Características de optimización del rendimiento de la actividad de copia
SE APLICA A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Pruebe Data Factory en Microsoft Fabric, una solución de análisis todo en uno para empresas. Microsoft Fabric abarca todo, desde el movimiento de datos hasta la ciencia de datos, el análisis en tiempo real, la inteligencia empresarial y los informes. Obtenga información sobre cómo iniciar una nueva evaluación gratuita.
En este artículo se describen las características de optimización del rendimiento de la actividad de copia que puede usar en canalizaciones de Azure Data Factory y Azure Synapse Analytics.
Configuración de características de rendimiento con la interfaz de usuario
Al seleccionar un actividad de copia en el lienzo del editor de canalizaciones y elegir la pestaña Configuración en el área de configuración de actividad debajo del lienzo, verá opciones para configurar todas las características de rendimiento que se detallan a continuación.
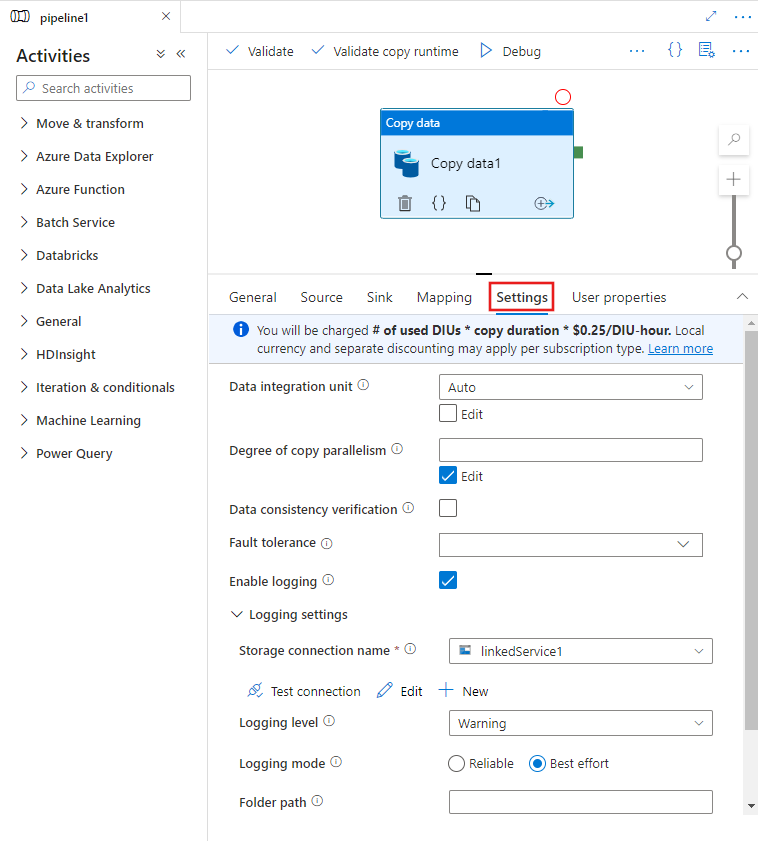
Unidades de integración de datos
Una unidad de integración de datos es una medida que representa la potencia (una combinación de CPU, memoria y asignación de recursos de red) de una única unidad en el servicio. Una unidad de integración de datos solo se aplica a Azure Integration Runtime, pero no a Integration Runtime autohospedado.
El número permitido de DIU para impulsar la ejecución de una actividad de copia se encuentra entre 4 y 256. Si no se especifica o elige "automático" en la interfaz de usuario, el servicio aplicará dinámicamente el valor óptimo de DIU según el par origen-receptor y el patrón de datos. En la tabla siguiente se enumeran los intervalos de unidades de integración de datos (DIU) admitidos y el comportamiento predeterminado en diferentes escenarios de copia:
| Escenario de copia | Intervalo de DIU admitido | DIU predeterminadas que determina el servicio |
|---|---|---|
| Entre almacenes de archivos | - Copiar desde o haci un único archivo: 4 - Copiar desde y a varios archivos: 4-256 dependiendo del número y tamaño de los archivos Por ejemplo, si copia datos de una carpeta con 4 archivos grandes y decide conservar la jerarquía, el número máximo efectivo de DIU es 16; si decide combinar archivos, el número máximo efectivo de DIU es 4. |
Entre 4 y 32, según el número y tamaño de los archivos |
| Del almacén de archivos a un almacén que no es de archivos | - Copiar desde un único archivo: 4 - Copiar desde varios archivos: 4-256 dependiendo del número y tamaño de los archivos Por ejemplo, si copia datos de una carpeta con 4 archivos grandes, el número máximo efectivo de DIU es 16. |
- Copia en Azure SQL Database o Azure Cosmos DB: entre 4 y 16, según el nivel de receptor (DTU o RU) y el patrón del archivo de origen - Copia en Azure Synapse Analytics mediante PolyBase o la instrucción COPY: 2 - Otro escenario: 4 |
| De un almacén que no es de archivos al almacén de archivos | - Copia desde almacenes de datos habilitados con la opción de partición (incluidos Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server y Teradata): entre 4 y 256 cuando se escribe en una carpeta, y entre 4 y 4 cuando se escribe en un solo archivo. Tenga en cuenta que se puede usar un máximo de 4 DIU por partición de datos de origen. - Otros escenarios: 4 |
- Copia desde REST o HTTP: 1 - Copia de Amazon Redshift utilizando UNLOAD: 4 - Otro escenario: 4 |
| Entre almacenes que no son de archivos | - Copia desde almacenes de datos habilitados con la opción de partición (incluidos Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server y Teradata): entre 4 y 256 cuando se escribe en una carpeta, y entre 4 y 4 cuando se escribe en un solo archivo. Tenga en cuenta que se puede usar un máximo de 4 DIU por partición de datos de origen. - Otros escenarios: 4 |
- Copia desde REST o HTTP: 1 - Otro escenario: 4 |
Puede ver el número de unidades de integración de datos utilizadas en cada ejecución de copia en la vista de supervisión o en la salida de la actividad de copia. Para más información, consulte el artículo Supervisión de la actividad de copia. Para reemplazar esta configuración predeterminada, especifique un valor en la propiedad dataIntegrationUnits de la manera siguiente. El número real de DIU que usa la operación de copia en tiempo de ejecución es igual o inferior al valor configurado, según el patrón de datos.
Se le cobrará el n.° de DIU usadas * la duración de la copia * el precio unitario/hora de DIU. Consulte aquí los precios actuales. La moneda local y el descuento independiente pueden aplicarse según el tipo de suscripción.
Ejemplo:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Escalabilidad del entorno de ejecución de integración autohospedado
Si quiere lograr una mayor capacidad de proceso, puede escalar vertical u horizontalmente el IR autohospedado:
- Si la memoria disponible y la CPU del nodo de IR autohospedado no se utilizan totalmente, pero la ejecución de trabajos simultáneos está alcanzando el límite, debe realizar un escalado vertical aumentando el número de trabajos simultáneos que se pueden ejecutar en un nodo. Consulte este enlace para obtener instrucciones.
- Si, por otro lado, la CPU tiene un uso elevado en el nodo de IR autohospedado o la memoria disponible es baja, puede agregar un nuevo nodo para ayudar a escalar horizontalmente la carga en varios nodos. Consulte este enlace para obtener instrucciones.
Tenga en cuenta que, en los escenarios siguientes, una sola ejecución de la actividad de copia puede aprovechar varios nodos de IR autohospedados:
- Copia de datos desde almacenes basados en archivos, en función del número y el tamaño de los archivos.
- Copia de datos desde almacenes de datos habilitados con la opción de partición (incluidos Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server y Teradata), en función del número de particiones de datos.
Copia en paralelo
Puede establecer la copia en paralelo (la propiedad parallelCopies en la definición JSON de la actividad de copia o el valor Degree of parallelism en la pestaña Configuración de las propiedades de actividad de copia de la interfaz de usuario) en la actividad de copia para indicar el paralelismo que desea que esta use. Esta propiedad se puede considerar como el número máximo de subprocesos dentro de la actividad de copia que se leen de los almacenes de datos de origen o se escriben en los almacenes de datos receptores en paralelo.
La copia en paralelo es ortogonal para unidades de integración de datos o nodos de IR autohospedado; es decir, se cuenta para todas las unidades de integración de datos o todos los nodos de IR autohospedado.
En cada ejecución de actividad de copia y de forma predeterminada, el servicio aplica dinámicamente el valor óptimo de copia en paralelo según el par origen-receptor y el patrón de datos.
Sugerencia
El comportamiento predeterminado de la copia en paralelo suele proporcionar el mejor rendimiento, que el servicio determina automáticamente en función del par origen-receptor, el patrón de datos y el número de unidades de integración de datos o el recuento de CPU/memoria/nodos del entorno de ejecución de integración autohospedado. Consulte Solución de problemas de rendimiento de la actividad de copia para conocer cuándo se debe ajustar la copia en paralelo.
En la tabla siguiente se muestra el comportamiento de la copia en paralelo:
| Escenario de copia | Comportamiento de la copia en paralelo |
|---|---|
| Entre almacenes de archivos | parallelCopies determina el paralelismo en el nivel de archivo. La fragmentación dentro de cada archivo se produce por debajo, de forma automática y transparente. Está diseñada con el objetivo de utilizar el tamaño de fragmento más adecuado para que un tipo de almacén de datos determinado cargue datos en paralelo. El número real de copias en paralelo que usa la actividad de copia en tiempo de ejecución no es superior al número de archivos que se tiene. Si el comportamiento de copia tiene el valor mergeFile para combinar el archivo en un receptor, la actividad de copia no puede aprovechar las ventajas del paralelismo en el nivel de archivo. |
| Del almacén de archivos a un almacén que no es de archivos | - Cuando se copian datos en Azure SQL Database o Azure Cosmos DB, la copia en paralelo predeterminada también depende del nivel de receptor (número de DTU/RU). - Cuando se copian datos en Azure Table, la copia en paralelo predeterminada es 4. |
| De un almacén que no es de archivos al almacén de archivos | - Cuando se copian datos desde almacenes de datos habilitados con la opción de partición (incluidos Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server y Teradata), la copia en paralelo predeterminada es 4. El número real de copias en paralelo que usa la actividad de copia en tiempo de ejecución no es superior al número de particiones de datos que se tiene. Si usa el entorno de ejecución de integración autohospedado y copia en Azure Blob/ADLS Gen2, tenga en cuenta que la copia en paralelo máxima efectiva es 4 o 5 por nodo de IR. - En otros escenarios, la copia en paralelo no surte efecto. Aunque se especifique el paralelismo, no se aplica. |
| Entre almacenes que no son de archivos | - Cuando se copian datos en Azure SQL Database o Azure Cosmos DB, la copia en paralelo predeterminada también depende del nivel de receptor (número de DTU/RU). - Cuando se copian datos desde almacenes de datos habilitados con la opción de partición (incluidos Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS for Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS for SQL Server y Teradata), la copia en paralelo predeterminada es 4. - Cuando se copian datos en Azure Table, la copia en paralelo predeterminada es 4. |
Para controlar la carga en las máquinas que hospedan los almacenes de datos o para ajustar el rendimiento de la copia, puede reemplazar el valor predeterminado y especificar un valor para la propiedad parallelCopies. El valor debe ser un entero mayor o igual que 1. En tiempo de ejecución, y para obtener el mejor rendimiento, la actividad de copia usa un valor inferior o igual al valor que ha establecido.
Cuando especifique un valor para la propiedad parallelCopies, tenga en cuenta el aumento de la carga en los almacenes de datos de origen y receptor. Tenga también en cuenta el aumento de carga en el entorno de ejecución de integración autohospedado si la actividad de copia está capacitada para él. Dicho aumento sucede especialmente si tiene varias actividades o ejecuciones simultáneas de las mismas actividades que se ejecutan en el mismo almacén de datos. Si observa que el almacén de datos o el entorno de ejecución de integración autohospedado están sobrecargados, disminuya el valor de parallelCopies para aliviar la carga.
Ejemplo:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
copia almacenada provisionalmente
Al copiar datos de un almacén de datos de origen a un almacén de datos receptor, podría elegir usar Azure Blob Storage o Azure Data Lake Storage Gen2 como almacenamiento provisional. El almacenamiento provisional es especialmente útil en los siguientes casos:
- Quiere ingerir datos de varios almacenes de datos en Azure Synapse Analytics a través de PolyBase, copiar datos con Snowflake como origen y destino o introducir datos desde Amazon Redshift/HDFS de manera eficaz. Obtenga más información sobre lo siguiente:
- Solo desea abrir los puertos 80 y el 443 en el firewall, a causa de las directivas de TI corporativas. Por ejemplo, al copiar datos de un almacén de datos local a Azure SQL Database o a una instancia de Azure Synapse Analytics, debe activar la comunicación TCP saliente en el puerto 1433 tanto para el firewall de Windows como para el firewall corporativo. En este escenario, la copia almacenada provisionalmente usa el entorno de ejecución de integración autohospedado para copiar primero los datos en un almacenamiento provisional a través de HTTP o HTTPS en el puerto 443 y, luego, cargar los datos desde el almacenamiento provisional en SQL Database o Azure Synapse Analytics. En este flujo, no es necesario habilitar el puerto 1433.
- En ocasiones, se tarda un tiempo en realizar un movimiento de datos híbridos (es decir, copiar desde un almacén de datos local a un almacén de datos en la nube) a través de una conexión de red lenta. Para mejorar el rendimiento se puede usar una copia almacenada provisionalmente para comprimir los datos de forma local, con el fin de que se tarde menos tiempo en mover datos al almacén de datos provisional en la nube. Luego, puede descomprimir los datos en dicho almacén antes de cargarlos en el almacén de datos de destino.
Funcionamiento de las copias almacenadas provisionalmente
Al activar la característica de almacenamiento provisional, primero se copian los datos desde el almacén de datos de origen al almacenamiento provisional (aporte su propio Azure Blob o Azure Data Lake Storage Gen2). A continuación, los datos se copian desde el almacén de datos provisional al almacén de datos receptor. La actividad de copia administra automáticamente el flujo de dos fases y también borra los datos temporales del almacenamiento provisional una vez completado el movimiento de datos.

Necesita conceder permisos de eliminación a su Azure Data Factory en su almacenamiento provisional para que los datos temporales puedan eliminarse tras las ejecuciones de actividad de copia.
Cuando activa el movimiento de datos mediante un almacén provisional, puede especificar si quiere que los datos se compriman antes de moverlos del almacén de datos de origen al almacenamiento provisional y luego se descompriman antes de moverlos desde este último al almacén de datos receptor.
Actualmente, no es posible copiar datos entre dos almacenes de datos que estén conectados a través de distintos IR autohospedados, ni con copia almacenada provisionalmente ni sin ella. Para dicho escenario, puede configurar dos actividades de copia explícitamente encadenadas, con el fin de copiar desde el origen al almacenamiento provisional y, después, desde este al receptor.
Configuración
Configure el valor enableStaging de la actividad de copia para especificar si desea que los datos se almacenen provisionalmente antes de cargarlos en un almacén de datos de destino. Cuando establezca enableStaging en TRUE, especifique las propiedades adicionales que se muestran en la tabla siguiente.
| Propiedad | Descripción | Valor predeterminado | Obligatorio |
|---|---|---|---|
| enableStaging | Especifique si desea copiar los datos a través de un almacén provisional. | False | No |
| linkedServiceName | Especifique el nombre de un servicio vinculado Azure Blob Storage o Azure Data Lake Storage Gen2 que haga referencia a la instancia de almacenamiento que se usa como almacenamiento provisional. | N/D | Sí, cuando el valor de enableStaging está establecido en True. |
| path | Especifique la ruta de acceso que quiere que contenga los datos almacenados provisionalmente. Si no se proporciona una ruta de acceso, el servicio crea un contenedor para almacenar los datos temporales. | N/D | No (Sí, cuando se especifica storageIntegration en el conector Snowflake) |
| enableCompression | Especifica si se deben comprimir los datos antes de copiarlos en el destino. Esta configuración reduce el volumen de datos que se va a transferir. | False | No |
Nota
Si usa una copia almacenada provisionalmente con la compresión habilitada, no se admite la autenticación de MSI o de la entidad de servicio para el almacenamiento provisional de un servicio vinculado de blob.
Este es un ejemplo de definición de una actividad de copia con las propiedades que se han descrito en la tabla anterior:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Impacto en la facturación de copia almacenada provisionalmente
Los cargos que se le realizan se basan en dos pasos: duración de la copia y tipo de copia.
- Cuando use el almacenamiento provisional durante una copia en la nube, que copia de datos de un almacén de datos en la nube a otro, donde ambos almacenamientos provisionales usan Azure Integration Runtime, se le cobrará de la siguiente manera: [suma de la duración de la copia de los pasos 1 y 2] x [precio unitario de la copia en la nube].
- Cuando use el almacenamiento provisional durante una copia híbrida, que copia de datos de un almacén de datos local a uno en la nube, un almacenamiento provisional que usa Integration Runtime autohospedado, se le cobrará de la siguiente manera: [duración de la copia híbrida] x [precio unitario de la copia híbrida] + [duración de la copia de nube] x [precio unitario de la copia de nube].
Contenido relacionado
Consulte los restantes artículos acerca de la actividad de copia:
- Información general de la actividad de copia
- Guía de escalabilidad y rendimiento de la actividad de copia
- Solución de problemas de rendimiento de la actividad de copia
- Uso de Azure Data Factory para migrar datos del lago de datos y el almacenamiento de datos a Azure
- Migración de datos de AWS S3 a Azure Storage