Arquitecturas de referencia de Lakehouse (descarga)
En este artículo se tratan las instrucciones arquitectónicas de lakehouse en términos de origen de datos, ingesta, transformación, consulta y procesamiento, servicio, análisis y almacenamiento.
Cada arquitectura de referencia tiene un PDF descargable en formato 11 x 17 (A3).
Aunque el almacén de lago de datos en Databricks es una plataforma abierta que se integra con un gran ecosistema de herramientas de partners, las arquitecturas de referencia solo se centran en los servicios de Azure y en la instancia del almacén de lago de datos de Databricks. Los servicios de proveedor de nube que se muestran están seleccionados para ilustrar los conceptos y no son exhaustivos.
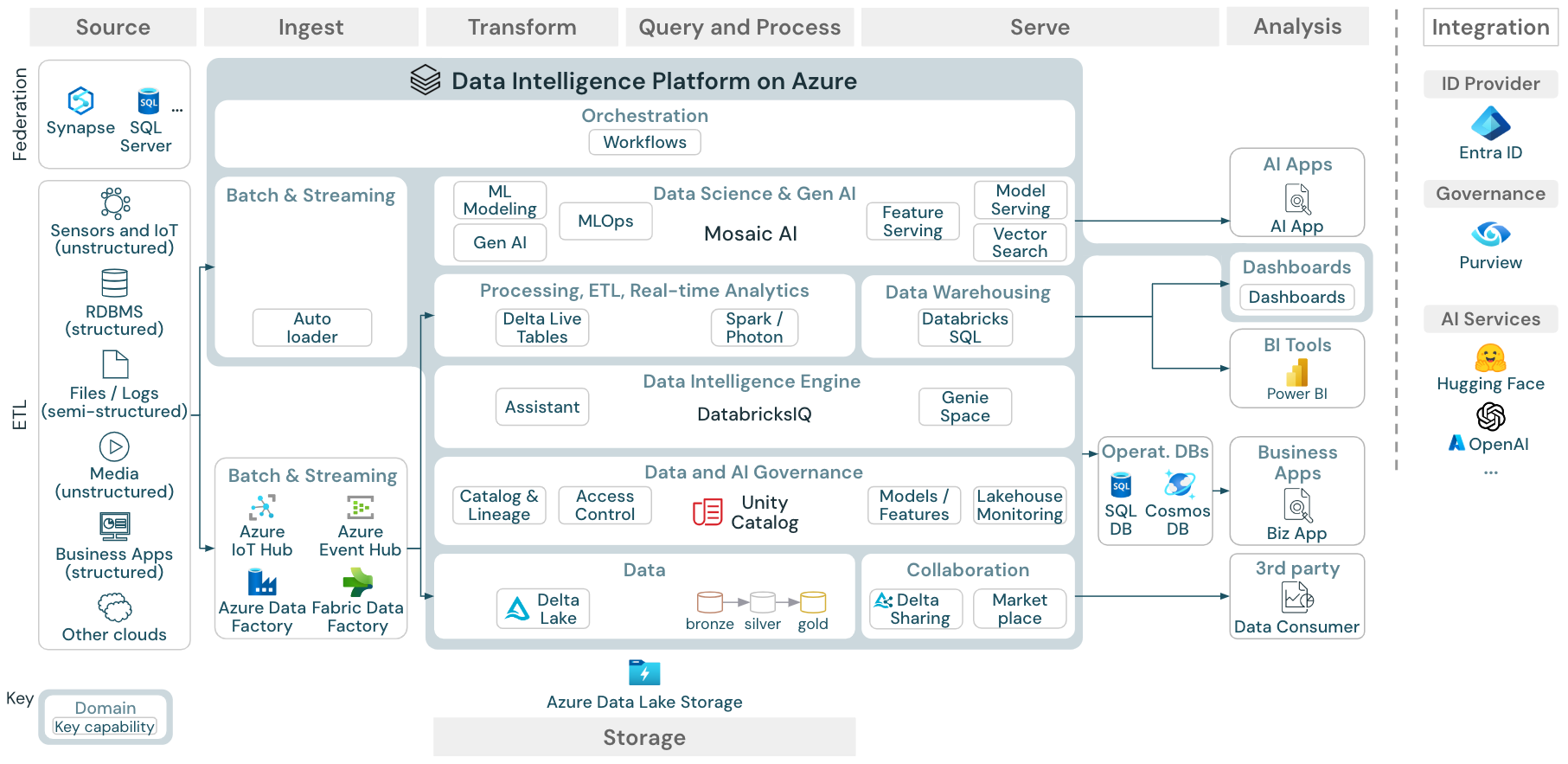
Descargar: arquitectura de referencia para el almacén de lago de datos de Azure Databricks
La arquitectura de referencia de Azure muestra los siguientes servicios específicos de Azure para la ingesta, almacenamiento, servicio y análisis:
- Azure Synapse y SQL Server como sistemas de origen para la federación de almacenes de lago
- Azure IoT Hub y Azure Event Hubs para la ingesta en streaming
- Azure Data Factory para la ingesta por lotes
- Azure Data Lake Storage Gen2 (ADLS) como almacenamiento de objetos
- Azure SQL DB y Azure Cosmos DB como bases de datos operativas
- Azure Purview como catálogo empresarial al que UC exporta información de esquema y linaje
- Power BI como herramienta de BI
Organización de las arquitecturas de referencia
La arquitectura de referencia se estructura a lo largo de las líneas de flujo origen, ingesta, transformación, consulta/proceso, servicio, análisisy almacenamiento:
Origen
La arquitectura distingue entre datos semiestructurados y no estructurados (sensores e IoT, medios, archivos y registros) y datos estructurados (RDBMS, aplicaciones empresariales). Los orígenes SQL (RDBMS) también se pueden integrar en el almacén de lago y en el catálogo de Unity a través de la federación de almacenes de lago. Además, es posible que los datos se carguen desde otros proveedores de nube.
Ingesta
Los datos se pueden ingerir en el almacén de lago mediante lotes o en streaming:
- Databricks LakeFlow Connect, que ofrece conectores integrados para la ingesta de bases de datos y aplicaciones empresariales. La canalización de ingesta resultante se rige por Unity Catalog y cuenta con tecnología de proceso sin servidor y Delta Live Tables.
- Los archivos entregados al almacenamiento en la nube se pueden cargar directamente mediante el Cargador automático de Databricks.
- Para la ingesta por lotes de datos de aplicaciones empresariales en Delta Lake, el almacén de lago de Databricks se basa en herramientas de ingesta de asociados con adaptadores específicos para estos sistemas de registro.
- Los eventos de streaming se pueden ingerir directamente desde sistemas de streaming de eventos como Kafka mediante el flujo estructurado de Databricks Structured Streaming. Los orígenes de streaming pueden ser sensores, IoT o procesos de captura de datos modificados.
Storage
Los datos se almacenan normalmente en el sistema de almacenamiento en la nube, donde las canalizaciones de ETL usan la arquitectura de medallón para almacenar datos de forma mantenida como archivos o tablas Delta.
Transformación y Consulta/Proceso
El almacén de lago de Databricks usa sus motores Apache Spark y Photon para todas las transformaciones y consultas.
DLT (Delta Live Tables) es un marco declarativo para simplificar y optimizar canalizaciones de procesamiento de datos confiables, fáciles de mantener y probar.
Con tecnología de Apache Spark y Photon, la plataforma Data Intelligence de Databricks admite ambos tipos de cargas de trabajo: consultas SQL a través de almacenes SQL y cargas de trabajo SQL, Python y Scala mediante clústeres de área de trabajo.
En el caso de la ciencia de datos (modelado de ML y Gen AI), la plataforma de IA y Machine Learning Databricks proporciona entornos de ejecución de ML especializados para AutoML y para codificar trabajos de ML. Todos los flujos de trabajo de ciencia de datos y MLOps tienen una mejor compatibilidad con MLflow.
Sirviendo
Para los casos de uso de DWH y BI, el almacén de lago de Databricks proporciona Databricks SQL, el almacenamiento de datos con tecnología de almacenes SQL y almacenes SQL sin servidor.
Para el aprendizaje automático, el servicio de modelos es una funcionalidad de servicio de modelos escalable, en tiempo real y de nivel empresarial hospedada en el plano de control de Databricks. Mosaic AI Gateway es una solución de Databricks para gobernar y supervisar el acceso a los modelos de IA generativos compatibles y a sus puntos de acceso de servicio de modelos asociados.
Bases de datos operativas: se pueden usar sistemas externos, como bases de datos operativas, para almacenar y entregar productos de datos finales a las aplicaciones de usuario.
Colaboración: los asociados empresariales obtienen acceso seguro a los datos que necesitan a través de Delta Sharing. Basado en Delta Sharing, Databricks Marketplace es un foro abierto para intercambiar productos de datos.
Análisis
Las aplicaciones empresariales finales están en esta línea. Entre los ejemplos se incluyen clientes personalizados, como las aplicaciones de inteligencia artificial conectadas al Servicio de modelos de Mosaic AI para la inferencia en tiempo real o las aplicaciones que acceden a los datos insertados desde el almacén de lago a una base de datos operativa.
En los casos de uso de BI, los analistas suelen usar herramientas de BI para acceder al almacenamiento de datos. Los desarrolladores de SQL también pueden usar el editor SQL de Databricks (no se muestra en el diagrama) para consultas y paneles.
La plataforma Data Intelligence también ofrece paneles para crear visualizaciones de datos y compartir información.
Integración
La plataforma Databricks se integra con proveedores de identidades estándar para la administración de usuarios y el inicio de sesión único (SSO).
Los servicios de inteligencia artificial externos, como OpenAI, LangChain o HuggingFace se pueden usar directamente desde la plataforma de inteligencia de Databricks.
Los orquestadores externos pueden usar la API de REST completa o conectores dedicados a herramientas de orquestación externas, como Apache Airflow.
Unity Catalog se usa para toda la gobernanza de datos e inteligencia artificial en la plataforma de inteligencia de Databricks y puede integrar otras bases de datos en su gobernanza a través de Lakehouse Federation.
Además, el catálogo de Unity se puede integrar en otros catálogos empresariales, por ejemplo, Purview. Póngase en contacto con el proveedor del catálogo de empresa para obtener más información.
Funcionalidades comunes para todas las cargas de trabajo
Además, el almacén de lago de Databricks incluye funcionalidades de administración que admiten todas las cargas de trabajo:
Gobernanza de datos e inteligencia artificial
El sistema central de gobernanza de datos e inteligencia artificial en la plataforma Data Intelligence de Databricks es el catálogo de Unity. El catálogo de Unity proporciona un único lugar para administrar directivas de acceso a datos que se aplican en todas las áreas de trabajo y admite todos los recursos creados o usados en el almacén de lago, como tablas, volúmenes, características (almacén de características) y modelos (registro de modelos). También se puede usar el catálogo de Unity para capturar el linaje de datos en tiempo de ejecución entre las consultas que se ejecutan en Databricks.
La supervisión del almacén de lago de Databricks permite supervisar la calidad de los datos en todas las tablas de una cuenta. También puede realizar un seguimiento del rendimiento de modelos de aprendizaje automático y puntos de conexión de servicio de modelos.
Para la observabilidad, las tablas del sistema son un almacén analítico alojado en Azure Databricks de los datos operativos de una cuenta. Las tablas del sistema se pueden usar para la observabilidad histórica en toda la cuenta.
Motor de inteligencia de datos
La plataforma Data Intelligence de Databricks permite que toda la organización use datos e inteligencia artificial. Con tecnología de DatabricksIQ, combina inteligencia artificial generativa con las ventajas de unificación de un almacén de lago para comprender la semántica única de los datos.
Databricks Assistant está disponible para los desarrolladores en los cuadernos, el editor SQL y el editor de archivos de Databricks como asistente de inteligencia artificial basado en el contexto.
Automatización & Orquestación
Los trabajos de Databricks orquestan el procesamiento de datos, el aprendizaje automático y las canalizaciones de análisis en Databricks Data Intelligence Platform. Delta Live Tables permite crear canalizaciones de ETL confiables y fáciles de mantener con sintaxis declarativa. La plataforma también admite CI/CD y MLOps
Casos de uso de alto nivel para la Plataforma de inteligencia de datos en Azure
Databricks LakeFlow Connect ofrece conectores integrados para la ingesta de aplicaciones y bases de datos empresariales. La canalización de ingesta resultante se rige por Unity Catalog y cuenta con tecnología de proceso sin servidor y Delta Live Tables. LakeFlow Connect aprovecha las lecturas y escrituras incrementales eficaces para que la ingesta de datos sea más rápida, escalable y rentable, mientras que los datos permanecen frescos para el consumo de bajada.
Caso de uso: Ingesta con Lakeflow Connect:
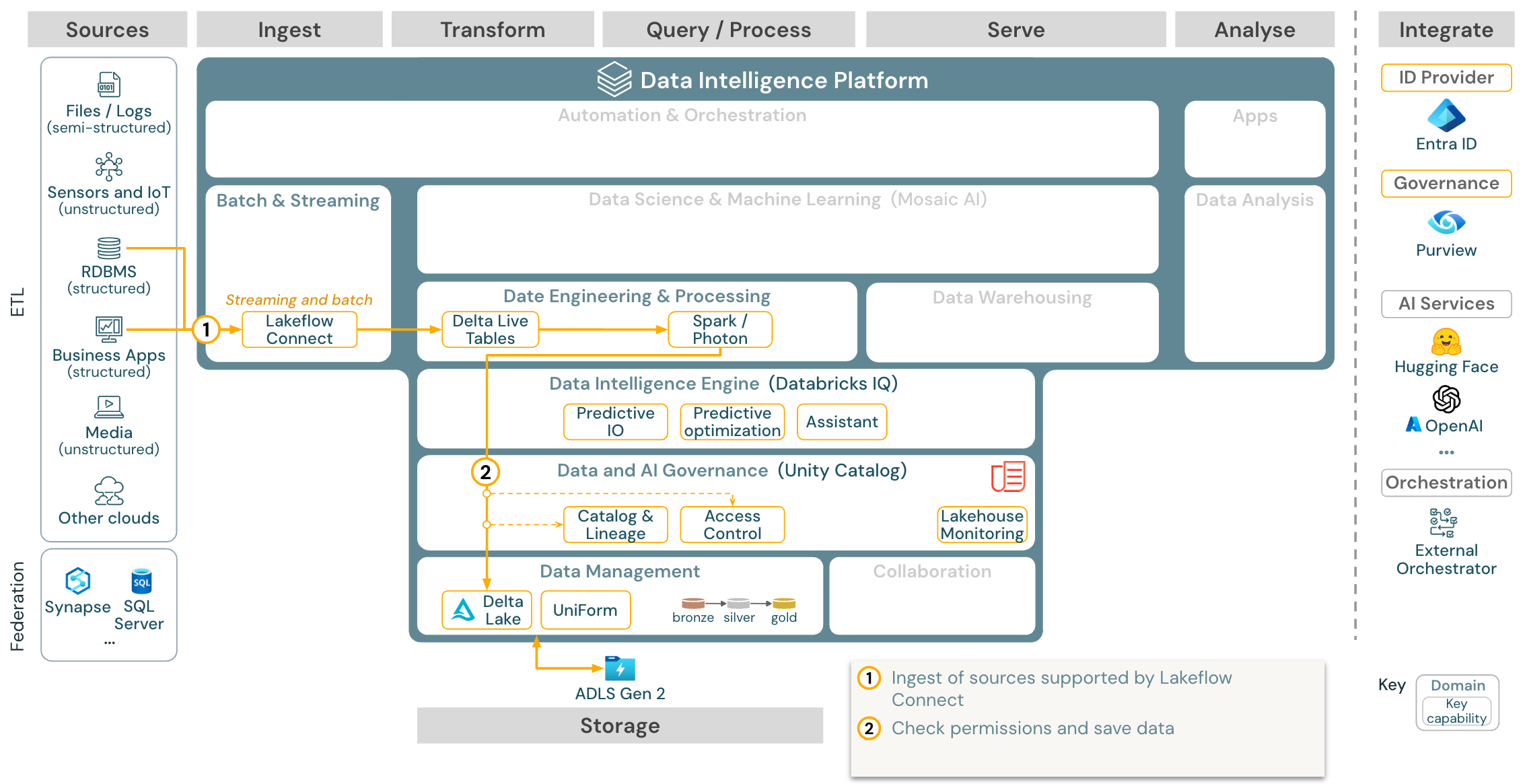
Descargar: arquitectura de referencia de Batch ETL para Azure Databricks.
Caso de uso: ETL por lotes

Descargar: arquitectura de referencia de ETL por lotes para Azure Databricks
Las herramientas de ingesta usan adaptadores específicos del origen para leer datos del origen y, a continuación, almacenarlos en el almacenamiento en la nube desde donde el cargador automático puede leerlos o llamar directamente a Databricks (por ejemplo, con herramientas de ingesta de asociados integradas en el almacén de lago de Databricks). Para cargar los datos, el motor de procesamiento y ETL de Databricks, a través de DLT, ejecuta las consultas. Los trabajos de Databricks pueden organizar flujos de trabajos únicos o de varias tareas y regirlos por el catálogo de Unity (control de acceso, auditoría, linaje, etc.). Si los sistemas operativos de baja latencia requieren acceso a tablas "golden" específicas, se pueden exportar a una base de datos operativa, como un almacén de clave-valor o RDBMS al final de la canalización de ETL.
Caso de uso: streaming y captura de datos modificados (CDC)
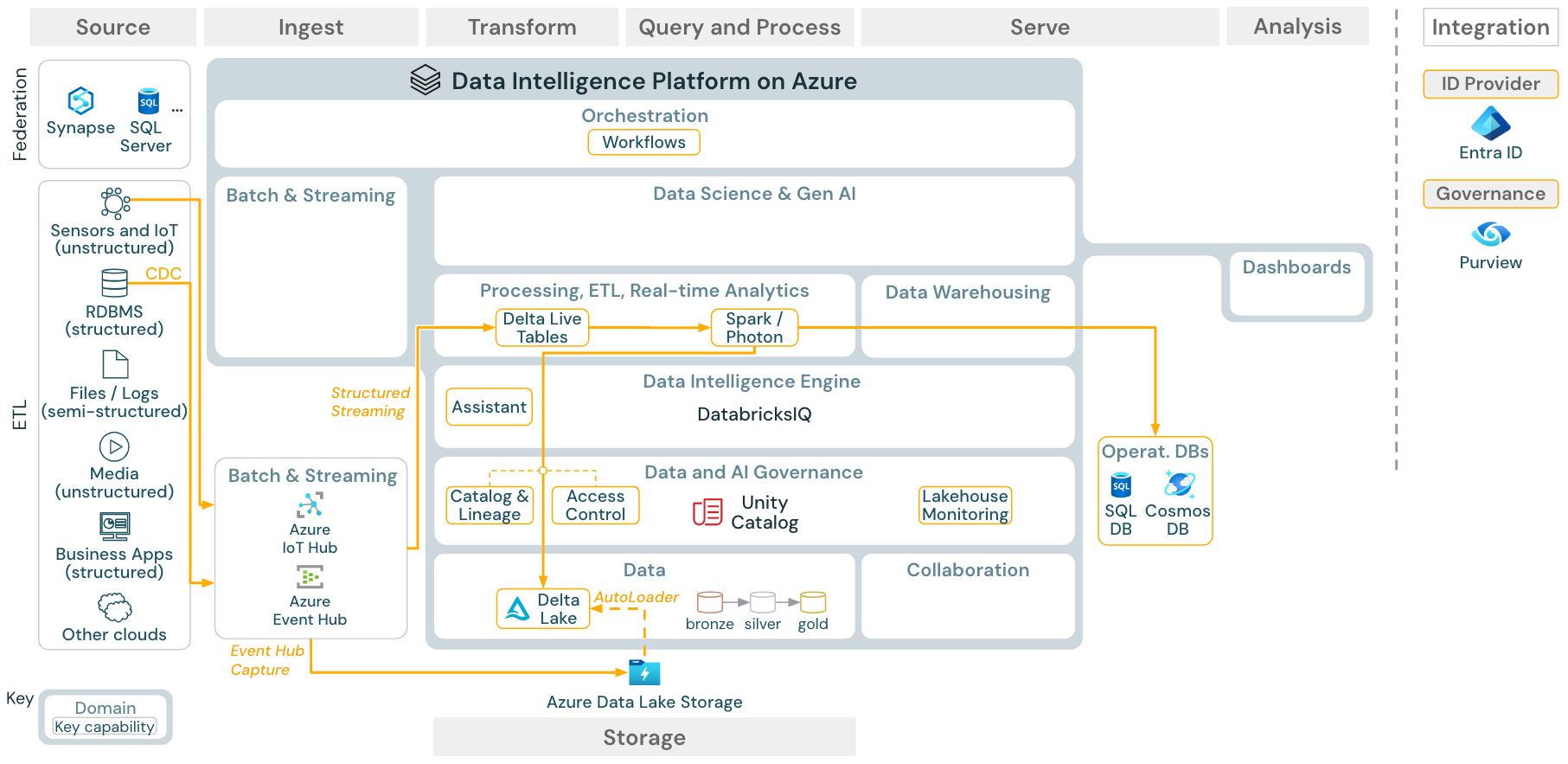
Descargar: arquitectura de streaming estructurado de Spark para Azure Databricks
El motor de ETL de Databricks usa Spark Structured Streaming para leer desde colas de eventos como Apache Kafka o Azure Event Hub. Los pasos descendentes siguen el enfoque del caso de uso por lotes anterior.
Normalmente, la captura de datos modificados en tiempo real (CDC) usa una cola de eventos para almacenar los eventos extraídos. Desde allí, el caso de uso sigue el caso de uso de streaming.
Si CDC se realiza por lotes donde los registros extraídos se almacenan primero en el almacenamiento en la nube, el cargador automático de Databricks puede leerlos y el caso de uso sigue el proceso de ETL por lotes.
Caso de uso: aprendizaje automático e inteligencia artificial
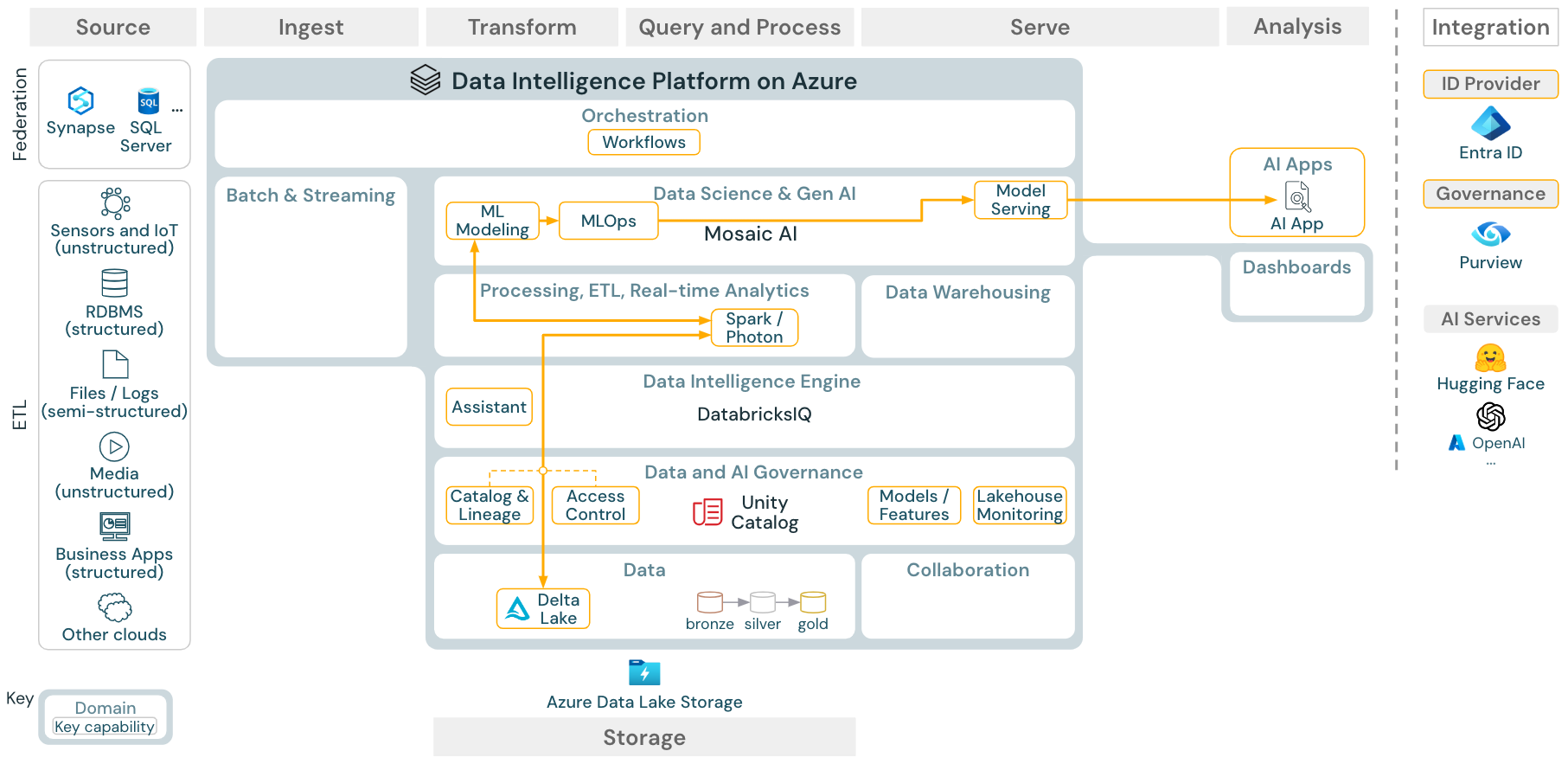
Descargar: arquitectura de referencia de aprendizaje automático e IA para Azure Databricks
Para el aprendizaje automático, la plataforma Data Intelligence de Databricks proporciona Mosaic AI, que incluye bibliotecas de aprendizaje profundo y máquinas de última generación. Proporciona funcionalidades como el almacén de características y el registro de modelos (ambos integrados en el catálogo de Unity), características de poco código con AutoML y la integración de MLflow en el ciclo de vida de la ciencia de datos.
Todos los recursos relacionados con la ciencia de datos (tablas, características y modelos) se rigen por el catálogo de Unity y los científicos de datos pueden usar trabajos de Databricks para organizar sus trabajos.
Para implementar modelos de una forma escalable y de nivel empresarial, use las funcionalidades de MLOps para publicar los modelos en el servicio de modelos.
Caso de uso: aplicaciones de agente de inteligencia artificial generativa (Gen AI)

Descargar: arquitectura de referencia de aplicaciones de Gen AI para Azure Databricks
Para los casos de uso de IA generativa, Mosaic AI incluye bibliotecas de última generación y funcionalidades específicas de Gen AI, desde la ingeniería rápida hasta el ajuste preciso de los modelos existentes y el entrenamiento previo desde cero. La arquitectura anterior muestra un ejemplo de cómo se puede integrar la búsqueda vectorial para crear una aplicación de inteligencia artificial generativa usando RAG (generación aumentada por recuperación).
Para implementar modelos de una forma escalable y de nivel empresarial, use las funcionalidades de MLOps para publicar los modelos en el servicio de modelos.
Caso de uso: BI y análisis SQL
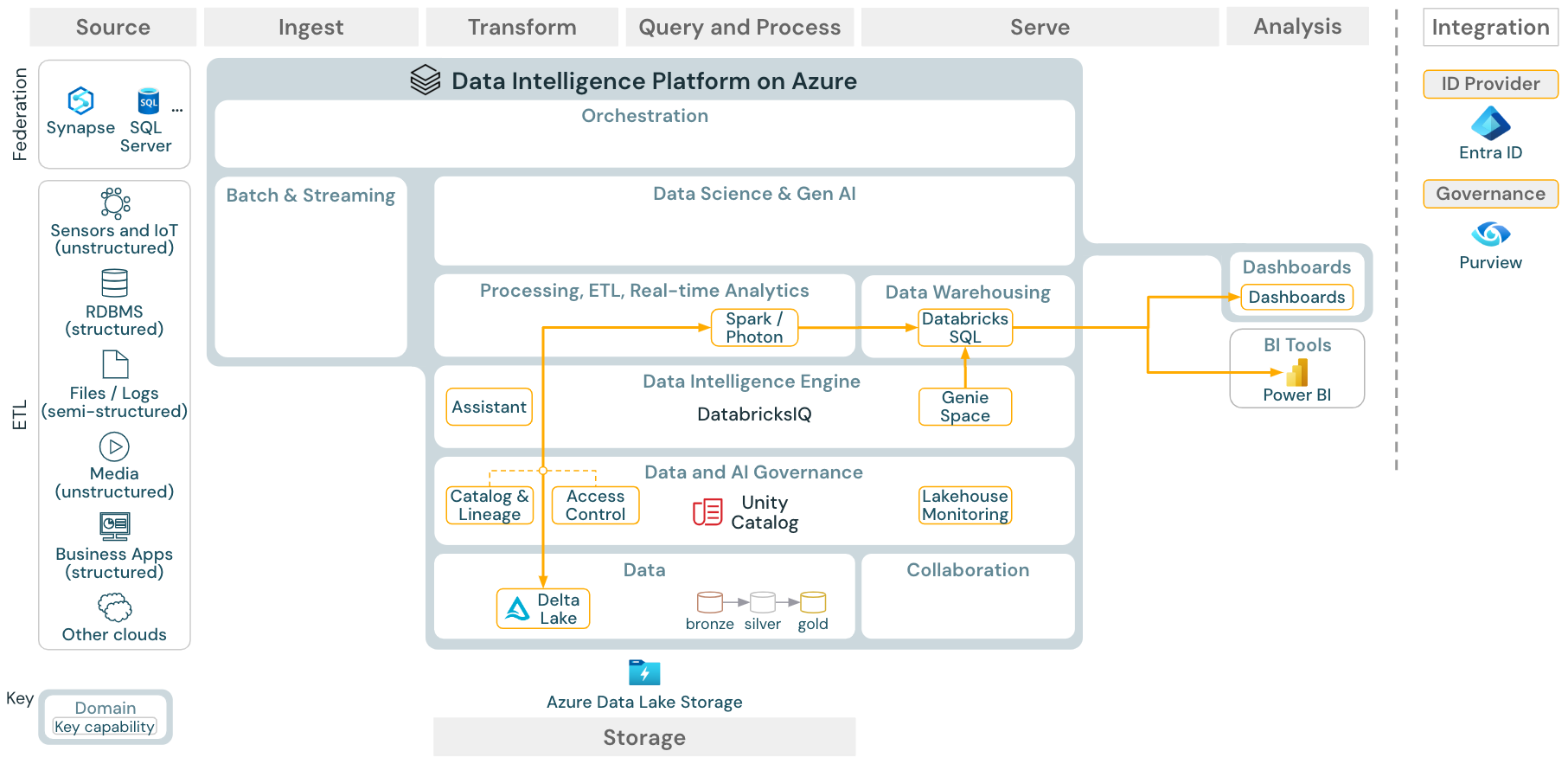
Descargar: arquitectura de referencia de BI y análisis SQL para Azure Databricks
Para los casos de uso de BI, los analistas de negocios pueden usar paneles, el editor SQL de Databricks o herramientas de BI específicas, como Tableau o Power BI. En todos los casos, el motor es Databricks SQL (sin servidor o que no sea sin servidor) y el catálogo de Unity proporciona detección, exploración y control de acceso.
Caso de uso: Federación de almacenes de lago
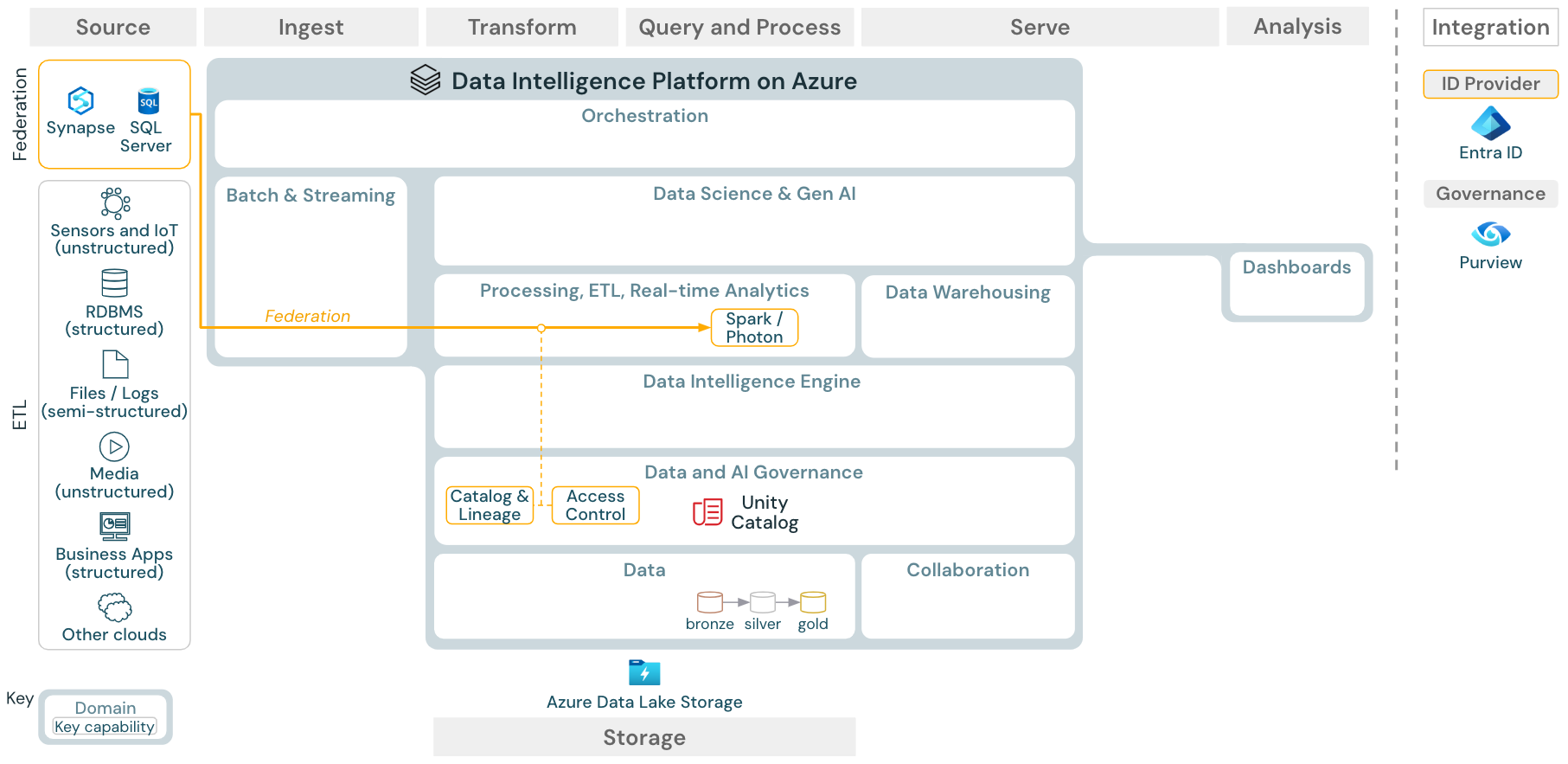
Descargar: arquitectura de referencia de federación de almacenes de lago para Azure Databricks
La federación de almacenes de lago permite integrar bases de datos SQL externas (como MySQL, Postgres, SQL Server o Azure Synapse) con Databricks.
Todas las cargas de trabajo (AI, DWH y BI) pueden beneficiarse de esto sin necesidad de realizar primero ETL en los datos en el almacenamiento de objetos. El catálogo de origen externo se asigna al catálogo de Unity y se puede aplicar un control de acceso específico para el acceso a través de la plataforma de Databricks.
Caso de uso: Uso compartido de datos empresariales
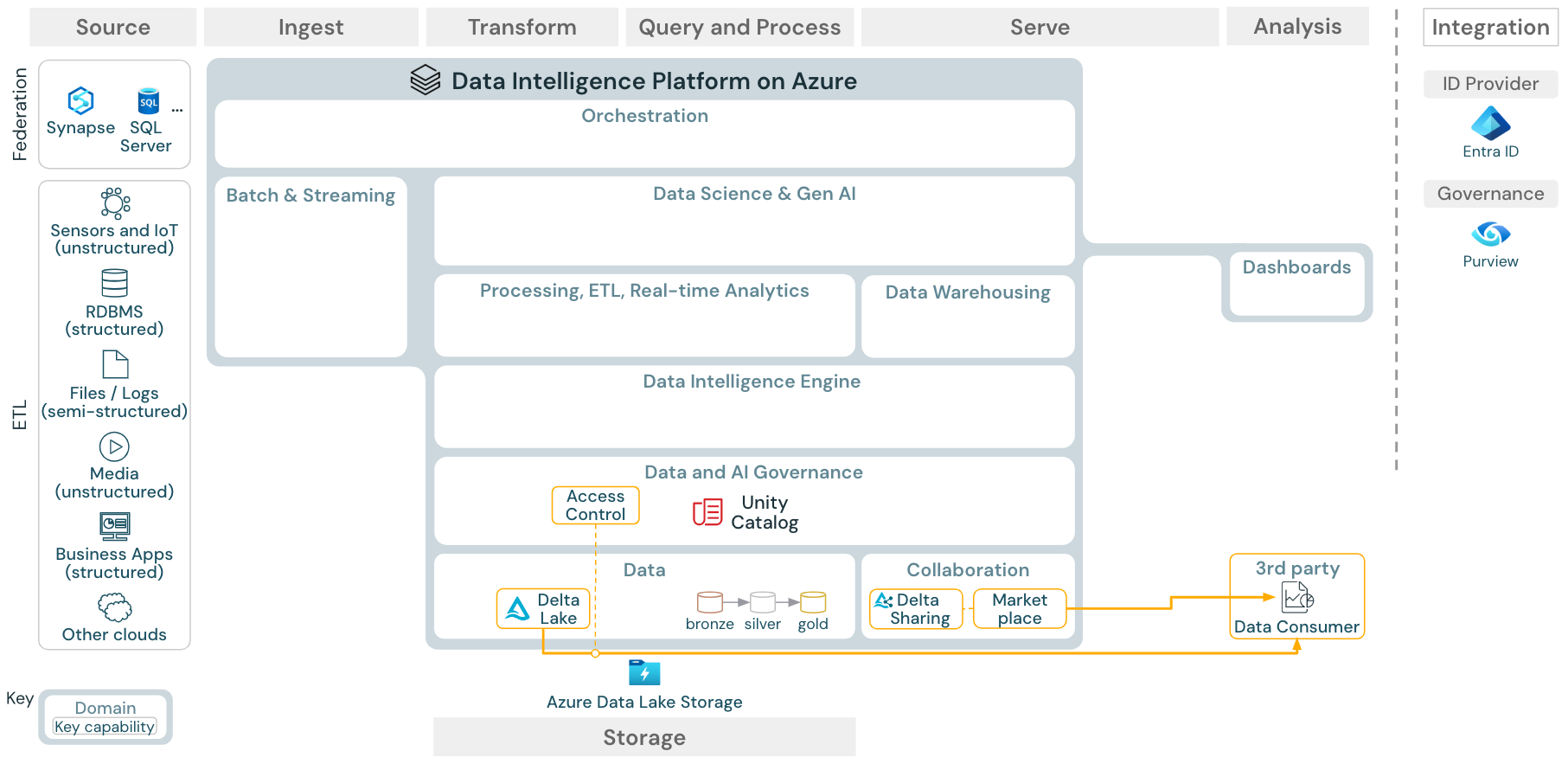
Descargar: arquitectura de referencia de uso compartido de datos empresariales para Azure Databricks
Delta Sharing proporciona el uso compartido de datos de nivel empresarial. Proporciona acceso directo a los datos del almacén de objetos protegidos por el catálogo de Unity, y Databricks Marketplace es un foro abierto para intercambiar productos de datos.