Procedimientos recomendados de Azure Machine Learning para la seguridad empresarial
En este artículo se describen los procedimientos recomendados de seguridad al planear o administrar una implementación segura de Azure Machine Learning. Estos proceden de Microsoft y de la experiencia del cliente con Azure Machine Learning. En cada guía se explica la práctica y su lógica. En el artículo también se proporcionan vínculos a documentación de referencia y guías paso a paso.
Arquitectura de seguridad de red recomendada (red administrada)
La arquitectura de seguridad de red de aprendizaje automático recomendada es una red virtual administrada. Una red virtual administrada de Azure Machine Learning protege el área de trabajo, los recursos de Azure asociados y todos los recursos de proceso administrados. Simplifica la configuración y la administración de seguridad de la red mediante la configuración previa de las salidas necesarias y la creación automática de recursos administrados dentro de la red. Puede usar puntos de conexión privados para permitir que los servicios de Azure accedan a la red y, opcionalmente, puede definir reglas de salida para permitir que la red acceda a Internet.
La red virtual administrada tiene dos modos para los que se puede configurar:
Permitir la salida a Internet: este modo permite la comunicación saliente con recursos ubicados en Internet, como los repositorios de paquetes de Anaconda o PyPi públicos.

Permitir solo la salida aprobada: este modo solo permite la comunicación saliente mínima necesaria para que el área de trabajo funcione. Este modo se recomienda para aquellas áreas de trabajo que deben aislarse de Internet. O bien, allí donde solo se permite el acceso saliente a recursos específicos a través de puntos de conexión de servicio, etiquetas de servicio o nombres de dominio completos.

Para obtener más información, consulte Aislamiento de red virtual administrada.
Arquitectura de seguridad de red recomendada (Azure Virtual Network)
Si no puede usar una red virtual administrada debido a los requisitos empresariales, puede usar una instancia de Azure Virtual Network con las siguientes subredes:
- Entrenamiento: contiene los recursos de proceso que se usan para el entrenamiento, como las instancias de proceso o los clústeres de proceso de Machine Learning.
- Puntuación: contiene los recursos de proceso que se usan para la puntuación, como Azure Kubernetes Service (AKS).
- Firewall: contiene el firewall que permite el tráfico hacia y desde la red pública de Internet, por ejemplo, Azure Firewall.
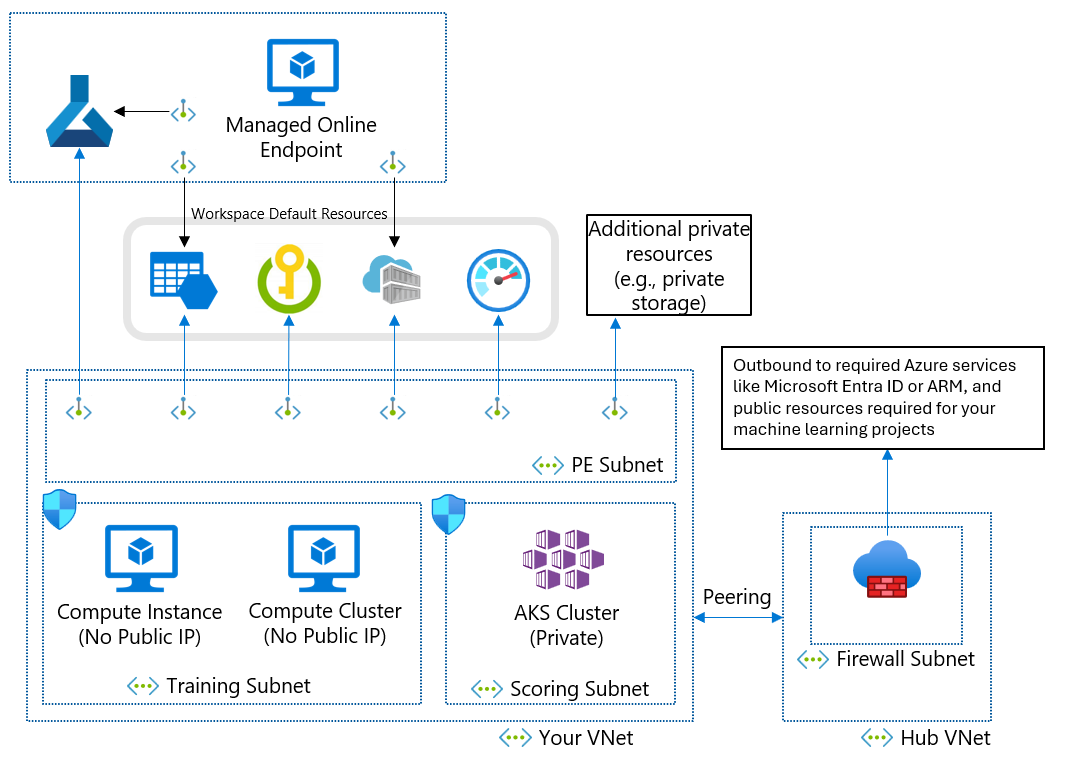
La red virtual también contiene un punto de conexión privado para el área de trabajo de Machine Learning y los siguientes servicios de dependencia:
- Cuenta de Azure Storage
- Azure Key Vault
- Azure Container Registry
La comunicación saliente desde la red virtual debe poderse realizar a los siguientes servicios de Microsoft:
- Machine Learning
- Microsoft Entra ID
- Azure Container Registry y registros específicos que mantiene Microsoft
- Azure Front Door
- Azure Resource Manager
- Azure Storage
Los clientes remotos se conectan a la red virtual mediante Azure ExpressRoute o una conexión de red privada virtual (VPN).
Diseño de red virtual y punto de conexión privado
Al diseñar una instancia de Azure Virtual Network, subredes y puntos de conexión privados, tenga en cuenta los siguientes requisitos:
En general, se recomienda crear distintas subredes para el entrenamiento y la puntuación, y usar la subred de entrenamiento para todos los puntos de conexión privados.
Para el direccionamiento IP, las instancias de proceso necesitan una dirección IP privada cada una. Los clústeres de proceso necesitan una dirección IP privada por nodo. Los clústeres de AKS necesitan muchas direcciones IP privadas, como se describe en Planeamiento de direccionamiento IP del clúster de AKS. Una subred independiente al menos para AKS ayuda a evitar el agotamiento de direcciones IP.
Los recursos de proceso de las subredes de entrenamiento y puntuación deben tener acceso a la cuenta de almacenamiento, al almacén de claves y al registro de contenedor. Cree puntos de conexión privados para la cuenta de almacenamiento, el almacén de claves y el registro de contenedor.
El almacenamiento predeterminado del área de trabajo de Machine Learning necesita dos puntos de conexión privados, uno para Azure Blob Storage y otro para Azure File Storage.
Si usa Estudio de Azure Machine Learning, el área de trabajo y los puntos de conexión privados de almacenamiento deben estar en la misma red virtual.
Si planea tener varias áreas de trabajo, use una red virtual para cada una a fin de crear un límite de red explícito entre ellas.
Uso de direcciones IP privadas
Las direcciones IP privadas reducen la exposición de los recursos de Azure a Internet. Machine Learning utiliza muchos recursos de Azure y el punto de conexión privado del área de trabajo de Machine Learning no es suficiente para la dirección IP privada completa. En la tabla siguiente se muestran los recursos principales que usa Machine Learning y cómo habilitar la dirección IP privada para ellos. Las instancias de proceso y los clústeres de proceso son los únicos recursos que no tienen la característica de dirección IP privada.
| Recursos | Solución de IP privada | Documentación |
|---|---|---|
| Área de trabajo | Punto de conexión privado | Configuración de un punto de conexión privado para un área de trabajo de Azure Machine Learning |
| Registro | Punto de conexión privado | Aislamiento de red con registros de Azure Machine Learning |
| Recursos asociados | ||
| Storage | Punto de conexión privado | Protección de cuentas de almacenamiento de Azure con puntos de conexión de servicio |
| Key Vault | Punto de conexión privado | Protección de Azure Key Vault |
| Container Registry | Punto de conexión privado | Habilitación de una instancia de Azure Container Registry |
| Recursos de entrenamiento | ||
| Instancia de proceso | Dirección IP privada (sin dirección IP pública) | Protección de entornos de entrenamiento |
| Clúster de proceso | Dirección IP privada (sin dirección IP pública) | Protección de entornos de entrenamiento |
| Recursos de hospedaje | ||
| Punto de conexión en línea administrado | Punto de conexión privado | Aislamiento de red con puntos de conexión en línea administrados |
| Punto de conexión en línea (Kubernetes) | Punto de conexión privado | Puntos de conexión seguros en línea de Azure Kubernetes Service |
| Puntos de conexión por lotes | Dirección IP privada (heredada del clúster de proceso) | Aislamiento de red en puntos de conexión por lotes |
Control del tráfico entrante y saliente de la red virtual
Use un firewall o un grupo de seguridad de red (NSG) de Azure para controlar el tráfico entrante y saliente de la red virtual. Para más información sobre los requisitos de entrada y salida, consulte Configuración del tráfico de red entrante y saliente. Para más información sobre cómo fluye el tráfico entre los componentes, consulte Flujo del tráfico de red en un área de trabajo protegida.
Garantía de acceso al área de trabajo
Para tener la seguridad de que el punto de conexión privado puede acceder al área de trabajo de Machine Learning, siga estos pasos:
Asegúrese de que tiene acceso a la red virtual mediante una conexión VPN, ExpressRoute o una máquina virtual (VM) JumpBox con acceso mediante Azure Bastion. El usuario público no puede acceder al área de trabajo de Machine Learning con el punto de conexión privado porque solo se puede acceder desde la red virtual. Para más información, consulte Protección de un área de trabajo de Azure Machine Learning con redes virtuales.
Asegúrese de que puede resolver los nombres de dominio completos (FQDN) del área de trabajo con su dirección IP privada. Si usa su propio servidor de Sistema de nombres de dominio (DNS) o una infraestructura de DNS centralizada, debe configurar un reenviador DNS. Para más información, consulte Uso de un área de trabajo con un servidor DNS personalizado.
Administración del acceso al área de trabajo
Al definir controles de administración de identidades y acceso de Machine Learning, puede distinguir entre los que definen el acceso a los recursos de Azure y los que administran el acceso a los recursos de datos. En función de su caso de uso, considere la posibilidad de utilizar la administración de identidades y acceso de autoservicio, centrada en los datos o centrada en el proyecto.
Patrón de autoservicio
En el patrón de autoservicio, los científicos de datos pueden crear y administrar áreas de trabajo. Este patrón es más adecuado para situaciones de prueba de concepto que requieren flexibilidad para probar diferentes configuraciones. La desventaja es que los científicos de datos necesitan la experiencia necesaria para aprovisionar recursos de Azure. Este enfoque es menos adecuado cuando se requieren un control estricto, el uso de recursos, seguimientos de auditoría y el acceso a los datos.
Defina directivas de Azure para establecer medidas de seguridad para el aprovisionamiento y el uso de recursos, como los tamaños de clúster y los tipos de máquina virtual permitidos.
Cree un grupo de recursos que contenga las áreas de trabajo y conceda a los científicos de datos el rol de colaborador en él.
Los científicos de datos pueden crear ahora áreas de trabajo y asociar recursos del grupo de recursos en modo de autoservicio.
Para acceder al almacenamiento de datos, cree identidades administradas asignadas por el usuario y concédales roles de acceso de lectura en el almacenamiento.
Cuando los científicos de datos crean recursos de proceso, pueden asignar las identidades administradas a las instancias de proceso para acceder a los datos.
Para conocer los procedimientos recomendados, consulte Autenticación para el análisis a escala de la nube en Azure.
Patrón centrado en los datos
En el patrón centrado en los datos, el área de trabajo pertenece a un único científico de datos que puede estar trabajando en varios proyectos. La ventaja de este enfoque es que el científico de datos puede reutilizar el código y las canalizaciones de entrenamiento entre proyectos. Siempre que el área de trabajo se limite a un solo usuario, se puede realizar un seguimiento del acceso a los datos de ese usuario al auditar los registros de almacenamiento.
La desventaja es que el acceso a los datos no está compartimentado ni restringido por proyecto, y cualquier usuario agregado al área de trabajo puede acceder a los mismos recursos.
Cree el área de trabajo.
Cree los recursos de proceso con las identidades administradas asignadas por el sistema habilitadas.
Cuando el científico de datos necesite acceso a los datos de un proyecto determinado, conceda a la identidad administrada de proceso acceso de lectura a los datos.
Conceda a la identidad administrada de proceso acceso a cualquier otro recurso necesario, como un registro de contenedor con imágenes personalizadas de Docker para el entrenamiento.
Conceda también a la identidad administrada del área de trabajo el rol de acceso de lectura en los datos para permitir su vista previa.
Conceda al científico de datos acceso al área de trabajo.
Ahora, el científico de datos puede crear almacenes de datos para acceder a los datos necesarios para los proyectos y enviar ejecuciones de entrenamiento que usen los datos.
También puede crear un grupo de seguridad de Microsoft Entra y concederle acceso de lectura a los datos y, luego, agregarle las identidades administradas. Este enfoque reduce el número de asignaciones de roles directas en los recursos, para evitar alcanzar el límite de la suscripción.
Patrón centrado en el proyecto
En el patrón centrado en el proyecto se crea un área de trabajo de Machine Learning para un proyecto específico y muchos científicos de datos colaboran en la misma área de trabajo. El acceso a los datos está restringido al proyecto específico, lo que hace que el enfoque sea adecuado para trabajar con datos confidenciales. Además, resulta sencillo agregar o quitar científicos de datos en el proyecto.
La desventaja de este enfoque es que compartir recursos entre proyectos puede ser difícil. También, es difícil realizar un seguimiento del acceso a los datos a usuarios específicos durante las auditorías.
Creación del área de trabajo
Identifique las instancias de almacenamiento de datos necesarias para el proyecto, cree una identidad administrada asignada por el usuario y concédale acceso de lectura al almacenamiento.
También puede conceder a la identidad administrada del área de trabajo acceso al almacenamiento de datos para permitir la vista previa de los datos. Este paso se puede omitir con datos confidenciales que no son adecuados para la vista previa.
Cree almacenes de datos sin credenciales para los recursos de almacenamiento.
Cree recursos de proceso dentro del área de trabajo y asígneles la identidad administrada.
Conceda a la identidad administrada de proceso acceso a cualquier otro recurso necesario, como un registro de contenedor con imágenes personalizadas de Docker para el entrenamiento.
Conceda a los científicos de datos que trabajan en el proyecto un rol en el área de trabajo.
Mediante el control de acceso basado en rol (RBAC) de Azure, puede impedir que los científicos de datos creen nuevos almacenes de datos o nuevos recursos de proceso con identidades administradas diferentes. Esta práctica impide el acceso a datos no específicos del proyecto.
Opcionalmente, para simplificar la administración de la pertenencia a proyectos, puede crear un grupo de seguridad de Microsoft Entra para los miembros del proyecto y concederle acceso al área de trabajo.
Azure Data Lake Storage con paso de credenciales
Puede usar la identidad de usuario de Microsoft Entra para el acceso al almacenamiento interactivo desde el estudio de aprendizaje automático. Data Lake Storage con el espacio de nombres jerárquico habilitado permite una organización mejorada de los recursos de datos para el almacenamiento y la colaboración. Con el espacio de nombres jerárquico de Data Lake Storage, puede proporcionar a diferentes usuarios acceso ACL (lista de control de acceso) a diferentes carpetas y archivos para compartimentar los datos. Por ejemplo, puede conceder acceso a los datos confidenciales solo a un subconjunto de usuarios.
RBAC y roles personalizados
Azure RBAC le ayuda a administrar quién tiene acceso a los recursos de Machine Learning y a configurar quién puede realizar operaciones. Por ejemplo, puede que le interese conceder el rol de administrador del área de trabajo solo a usuarios específicos para administrar los recursos de proceso.
El ámbito de acceso puede variar según el entorno. En entornos de producción, puede que quiera limitar la capacidad de los usuarios para actualizar los puntos de conexión de inferencia. En su lugar, ese permiso podría concederse a una entidad de servicio autorizada.
Machine Learning tiene varios roles predeterminados: propietario, colaborador, lector y científico de datos. También puede crear sus propios roles personalizados, por ejemplo, para crear permisos que reflejen la estructura de su organización. Para obtener más información, consulte Administración del acceso a un área de trabajo de Azure Machine Learning.
Con el tiempo, la composición del equipo puede cambiar. Si crea un grupo de Microsoft Entra para cada rol de equipo y área de trabajo, puede asignar un rol de Azure RBAC al grupo de Microsoft Entra y administrar el acceso a los recursos y los grupos de usuarios por separado.
Las entidades de seguridad de usuario y las entidades de servicio pueden formar parte del mismo grupo de Microsoft Entra. Por ejemplo, al crear una identidad administrada asignada por el usuario que se usa en Azure Data Factory para desencadenar una canalización de aprendizaje automático, podría incluirla en un grupo de Microsoft Entra llamado ejecutor de canalizaciones de ML.
Administración central de imágenes de Docker
Azure Machine Learning proporciona imágenes de Docker mantenidas que puede usar para el entrenamiento y la implementación. Sin embargo, los requisitos de cumplimiento de la empresa pueden obligar al uso de imágenes de un repositorio privado administrado por la empresa. Machine Learning tiene dos maneras de usar un repositorio central:
Utilice las imágenes de un repositorio central como imágenes base. La administración del entorno de Machine Learning instala los paquetes y crea un entorno de Python en el que se ejecuta el código de entrenamiento o inferencia. Con este enfoque, puede actualizar las dependencias del paquete fácilmente sin tener que modificar la imagen base.
Usar las imágenes tal y como están, sin utilizar la administración del entorno de Machine Learning. Este enfoque proporciona un mayor grado de control, pero también requiere que construya cuidadosamente el entorno de Python como parte de la imagen. Se deben cumplir todas las dependencias necesarias para ejecutar el código y todas las dependencias nuevas requieren recompilar la imagen.
Para obtener más información, consulte Administrar entornos.
Cifrado de datos
Los datos en reposo de Machine Learning tiene dos orígenes de datos:
Todos los datos están en el almacenamiento, incluidos los datos de entrenamiento y del modelo entrenado, excepto los metadatos. Usted es responsable del cifrado de almacenamiento.
Azure Cosmos DB contiene los metadatos, incluida la información del historial de ejecución, como el nombre del experimento y la fecha y hora de su envío. En la mayoría de las áreas de trabajo, Azure Cosmos DB se encuentra en una suscripción de Microsoft y se cifra mediante una clave administrada por Microsoft.
Si quiere cifrar los metadatos mediante su propia clave, puede usar un área de trabajo de clave administrada por el cliente. El inconveniente es que debe tener Azure Cosmos DB en su suscripción y pagar lo que cueste. Para más información, consulte Cifrado de datos con Azure Machine Learning.
Para información sobre cómo Azure Machine Learning cifra los datos en tránsito, consulte Cifrado de datos en tránsito.
Supervisión
Al implementar recursos de Machine Learning, configure los controles de registro y auditoría para la observabilidad. Las motivaciones para observar los datos pueden variar en función de quién los examina. Los escenarios incluyen:
Los profesionales de aprendizaje automático o los equipos de operaciones necesitan supervisar el estado de la canalización de aprendizaje automático. Estos observadores deben comprender los problemas de la ejecución programada o los problemas con la calidad de los datos o el rendimiento esperado del entrenamiento. Puede crear paneles de Azure que supervisen lo datos de Azure Machine Learning o crear flujos de trabajo basados en eventos.
Los administradores de capacidad, los profesionales de aprendizaje automático o los equipos de operaciones pueden estar interesados en crear un panel para observar el uso de del proceso y la cuota. Para administrar una implementación con varias áreas de trabajo de Azure Machine Learning, considere la posibilidad de crear un panel central para comprender el uso de la cuota. Las cuotas se administran en el nivel de suscripción, por lo que es importante tener una panorámica de todo el entorno para favorecer la optimización.
Los equipos de TI y operaciones pueden configurar el registro de diagnóstico para auditar el acceso a los recursos y modificar los eventos dentro del área de trabajo.
Considere la posibilidad de crear paneles que supervisen el estado general de la infraestructura para recursos de Machine Learning y dependientes, como el almacenamiento. Por ejemplo, la combinación de métricas de Azure Storage con datos de ejecución de canalizaciones puede ayudarle a optimizar la infraestructura para mejorar el rendimiento, o a detectar las causas principales de un problema.
Azure recopila y almacena las métricas de plataforma y los registros de actividad automáticamente. Puede enrutar los datos a otras ubicaciones mediante una configuración de diagnóstico. Configure el registro de diagnóstico en un área de trabajo centralizada de Log Analytics para permitir la observabilidad entre varias instancias de área de trabajo. Use Azure Policy para configurar automáticamente el registro de nuevas áreas de trabajo de Machine Learning en este área de trabajo central de Log Analytics.
Azure Policy
Puede aplicar y auditar el uso de las características de seguridad en las áreas de trabajo mediante Azure Policy. Entre las recomendaciones se incluyen las siguientes:
- Aplicar el cifrado con clave administrada personalizada.
- Aplicar Azure Private Link y puntos de conexión privados.
- Aplicar zonas DNS privadas.
- Deshabilitar la autenticación que no sea de Azure AD, como Secure Shell (SSH).
Para más información, consulte Definiciones de directivas integradas de Azure Policy para Azure Machine Learning.
También, puede usar definiciones de directiva personalizadas para controlar la seguridad del área de trabajo de una manera flexible.
Clústeres e instancias de proceso
Las siguientes consideraciones y recomendaciones se aplican a los clústeres y las instancias de proceso de Machine Learning.
Cifrado de discos
El disco del sistema operativo (SO) de un nodo de instancia de proceso o de clúster de proceso se almacena en Azure Storage y se cifra con claves administradas por Microsoft. Cada nodo también tiene un disco temporal local. El disco temporal también se cifra con claves administradas por Microsoft si el área de trabajo se creó con el parámetro hbi_workspace = True. Para más información, consulte Cifrado de datos con Azure Machine Learning.
Identidad administrada
Los clústeres de proceso admiten el uso de identidades administradas para autenticarse en los recursos de Azure. El uso de una identidad administrada para el clúster permite autenticarse en los recursos sin exponer las credenciales en el código. Para más información, consulte Creación de un clúster de proceso de Azure Machine Learning.
Configuración de un script
Puede usar un script de configuración para automatizar la personalización y la configuración de instancias de proceso cuando se crean. Como administrador, puede escribir un script de personalización para usarlo al crear todas las instancias de proceso de un área de trabajo. Puede usar Azure Policy con el fin de aplicar el uso del script de configuración para crear cada instancia de proceso. Para más información, consulte Creación y administración de una instancia de proceso de Azure Machine Learning.
Creación en nombre de alguien
Si no quiere que los científicos de datos aprovisionen recursos de proceso, puede crear instancias de proceso en su nombre y asignárselas a estos. Para más información, consulte Creación y administración de una instancia de proceso de Azure Machine Learning.
Área de trabajo habilitada para puntos de conexión privados
Use instancias de proceso con un área de trabajo habilitada para puntos de conexión privados. La instancia de proceso rechaza todo el acceso público desde fuera de la red virtual. Esta configuración también impide el filtrado de paquetes.
Compatibilidad con Azure Policy
Al usar una instancia de Azure Virtual Network, puede usar Azure Policy para asegurarse de que todos los clústeres o instancias de proceso se crean en una red virtual y especificar la red virtual y la subred predeterminadas. La directiva no es necesaria cuando se usa una red virtual administrada, ya que los recursos de proceso se crean automáticamente en la red virtual administrada.
También puede usar una directiva para deshabilitar la autenticación que no sea de Azure AD, como SSH.
Pasos siguientes
Más información sobre las configuraciones de seguridad de Machine Learning:
- Seguridad de empresa y gobernanza para Azure Machine Learning
- Protección de los recursos del área de trabajo de Azure Machine Learning con redes virtuales (VNet)
Empiece a trabajar con la implementación basada en plantillas de Machine Learning:
- Plantillas de inicio rápido de Azure (
microsoft.com) - Zona de aterrizaje de datos de análisis de escala empresarial e inteligencia artificial
Lea más artículos sobre las consideraciones de arquitectura para implementar Machine Learning:
Conozca cómo la estructura del equipo, el entorno o las restricciones regionales afectan a la configuración del área de trabajo.
Vea cómo administrar los costos de proceso y el presupuesto entre equipos y usuarios.
Aprenda sobre DevOps de aprendizaje automático (MLOps), que usa una combinación de personas, procesos y tecnología para ofrecer soluciones de aprendizaje automático sólidas, confiables y automatizadas.