Creación de una ejecución de entrenamiento mediante foundation Model Fine-tuning API
Importante
Esta característica se encuentra en versión preliminar pública en las siguientes regiones: centralus, eastus, eastus2, northcentralus y westus.
En este artículo se describe cómo crear y configurar una ejecución de entrenamiento mediante foundation Model Fine-tuning (ahora parte de Mosaic AI Model Training) API y se describen todos los parámetros usados en la llamada API. También puede crear una ejecución mediante la interfaz de usuario. Para obtener instrucciones, consulte Creación de una ejecución de entrenamiento mediante la interfaz de usuario de ajuste preciso de Foundation Model.
Requisitos
Vea Requisitos.
Creación de una ejecución de entrenamiento
Para crear ejecuciones de entrenamiento mediante programación, use la función create(). Esta función entrena un modelo en el conjunto de datos proporcionado y convierte el punto de control final de Composer en un punto de control con formato de Hugging Face para la inferencia.
Las entradas necesarias son el modelo que desea entrenar, la ubicación del conjunto de datos de entrenamiento y dónde registrar el modelo. También hay parámetros opcionales que permiten realizar la evaluación y cambiar los hiperparámetros de la ejecución.
Una vez completada la ejecución, se guardan la ejecución finalizada y el punto de comprobación final, se clona el modelo y ese clon se registra en Unity Catalog como versión del modelo para la inferencia.
El modelo de la ejecución finalizada, no la versión clonada del modelo en Unity Catalog, y sus Puntos de comprobación de Composer y Hugging Face se guardan en MLflow. Los puntos de comprobación de Composer pueden usarse para tareas continuas de optimización.
Consulte Configuración de una ejecución de entrenamiento para obtener más información sobre los argumentos de la función create().
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Configuración de una ejecución de entrenamiento
En la tabla siguiente se resumen los parámetros de la foundation_model.create() función .
| Parámetro | Obligatorio | Type | Descripción |
|---|---|---|---|
model |
x | str | Nombre del modelo que se va a usar. Consulte Modelos admitidos. |
train_data_path |
x | str | Ubicación de los datos de entrenamiento. Puede ser una ubicación en Unity Catalog (<catalog>.<schema>.<table> o dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) o un conjunto de datos HuggingFace.Para INSTRUCTION_FINETUNE, los datos deben tener formato con cada fila que contenga un campo prompt y response.Para CONTINUED_PRETRAIN, se trata de una carpeta de archivos .txt. Consulte Preparación de datos para foundation Model Fine-tuning para formatos de datos aceptados y Tamaño de datos recomendado para el entrenamiento del modelo para recomendaciones de tamaño de datos. |
register_to |
x | str | Catálogo y esquema de Unity Catalog (<catalog>.<schema> o <catalog>.<schema>.<custom-name>) donde se registra el modelo después del entrenamiento para facilitar la implementación. Si custom-name no se proporciona, este valor predeterminado es el nombre de ejecución. |
data_prep_cluster_id |
str | Identificador de clúster del clúster que se va a usar para el procesamiento de datos de Spark. Esto es necesario para las tareas de entrenamiento supervisadas en las que los datos de entrenamiento se encuentra en una tabla Delta. Para obtener información sobre cómo buscar el identificador del clúster, consulte Obtención del identificador del clúster. | |
experiment_path |
str | Ruta de acceso al experimento de MLflow donde se guarda la salida de ejecución de entrenamiento (métricas y puntos de control). El valor predeterminado es el nombre de ejecución dentro del área de trabajo personal del usuario (es decir, /Users/<username>/<run_name>). |
|
task_type |
str | Tipo de tarea que se va a ejecutar. Puede ser CHAT_COMPLETION (valor predeterminado), CONTINUED_PRETRAIN o INSTRUCTION_FINETUNE. |
|
eval_data_path |
str | Ubicación remota de los datos de evaluación (si los hay). Debe seguir el mismo formato que train_data_path. |
|
eval_prompts |
List[str] | Lista de cadenas de solicitud para generar respuestas durante la evaluación. El valor predeterminado es None (no generar solicitudes). Los resultados se registran en el experimento cada vez que se controla el modelo. Las generaciones se producen en cada punto de control de modelo con los parámetros de generación siguientes: max_new_tokens: 100, temperature: 1, top_k: 50, top_p: 0.95, do_sample: true. |
|
custom_weights_path |
str | Ubicación remota de un punto de control de modelo personalizado para el entrenamiento. El valor predeterminado es None, lo que significa que la ejecución comienza a partir de los pesos previamente entrenados originales del modelo elegido. Si se proporcionan pesos personalizados, estos pesos se usan en lugar de los pesos previamente entrenados originales del modelo. Estos pesos deben ser un punto de control de Composer y deben coincidir con la arquitectura del model especificado. Consulte Build on custom model weights (Compilación en pesos de modelo personalizados). |
|
training_duration |
str | Duración total de la ejecución. El valor predeterminado es una época o 1ep. Se puede especificar en épocas (10ep) o tokens (1000000tok). |
|
learning_rate |
str | Velocidad de aprendizaje para el entrenamiento del modelo. Para todos los modelos distintos de Llama 3.1 405B Instruct, la velocidad de aprendizaje predeterminada es 5e-7. Para Llama 3.1 405B Instruct, la velocidad de aprendizaje predeterminada es 1.0e-5. El optimizador es DecoupledLionW con betas de 0,99 y 0,95 y sin disminución de peso. El programador de velocidad de aprendizaje es LinearWithWarmupSchedule con un calentamiento del 2 % de la duración total del entrenamiento y un multiplicador de velocidad de aprendizaje final de 0. |
|
context_length |
str | Longitud máxima de secuencia de un ejemplo de datos. Esto se usa para truncar los datos que son demasiado largos y empaquetar secuencias más cortas juntas para lograr una mayor eficiencia. El valor predeterminado es 8192 tokens o la longitud máxima del contexto para el modelo proporcionado, lo que sea menor. Puede usar este parámetro para configurar la longitud del contexto, pero no se admite la configuración más allá de la longitud máxima del contexto de cada modelo. Consulte Modelos admitidos para obtener la longitud máxima de contexto admitida de cada modelo. |
|
validate_inputs |
Booleano | Si se debe validar el acceso a las rutas de entrada antes de enviar el trabajo de entrenamiento. El valor predeterminado es True. |
Compilación en pesos de modelo personalizados
Foundation Model Fine-tuning admite la adición de pesos personalizados mediante el parámetro custom_weights_path opcional para entrenar y personalizar un modelo.
Para empezar, establezca custom_weights_path en la ruta de acceso del punto de control de Composer desde una ejecución de entrenamiento anterior. Las rutas de acceso de punto de control se pueden encontrar en la pestaña Artefactos de una ejecución de MLflow anterior. El nombre de la carpeta del punto de control corresponde al lote y la época de una instantánea determinada, como ep29-ba30/.

- Para proporcionar el punto de control más reciente de una ejecución anterior, establezca en
custom_weights_pathel punto de control Composer. Por ejemplo,custom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Para proporcionar un punto de control anterior, establezca
custom_weights_pathen una ruta de acceso a una carpeta que contenga.distcparchivos correspondientes al punto de control deseado, comocustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
A continuación, actualice el model parámetro para que coincida con el modelo base del punto de control que ha pasado a custom_weights_path.
En el ejemplo ift-meta-llama-3-1-70b-instruct-ohugkq siguiente se muestra una ejecución anterior que ajusta meta-llama/Meta-Llama-3.1-70B. Para ajustar el punto de control más reciente desde ift-meta-llama-3-1-70b-instruct-ohugkq, establezca las model variables y custom_weights_path de la siguiente manera:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Consulte Configuración de una ejecución de entrenamiento para configurar otros parámetros en la ejecución de ajuste.
Obtención del id. del clúster
Para recuperar el identificador del clúster:
En la barra de navegación izquierda del área de trabajo de Databricks, haga clic en Proceso.
En la tabla, haga clic en el nombre del clúster.
Haga clic en
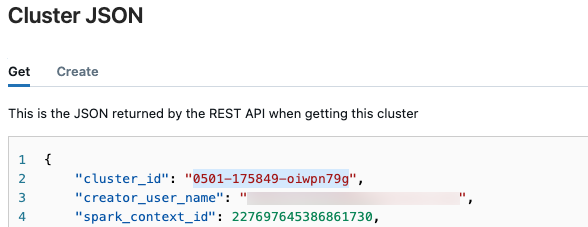
 en la esquina superior derecha y seleccione Ver JSON en el menú desplegable.
en la esquina superior derecha y seleccione Ver JSON en el menú desplegable.Aparece el archivo JSON del clúster. Copie el identificador del clúster, que es la primera línea del archivo.
Obtener el estado de una ejecución
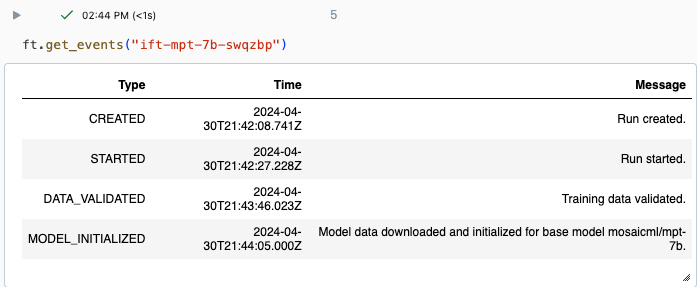
Puede realizar un seguimiento del progreso de una ejecución mediante la página Experimento en la interfaz de usuario de Databricks o mediante el comando de API get_events(). Para obtener más información, consulte Visualización, administración y análisis de ejecuciones de ajuste fino del modelo foundation.
Salida de ejemplo de get_events():
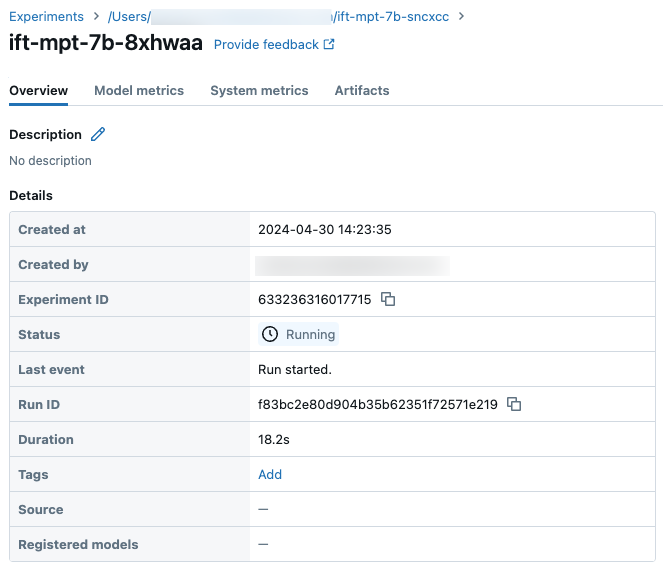
Detalles de ejecución de ejemplo en la página Experimento:
Pasos siguientes
Una vez completada la ejecución de entrenamiento, puede revisar las métricas en MLflow e implementar el modelo para la inferencia. Consulte los pasos del 5 al 7 del Tutorial: Creación e implementación de una ejecución de ajuste fino de Foundation Model.
Consulte el cuaderno de demostración Optimización de instrucciones: Reconocimiento de entidades con nombre para ver un ejemplo de optimización de instrucciones que recorre la preparación de los datos, la configuración de la ejecución del entrenamiento de optimización y la implementación.
Ejemplo de cuaderno
En el cuaderno siguiente se muestra un ejemplo de cómo generar datos sintéticos mediante el modelo Meta Llama 3.1 405B Instruct y cómo usarlos para ajustar un modelo:
Cuaderno Generación de datos sintéticos mediante Llama 3.1 405B Instruct
Recursos adicionales
- Ajuste preciso del modelo foundation
- Tutorial: Creación e implementación de una ejecución de optimización de modelos de Foundation
- Creación de una ejecución de entrenamiento mediante la interfaz de usuario de optimización de foundation Model
- Visualización, administración y análisis de ejecuciones de ajuste de modelos de Foundation
- Preparación de datos para el ajuste adecuado del modelo foundation