactiva, negotiate DEBE devolver un punto de conexión secundario en buen estado para que el cliente pueda realizar conexiones, y el cliente se conecta al punto de conexión secundario.
- Cuando la instancia principal está activa, la negociación DEBE devolver el punto de conexión principal correcto para que los clientes ahora puedan conectarse al punto de conexión principal.
- Cuando el servidor de aplicaciones quiera difundir mensajes, asegúrese de que lo hace a todos los puntos de conexión correctos, incluidos el principal y el secundario.
- El servidor de aplicaciones puede cerrar las conexiones conectadas a puntos de conexión secundarios para forzar que los clientes se vuelvan a conectar al punto de conexión principal correcto.
Con esta topología, todavía se puede entregar el mensaje de un servidor a todos los clientes, ya que todos los servidores de aplicaciones e instancias del servicio Web PubSub están interconectados.
Todavía no hemos integrado la estrategia en el SDK, por lo que por ahora la aplicación debe implementar esta estrategia por sí misma.
En resumen, lo que el lado de la aplicación debe implementar es:
- Comprobación de estado. La aplicación puede comprobar si el servicio está en buen estado mediante la API de comprobación de estado del servicio periódicamente en segundo plano o a petición para cada llamada de negociación.
- Lógica de negociación. La aplicación devuelve un punto de conexión principal correcto de forma predeterminada. Cuando el punto de conexión principal está inactivo, la aplicación devuelve un punto de conexión secundario correcto.
- Lógica de difusión. Cuando los mensajes se envían a varios clientes, la aplicación debe asegurarse de que transmite mensajes a todos los puntos de conexión correctos .
A continuación, un diagrama que ilustra esta topología:

Secuencia de conmutación por error y procedimiento recomendado
Ahora tiene la configuración de la topología de sistema correcta. Cada vez que una instancia del servicio Web PubSub está inactiva, el tráfico en línea se enruta a las demás. Esto es lo que ocurre cuando una instancia principal está inactiva (y se recupera tras algún tiempo):
- La instancia de servicio principal está inactiva: todos los clientes conectados a esta instancia se descartarán.
- Los nuevos clientes o los clientes nuevamente conectados negocian con el servidor de aplicaciones.
- El servidor de aplicaciones detecta que la instancia de servicio principal está inactiva y negocia que deje de devolver este punto de conexión y comience a devolver un punto de conexión secundario en buen estado.
- Los clientes se conectan a la instancia secundaria.
- Ahora la instancia secundaria toma todo el tráfico en línea. Todos los mensajes del servidor a los clientes pueden entregarse, ya que la instancia secundaria está conectada a todos los servidores de aplicaciones. Sin embargo, los mensajes de eventos de cliente a servidor solo se envían al servidor de aplicaciones ascendente de la misma región.
- Después de recuperar la instancia principal y volver a estar en línea, el servidor de aplicaciones detecta que la instancia principal vuelve a estar en buen estado. La negociación ahora vuelve a devolver el punto de conexión principal, de manera que los clientes se vuelven a conectar a la instancia principal. Sin embargo, los clientes existentes no se descartarán y continuarán conectados a la instancia secundaria hasta que ellos mismos de desconecten.
Los siguientes diagramas ilustran cómo se realiza la conmutación por error:
Fig.1 Antes de la conmutación por error 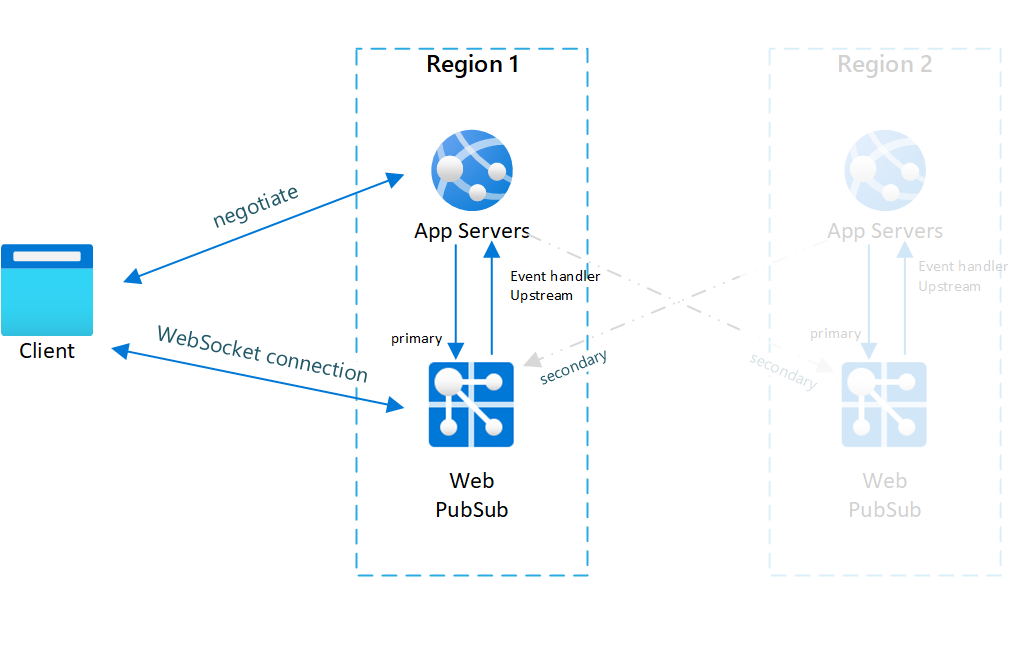
Fig.2 Después de la conmutación por error 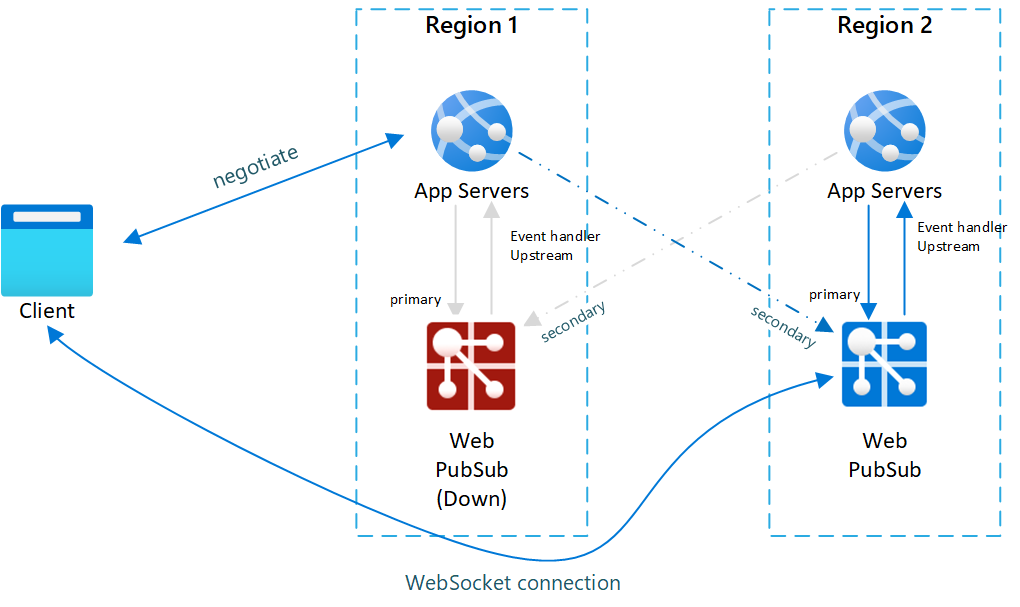
Fig.3 Breve tiempo después de la recuperación principal 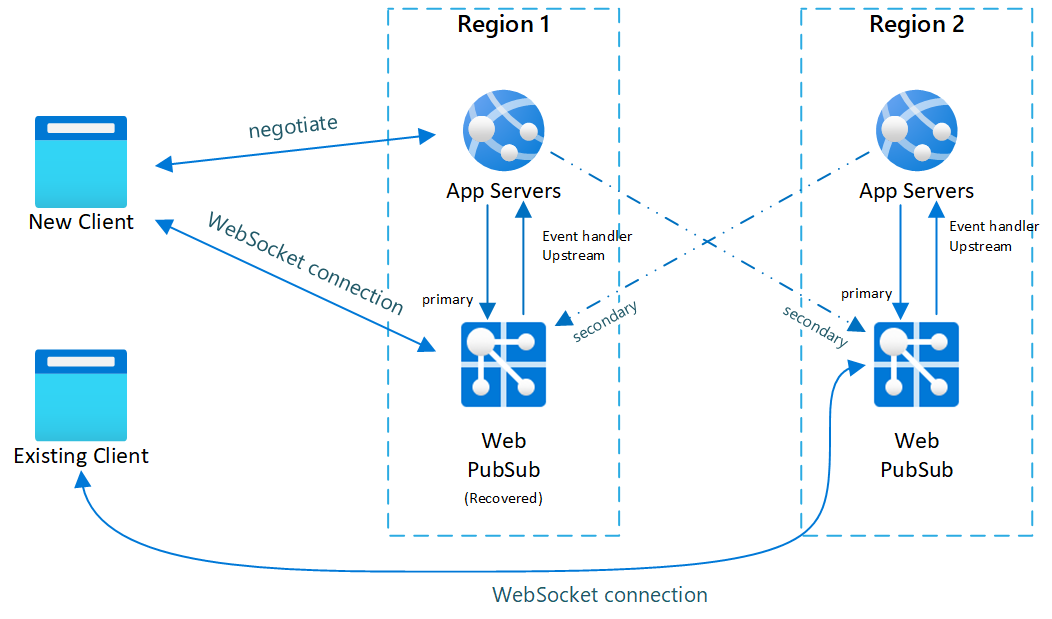
En los casos normales, solo el servidor de aplicaciones y el servicio Web PubSub tienen tráfico en línea (en azul).
Después de la conmutación por error, el servidor de aplicaciones y el servicio Web PubSub también se activan. Cuando el servicio Web PubSub principal vuelve a estar en línea, los nuevos clientes se conectarán a él. Pero los clientes existentes se seguirán conectando a la instancia secundaria, por lo que ambas instancias tendrán tráfico.
Una vez desconectados todos los clientes existentes, el sistema volverá a la normalidad (ilustración 1).
Hay dos patrones principales para implementar una arquitectura de alta disponibilidad entre regiones:
- El primero de ellos consiste en tener un par de servidor de aplicaciones e instancia de servicio Web PubSub que acepte todo el tráfico en línea y otro par como respaldo (lo que se denomina "activo/pasivo" en la Figura 1).
- El otro es tener dos (o más) pares de servidores de aplicaciones e instancias de servicio Web PubSub y que cada uno acepte parte del tráfico en línea y sirva de respaldo a los demás (lo que se denomina "activo/activo" en la Figura 3).
El servicio Web PubSub puede admitir ambos patrones; la principal diferencia es la manera de implementar los servidores de aplicaciones. Si son de tipo "activo/pasivo", el servicio Web PubSub también será "activo/pasivo" (ya que el servidor de aplicaciones principal solo devuelve su instancia de servicio Web PubSub principal). Si los servidores de aplicaciones son "activo/activo", el servicio Web PubSub también será "activo/activo" (ya que todos los servidores de aplicaciones devolverán sus propias instancias de Web PubSub principales, por lo que todos pueden recibir tráfico).
Tenga en cuenta que, independiente de los patrones que decida usar, deberá conectar cada instancia de servicio Web PubSub a un servidor de aplicaciones como rol principal.
Además, dada la naturaleza de la conexión de Web PubSub (es una conexión larga), los clientes experimentarán interrupciones de conexión cuando haya un desastre y se produzca una conmutación por error. Deberá tratar con esos casos desde el cliente para que sea transparente para los clientes finales. Por ejemplo, vuelva a realizar la conexión cuando se cierre.
Arquitectura de alta disponibilidad para el patrón de cliente-cliente
En el caso del patrón client-client, actualmente no es posible admitir una recuperación ante desastres en tiempo de inactividad cero mediante varias instancias. Si tiene requisitos de alta disponibilidad, considere la posibilidad de usar la replicación geográfica.
Prueba de una conmutación por error
Siga los pasos para desencadenar la conmutación por error:
- En la pestaña Redes del recurso principal del portal, deshabilite el acceso a la red pública. Si el recurso tiene habilitada la red privada, use reglas de control de acceso para denegar todo el tráfico.
- Reinicie el recurso principal.
Pasos siguientes
En este artículo ha aprendido a configurar la aplicación para lograr resistencia con el servicio Web PubSub.
Use estos recursos para empezar a compilar su propia aplicación: