Coubicación de tablas en Azure Cosmos DB for PostgreSQL
SE APLICA A: ![]() Azure Cosmos DB for PostgreSQL (con tecnología de la extensión de base de datos de Citus en PostgreSQL)
Azure Cosmos DB for PostgreSQL (con tecnología de la extensión de base de datos de Citus en PostgreSQL)
La coubicación significa almacenar junta la información relacionada, en los mismos nodos. Las consultas pueden ser rápidas cuando todos los datos necesarios están disponibles sin ningún tráfico de red. La coubicación de los datos relacionados en diferentes nodos permite que las consultas se ejecuten eficazmente en paralelo en cada nodo.
Coubicación de datos para tablas distribuidas mediante una función hash
En Azure Cosmos DB for PostgreSQL, se almacena una fila en una partición de base de datos si el hash del valor de la columna de distribución se encuentra dentro del intervalo de hash de la partición. Las particiones de base de datos con el mismo intervalo de hash siempre se colocan en el mismo nodo. Las filas con valores de columna de distribución iguales siempre se encuentran en el mismo nodo en las tablas. El concepto de tablas distribuidas por hash también se conoce como particionamiento basado en filas. En particionamiento basado en esquemas, las tablas dentro de un esquema distribuido siempre se colocan.

Un ejemplo práctico de coubicación
Considere las siguientes tablas que pueden formar parte de un análisis web multiinquilino SaaS:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Queremos responder a las consultas que se pueden emitir mediante un panel orientado al cliente. Una consulta podría ser "Devolver el número de visitas de la semana pasada para todas las páginas que empiezan por '/blog' en el inquilino seis".
Si los datos se encuentran en un servidor de PostgreSQL único, nuestra consulta podría expresarse fácilmente mediante el amplio conjunto de operaciones relacionales que SQL ofrece:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Siempre y cuando el espacio de trabajo para esta consulta se ajuste a la memoria, una tabla de servidor único es una solución adecuada. Consideremos las oportunidades de escalar el modelo de datos con Azure Cosmos DB for PostgreSQL.
Distribución de tablas por identificador
Las consultas de servidor único empiezan a ralentizarse a medida que crece el número de inquilinos y los datos almacenados para cada inquilino. El espacio de trabajo deja de ajustarse a la memoria y CPU se convierte en un cuello de botella.
En este caso, se pueden particionar los datos entre varios nodos mediante Azure Cosmos DB for PostgreSQL. La primera elección y la más importante que se debe tomar cuando se decide efectuar el particionamiento es la columna de distribución. Comencemos por la elección simple de usar event_id para la tabla de eventos y page_id para la tabla page:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Cuando los datos se dispersan entre distintos nodos de trabajo, no se puede realizar una combinación tal como se haría en un único nodo de PostgreSQL. En su lugar, necesitamos emitir dos consultas:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Después, la aplicación debe combinar los resultados de los dos pasos.
La ejecución de las consultas debe consultar los datos de particiones de base de datos repartidos entre los nodos.
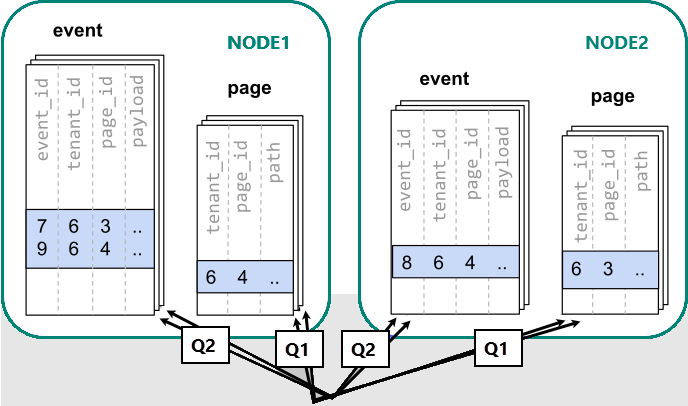
En este caso, la distribución de datos crea inconvenientes importantes:
- La sobrecarga que supone consultar cada partición de base de datos y ejecutar varias consultas.
- La sobrecarga debida a que Q1 devuelve muchas filas al cliente.
- Q2 aumenta.
- La necesidad de escribir consultas en varios pasos requiere cambios en la aplicación.
Dado que los datos están dispersos, las consultas se pueden ejecutar en paralelo. Esto solo supone una ventaja si la cantidad de trabajo que realiza la consulta es considerablemente mayor que la sobrecarga de consultar varias particiones de base de datos.
Distribución de tablas por inquilino
En Azure Cosmos DB for PostgreSQL, se garantiza que las filas con el mismo valor de columna de distribución van a estar en el mismo nodo. Si empezamos de nuevo, podemos crear nuestras tablas con tenant_id como columna de distribución.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Ahora Azure Cosmos DB for PostgreSQL puede responder la consulta de servidor único original sin ninguna modificación (P1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Debido al filtro y la combinación en tenant_id, Azure Cosmos DB for PostgreSQL sabe que toda la consulta se puede responder con el conjunto de particiones de base de datos coubicadas que contienen los datos para ese inquilino determinado. Un único nodo de PostgreSQL puede resolver la consulta en un solo paso.
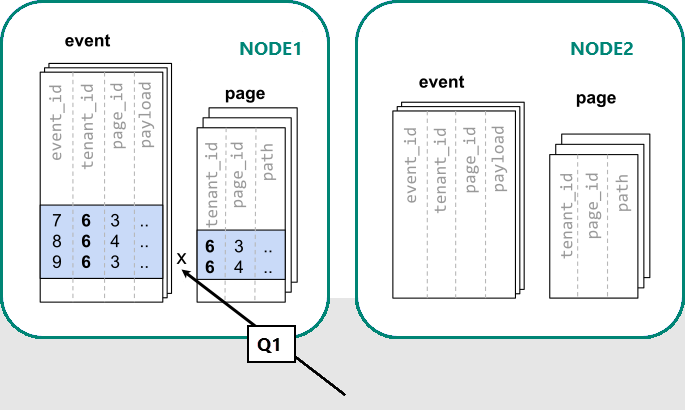
En algunos casos, las consultas y los esquemas de tabla deben cambiarse para incluir el id. de inquilino en las restricciones únicas y condiciones de combinación. Este cambio suele ser sencillo.
Pasos siguientes
- Consulte cómo se coubican los datos de inquilino en el tutorial de multiinquilino.