Supervisión de unidades de solicitud normalizadas para un contenedor de Azure Cosmos DB o una cuenta
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Monitor para Azure Cosmos DB proporciona una vista de métricas para supervisar la cuenta y crear paneles. Las métricas de Azure Cosmos DB se recopilan de forma predeterminada, esta característica no requiere que habilite ni configure nada explícitamente.
Definición métrica
La métrica Consumo de RU normalizado es una métrica entre el 0 % y el 100 % que se usa para ayudar a medir el uso del rendimiento aprovisionado en una base de datos o contenedor. La métrica se emite a intervalos de 1 minuto y se define como el uso máximo de RU/s en todos los intervalos de claves de partición en el intervalo de tiempo. Cada rango de claves de partición se asigna a una partición física y se asigna para contener datos para un intervalo de valores hash posibles. En general, cuanto mayor sea el porcentaje de RU normalizado, más ha usado el rendimiento aprovisionado. La métrica también se puede usar para ver el uso de intervalos de claves de partición individuales en una base de datos o contenedor.
Por ejemplo, supongamos que tiene un contenedor en el que establece el rendimiento máximo de escalabilidad automática de 20 000 RU/s (escala entre 2000 y 20 000 RU/s) y tiene dos intervalos de claves de partición (particiones físicas) P1 y P2. Dado que Azure Cosmos DB distribuye el rendimiento aprovisionado de forma equitativa entre todos los intervalos de claves de partición, P1 y P2, cada uno puede escalar entre 1000 y 10 000 RU/s. Supongamos que en un intervalo de 1 minuto, en un segundo determinado, P1 consumió 6000 unidades de solicitud y P2 consumió 8000 unidades de solicitud. El consumo normalizado de RU de P1 es del 60 % y del 80 % para P2. El consumo general de RU normalizado de todo el contenedor es MAX(60 %, 80 %) = 80 %.
Si está interesado en ver el consumo de unidad de solicitud en un intervalo por segundo, junto con el tipo de operación, puede usar la característica de participación Registros de diagnóstico y consultar la tabla PartitionKeyRUConsumption. Para obtener información general de alto nivel sobre las operaciones y el código de estado que realiza la aplicación en el recurso de Azure Cosmos DB, puede usar la métrica integrada Solicitudes totales de Azure Monitor (API for NoSQL), Solicitudes de Mongo, Solicitudes de Gremlin o Solicitudes de Cassandra. Posteriormente, puede filtrar estas solicitudes por el código de estado 429 y dividirlas por Tipo de operación.
Qué esperar y hacer cuando el consumo de RU/s normalizado es mayor
Cuando el consumo de RU normalizado alcanza el 100 % para el intervalo de claves de partición determinado, y si un cliente sigue realizando solicitudes en esa ventana de tiempo de 1 segundo a ese intervalo de claves de partición específico, recibe un error de velocidad limitada (429).
Esto no significa necesariamente que haya un problema con el recurso. De manera predeterminada, los SDK de cliente de Azure Cosmos DB y las herramientas de importación de datos, como Azure Data Factory y la biblioteca de Bulk Executor, reintentan automáticamente las solicitudes con errores 429. Normalmente, las reintenten hasta 9 veces. Como resultado, aunque pueda ver errores 429 en las métricas, es posible que estos errores ni siquiera se hayan devuelto a la aplicación.
En general, para una carga de trabajo de producción, si ve entre el 1 y el 5 % de las solicitudes con errores 429 y la latencia de un extremo a otro es aceptable, se trata de una señal correcta de que las RU/s se están empleando completamente. En este caso, la métrica de consumo de RU normalizada que alcanza el 100 % solo significa que en un segundo determinado, al menos un intervalo de claves de partición usó todo su rendimiento aprovisionado. Esto es aceptable porque la tasa global de errores 429 sigue siendo baja. No es necesario hacer nada.
Para determinar qué porcentaje de las solicitudes a la base de datos o el contenedor dieron lugar a errores 429, en la hoja de la cuenta de Azure Cosmos DB, vaya a Ideas>Solicitudes>Solicitudes por código de estado. Filtre por una base de datos y un contenedor específicos. En el caso de la API para Gremlin, use la métrica Solicitudes de Gremlin.
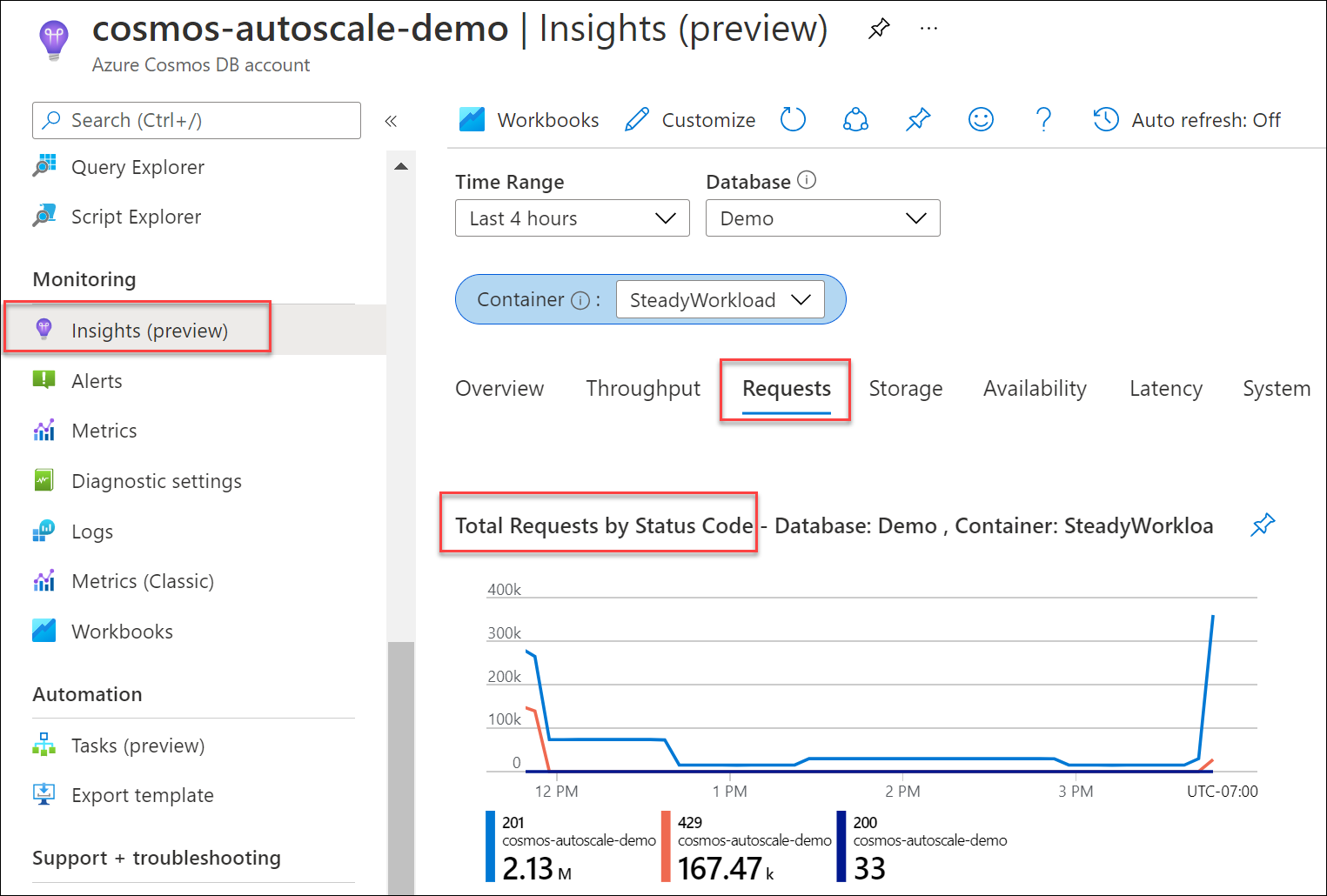
Si la métrica de consumo de RU normalizada es constantemente del 100 % en varios intervalos de claves de partición y la tasa de errores 429 es mayor que el 5 %, se recomienda aumentar el rendimiento. Puede averiguar qué operaciones son de consumo intenso y su uso máximo al usar las métricas de Azure Monitor y los registros de diagnósticos de Azure Monitor. Siga los procedimientos recomendados para escalar el rendimiento aprovisionado (RU/s).
No siempre es el caso de que vea un error de limitación de velocidad de 429 solo porque la RU normalizada ha alcanzado el 100 %. Esto se debe a que la RU normalizada es un valor único que representa el uso máximo de todos los intervalos de claves de partición. Un intervalo de claves de partición puede estar ocupado, pero los demás intervalos de claves de partición pueden atender las solicitudes sin problemas Por ejemplo, una sola operación, como un procedimiento almacenado que consume todas las RU/s en un intervalo de claves de partición, dará lugar a un breve aumento en la métrica de consumo de RU/s normalizado. En tales casos, no habrá errores de velocidad limitada inmediatos si la velocidad general de solicitudes es baja o se realizan solicitudes a otras particiones a intervalos de claves de partición distintos.
Obtenga más información sobre cómo interpretar y depurar excepciones de límite de velocidad 429.
Supervisión de particiones de nivel de acceso frecuente
La métrica de consumo de RU normalizada se puede usar para supervisar si la carga de trabajo tiene una partición de nivel de acceso frecuente. Una partición de nivel de acceso frecuente surge cuando una o varias claves de partición lógica consumen una cantidad desproporcionada del total de RU/s debido a un mayor volumen de solicitudes. Esto puede deberse a un diseño de clave de partición que no distribuye uniformemente las solicitudes. Como resultado, muchas solicitudes se dirigen a un pequeño subconjunto de particiones lógicas (lo que implica rangos de clave de partición) que pasan a ser de "nivel de acceso frecuente". Dado que todos los datos de una partición lógica residen en una partición física y el total de RU/s se distribuye uniformemente entre todos los rangos de clave de particiones, una partición de nivel de acceso frecuente puede dar lugar a errores 429 y a un uso ineficaz del rendimiento.
Cómo identificar si hay una partición de nivel de acceso frecuente
Para comprobar si hay una partición de nivel de acceso frecuente, vaya a Insights>Rendimiento>Normalized RU Consumption (%) By PartitionKeyRangeID (Consumo de RU normalizado [%] por PartitionKeyRangeID). Filtre por una base de datos y un contenedor específicos.
Cada objeto PartitionKeyRangeId se asigna a una partición física. Si hay un objeto PartitionKeyRangeId cuyo consumo de RU normalizado es significativamente mayor que el de los demás (por ejemplo, es del 100 %, pero el de los demás es del 30 % o menos), puede ser un signo de que se trata de una partición de nivel de acceso frecuente.
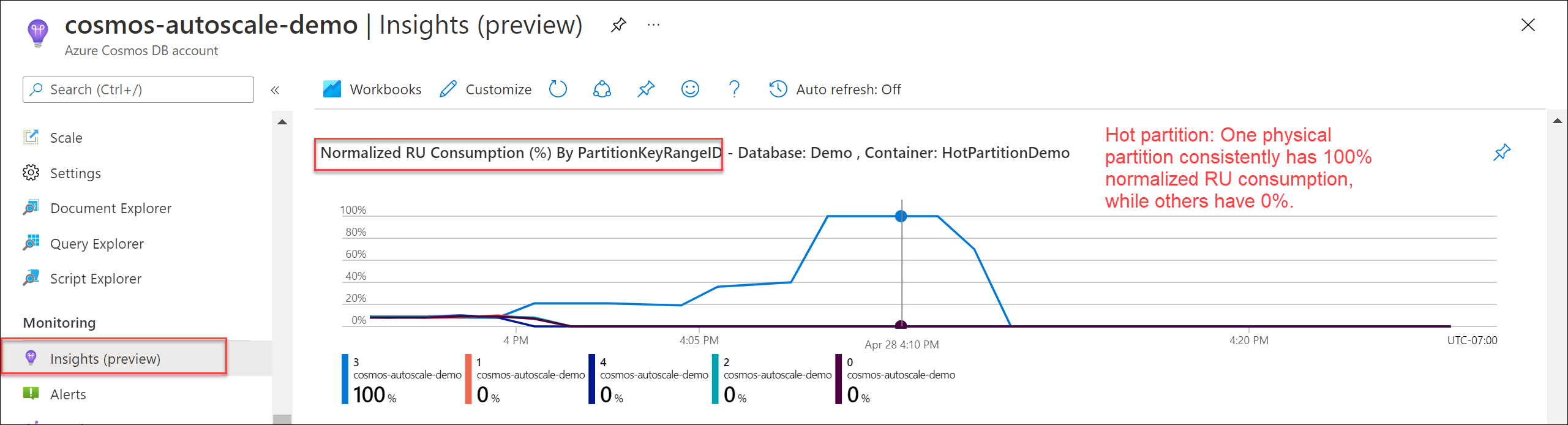
Para identificar las particiones lógicas que consumen la mayoría de las RU/s, así como las soluciones recomendadas, consulte el artículo Diagnóstico y solución de problemas de excepciones de tasa de solicitudes de Azure Cosmos DB demasiado grande (429).
Consumo de RU normalizado y escalabilidad automática
La métrica de consumo de RU normalizada se mostrará como 100 % si al menos un intervalo de claves de partición usa todas sus RU/s asignadas en cualquier segundo dado en el intervalo de tiempo. Una pregunta común que surge es, ¿por qué se normaliza el consumo de RU al 100 %, pero Azure Cosmos DB no escaló las RU/s al rendimiento máximo con escalabilidad automática?
Nota
La información siguiente describe la implementación actual de escalabilidad automática y puede estar sujeta a cambios en el futuro.
Cuando se usa el escalado automático, Azure Cosmos DB solo escala las RU/s al rendimiento máximo cuando el consumo de RU normalizado es del 100 % durante un período de tiempo continuo y sostenido en un intervalo de 5 segundos. Esto se hace para garantizar que la lógica de escalado sea rentable para el usuario, ya que garantiza que los picos únicos e momentáneos no conducen a un escalado innecesario y un costo mayor. Cuando hay picos momentáneos, el sistema normalmente se escala verticalmente hasta un valor mayor que el escalado anterior a RU/s, pero menor que el número máximo de RU/s.
Por ejemplo, supongamos que tiene un contenedor con un rendimiento máximo de escalabilidad automática de 20 000 RU/s (escala entre 2000 y 20 000 RU/s) y dos intervalos de claves de partición. Cada intervalo de claves de partición puede escalar entre 1000 y 10 000 RU/s. Dado que la escalabilidad automática aprovisiona todos los recursos necesarios por adelantado, puede usar hasta 20 000 RU/s en cualquier momento. Supongamos que tiene un pico intermitente de tráfico, donde para un solo segundo, el uso de uno de los intervalos de claves de partición es de 10 000 RU/s. En segundos posteriores, el uso retrocede a 1000 RU/s. Dado que la métrica de consumo de RU normalizada muestra el uso más alto en el período de tiempo en todas las particiones, mostrará el 100 %. Sin embargo, dado que el uso solo era del 100 % durante 1 segundo, la escalabilidad automática no se escalará automáticamente al máximo.
Como resultado, aunque la escalabilidad automática no se escaló hasta el máximo, todavía podía usar el total de RU/s disponibles. Para comprobar el consumo de RU/s, puede usar la característica de participación Registros de diagnóstico para consultar el consumo total de RU/s en un nivel por segundo en todos los intervalos de claves de partición.
CDBPartitionKeyRUConsumption
| where TimeGenerated >= (todatetime('2022-01-28T20:35:00Z')) and TimeGenerated <= todatetime('2022-01-28T20:40:00Z')
| where DatabaseName == "MyDatabase" and CollectionName == "MyContainer"
| summarize sum(RequestCharge) by bin(TimeGenerated, 1sec), PartitionKeyRangeId
| render timechart
En general, para una carga de trabajo de producción, si ve entre el 1 y el 5 % de las solicitudes con errores 429 y la latencia de un extremo a otro es aceptable, se trata de una señal correcta de que las RU/s se están empleando completamente. Incluso si el consumo normalizado de RU alcanza ocasionalmente el 100 % y la escalabilidad automática no escala verticalmente hasta el máximo de RU/s, esto es correcto porque la tasa general de errores 429 es baja. No se requiere ninguna acción.
Sugerencia
Si usa la escalabilidad automática y observa que el consumo normalizado de RU es constantemente del 100 % y se escala de forma coherente a las RU/s máximas, esto es un signo de que el uso del rendimiento manual puede ser más rentable. Para determinar si la escalabilidad automática o el rendimiento manual es mejor para la carga de trabajo, consulte cómo elegir entre el rendimiento aprovisionado estándar (manual) y la escalabilidad automática. Azure Cosmos DB también envía recomendaciones de Azure Advisor basadas en los patrones de carga de trabajo para recomendar el rendimiento manual o de escalabilidad automática.
Ver la métrica de consumo normalizado de unidades de solicitud
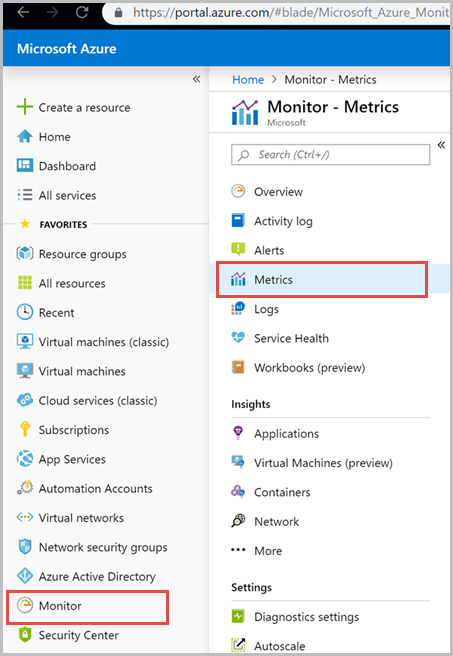
Inicie sesión en Azure Portal.
Seleccione Monitor en la barra de navegación izquierda y, a continuación, seleccione Métricas.
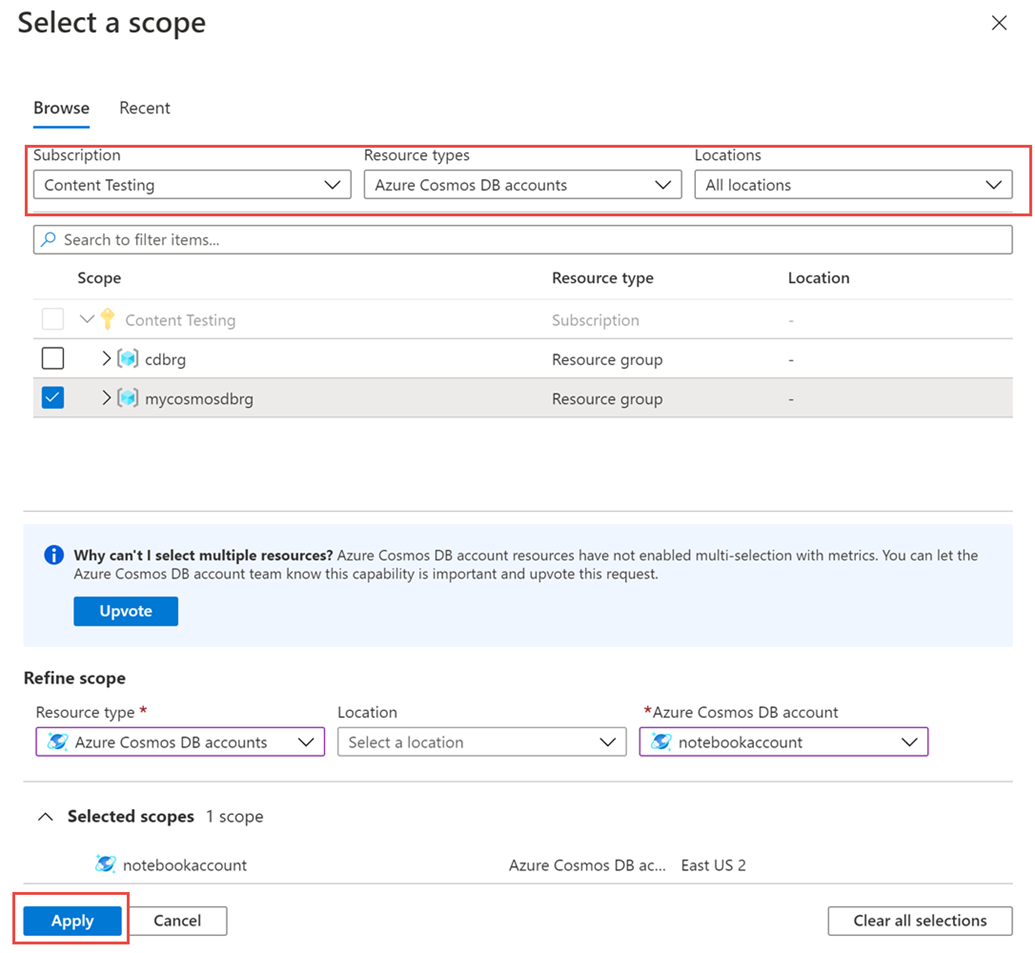
En el panel Métricas>Seleccionar un recurso> elija la suscripción, y el grupo de recursos requeridos. En Tipo de recurso, seleccione Cuentas de Azure Cosmos DB, elija una de las cuentas de Azure Cosmos DB existentes y seleccione Aplicar.
A continuación, puede seleccionar una métrica de la lista de métricas disponibles. Puede seleccionar métricas específicas de unidades de solicitud, almacenamiento, latencia, disponibilidad, Cassandra, etc. Para conocer los detalles de todas las métricas disponibles en esta lista, consulte el artículo Métricas por categoría. En este ejemplo, vamos a seleccionar la métrica de Consumo de RU normalizado y Max como valor de agregación.
Además de estos detalles, también puede seleccionar los valores de Intervalo de tiempo y Granularidad de tiempo de las métricas. Como máximo, puede ver las métricas de los últimos 30 días. Después de aplicar el filtro, se muestra un gráfico basado en dicho filtro.
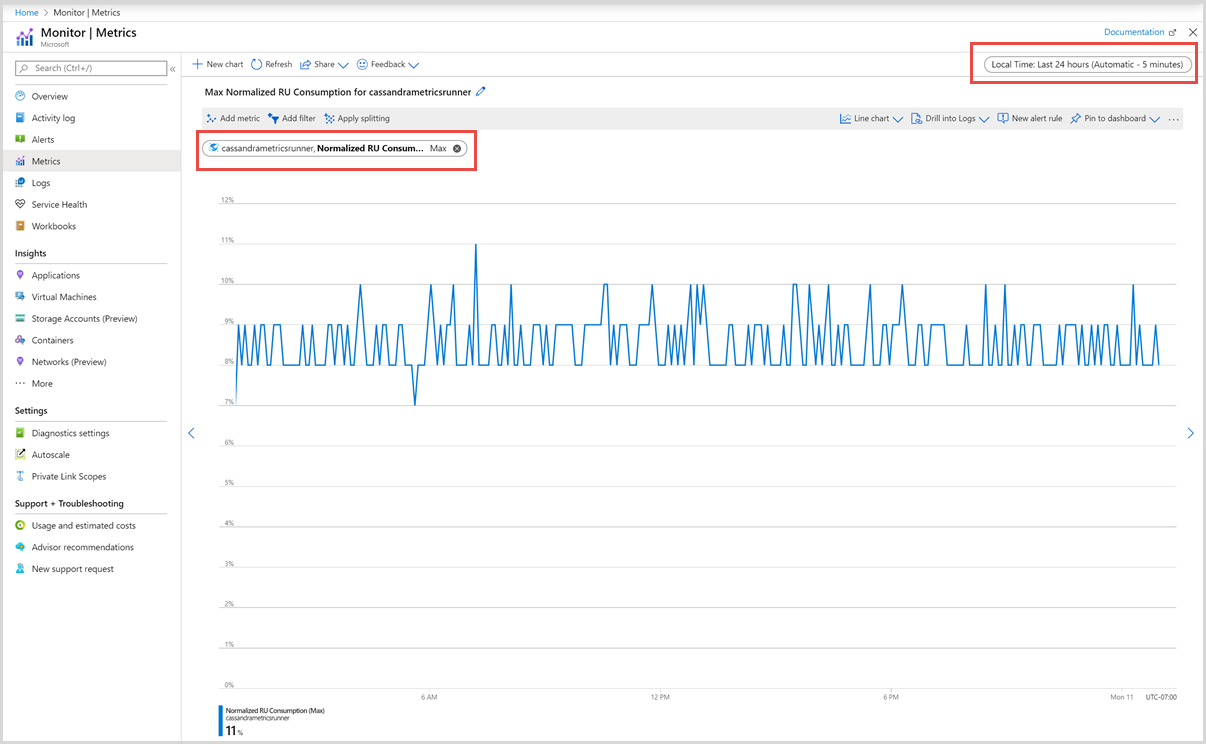
Filtros para la métrica de consumo de RU normalizada
También puede filtrar las métricas y el gráfico que se muestra por una propiedad CollectionName, DatabaseName, PartitionKeyRangeID y Region concreta. Para filtrar las métricas, seleccione Agregar filtro y elija la propiedad necesaria, como CollectionName y el valor correspondiente que le interese. A continuación, el gráfico muestra la métrica de consumo de RU normalizado utilizadas para el contenedor durante el período seleccionado.
Para agrupar las métricas puede usar la opción Apply splitting (Aplicar división). En el caso de las bases de datos de rendimiento compartidas, la métrica de RU normalizada solo muestra datos hasta el detalle de base de datos; no muestra ningún dato por recopilación. Por lo tanto, para la base de datos de rendimiento compartida, no verá ningún dato al aplicar la división por nombre de la colección.
La métrica de consumo normalizado de unidades de solicitud para cada contenedor aparece como se muestra en la siguiente imagen:

Pasos siguientes
- Supervise los datos de Azure Cosmos DB mediante la configuración de diagnóstico en Azure.
- Auditoría de las operaciones del plano de control de Azure Cosmos DB
- Diagnóstico y solución de problemas de las excepciones de tasa de solicitudes demasiado grande (429) en Azure Cosmos DB