Análisis de registros de sitios web mediante una biblioteca de Python personalizada con un clúster de Apache Spark en HDInsight
En este cuaderno se muestra cómo analizar datos de registro mediante una biblioteca personalizada con Apache Spark en HDInsight. La biblioteca personalizada que usamos es una biblioteca de Python llamada iislogparser.py.
Prerequisites
Un clúster de Apache Spark en HDInsight. Para obtener instrucciones, vea Creación de clústeres Apache Spark en HDInsight de Azure.
Almacenamiento de datos sin procesar como RDD
En esta sección, usamos el cuaderno de Jupyter Notebook asociado con un clúster Apache Spark en HDInsight para ejecutar trabajos que procesan los datos de ejemplo sin procesar y los guardan como una tabla de Hive. Los datos de ejemplo corresponden a un archivo .csv (hvac.csv) que está disponible en todos los clústeres de manera predeterminada.
Una vez que los datos se guardan como una tabla de Apache Hive, en la sección siguiente nos conectaremos a la tabla de Hive mediante herramientas de BI como Power BI y Tableau.
En un explorador web, vaya a
https://CLUSTERNAME.azurehdinsight.net/jupyter, dondeCLUSTERNAMEes el nombre del clúster.Cree un nuevo notebook. Seleccione Nuevo y, a continuación, PySpark.
 Notebook" border="true":::
Notebook" border="true":::Se crea y se abre un nuevo cuaderno con el nombre Untitled.pynb. Seleccione el nombre del cuaderno en la parte superior y escriba un nombre descriptivo.

Dado que creó un cuaderno con el kernel PySpark, no necesitará crear ningún contexto explícitamente. Los contextos Spark y Hive se crearán automáticamente al ejecutar la primera celda de código. Puede empezar por importar los tipos que son necesarios para este escenario. Pegue el siguiente fragmento de código en una celda vacía y presione Mayús+Entrar.
from pyspark.sql import Row from pyspark.sql.types import *Crear un RDD con los datos de registro de ejemplo ya disponibles en el clúster. Puede tener acceso a los datos de la cuenta de almacenamiento predeterminada asociada al clúster en
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Ejecute el código siguiente:logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Recupere un registro de ejemplo establecido para comprobar que el paso anterior se ha completado correctamente.
logs.take(5)Debería ver una salida similar al siguiente texto:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Análisis de datos de registro mediante una biblioteca personalizada de Python
En la salida anterior, las primeras líneas del par incluyen la información de encabezado y cada línea restante coincide con el esquema descrito en ese encabezado. Analizar dichos registros podría ser complicado. Por lo tanto, utilizamos una biblioteca personalizada de Python (iislogparser.py) que ayuda a analizar estos registros de manera más fácil. De forma predeterminada, esta biblioteca se incluye con el clúster de Spark en HDInsight en
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Sin embargo, esta biblioteca no está en
PYTHONPATH, por lo que no podemos usarla mediante una instrucción de importación comoimport iislogparser. Para usar esta biblioteca, debemos distribuirla a todos los nodos de trabajo. Ejecute el siguiente fragmento de código:sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserproporciona una funciónparse_log_lineque devuelveNonesi una línea de registro es una fila de encabezado y devuelve una instancia de la claseLogLinesi encuentra una línea de registro. Utilice la claseLogLinepara extraer solo las líneas de registro desde el RDD:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Recupere un par de líneas de registro extraídas para comprobar que el paso se ha completado correctamente.
logLines.take(2)La salida debe ser similar a la siguiente:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]La clase
LogLine, a su vez, tiene algunos métodos útiles, comois_error(), que indica si una entrada de registro tiene un código de error. Use esta clase para calcular el número de errores en las líneas de registro extraídas y luego inicie todos los errores en un archivo diferente.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')La salida debe ser
There are 30 errors and 646 log entries.También puede usar Matplotlib para generar una visualización de los datos. Por ejemplo, si desea aislar la causa de las solicitudes que se ejecutan durante mucho tiempo, puede encontrar los archivos que, como promedio, tarden más tiempo en atenderse. El fragmento de código siguiente recupera los 25 recursos principales que tardaron más tiempo en atender una solicitud.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])La salida debe ser parecida al siguiente texto:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]También puede presentar esta información en forma de gráfico. Como primer paso para crear un trazado, permítanos crear primero una tabla temporal AverageTime. La tabla agrupa los registros por tiempo para ver si se produjeron picos de latencia inusuales en un momento dado.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')A continuación, puede ejecutar la siguiente consulta SQL para ubicar todos los registros en la tabla AverageTime .
%%sql -o averagetime SELECT * FROM AverageTimeLa instrucción mágica
%%sqlseguida de-o averagetimegarantiza que el resultado de la consulta persista localmente en el servidor de Jupyter (normalmente, el nodo principal del clúster). El resultado se conserva como una trama de datos Pandas con el nombre especificado averagetime.La salida debe ser parecida a la siguiente imagen:
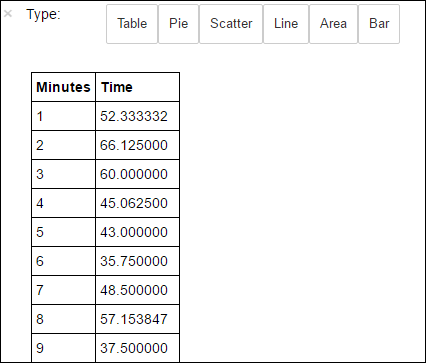 salida de la consulta sql" border="true":::
salida de la consulta sql" border="true":::Para obtener más información sobre la instrucción mágica
%%sql, vea Parámetros compatibles con la instrucción mágica %%sql.Ahora puede usar Matplotlib, una biblioteca que se usa para construir la visualización de datos, para crear un gráfico. Dado que el gráfico se debe crear a partir de la trama de datos averagetime persistente localmente, el fragmento de código debe comenzar con la función mágica
%%local. Esto garantiza que el código se ejecuta localmente en el servidor de Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')La salida debe ser parecida a la siguiente imagen:
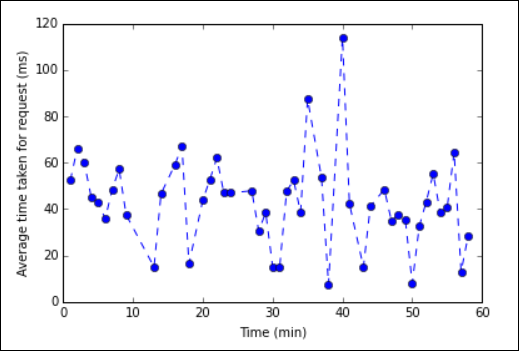 trazado de análisis de registros web" border="true":::
trazado de análisis de registros web" border="true":::Cuando haya terminado de ejecutar la aplicación, deberá cerrar el cuaderno para liberar los recursos. Para ello, en el menú File (Archivo) del cuaderno y seleccione Close and Halt (Cerrar y detener). De esta manera, se apaga y se cierra el cuaderno.
Pasos siguientes
Vea los artículos siguientes: