Seguimiento de experimentos y modelos de ML con MLflow
En este artículo, aprenderá a usar MLflow para realizar el seguimiento de los experimentos y las ejecuciones en áreas de trabajo de Azure Machine Learning.
El seguimiento es el proceso de guardar información relevante sobre los experimentos que se ejecutan. La información guardada (metadatos) varía en función del proyecto y puede incluir:
- Código
- Detalles del entorno (como la versión del sistema operativo, los paquetes de Python)
- Datos de entrada
- Configuración de parámetros
- Modelos
- Métricas de evaluación
- Visualizaciones de evaluación (como las matrices de confusión, los trazados de importancia)
- Resultados de la evaluación (incluidas algunas predicciones de evaluación)
Cuando trabaja con trabajos en Azure Machine Learning, Azure Machine Learning realiza un seguimiento automático de cierta información sobre los experimentos, como el código, el entorno y los datos de entrada y salida. Sin embargo, para otros, como modelos, parámetros y métricas, el generador de modelos debe configurar su seguimiento, ya que son específicos del escenario concreto.
Nota:
Si desea realizar un seguimiento de los experimentos que se ejecutan en Azure Databricks, consulte Seguimiento de experimentos de ML de Azure Databricks con MLflow y Azure Machine Learning. Para más información sobre el seguimiento de experimentos que se ejecutan en Azure Synapse Analytics, consulte Seguimiento de experimentos de ML de Azure Synapse Analytics con MLflow y Azure Machine Learning.
Ventajas de los experimentos de seguimiento
Se recomienda encarecidamente que los profesionales del aprendizaje automático realicen un seguimiento de los experimentos, tanto si está entrenando con trabajos en Azure Machine Learning como si está entrenando de forma interactiva en cuadernos. El seguimiento de experimentos le permite:
- Organizar todos los experimentos de aprendizaje automático en un solo lugar. A continuación, puede buscar y filtrar experimentos y explorar en profundidad para ver detalles sobre los experimentos que ejecutó antes.
- Compara experimentos, analiza los resultados y depura el entrenamiento del modelo con poco trabajo adicional.
- Reproducir o volver a ejecutar experimentos para validar los resultados.
- Mejorar la colaboración, ya que puede ver qué hacen otros compañeros de equipo, compartir los resultados del experimento y acceder a los datos del experimento mediante programación.
¿Por qué usar MLflow para realizar el seguimiento de experimentos?
Las áreas de trabajo de Azure Machine Learning son compatibles con MLflow, lo que significa que se puede usar MLflow para realizar un seguimiento de ejecuciones, métricas, parámetros y artefactos en las áreas de trabajo de Azure Machine Learning. Una ventaja importante del uso de MLflow para el seguimiento es que no es necesario cambiar las rutinas de entrenamiento para trabajar con Azure Machine Learning ni insertar ninguna sintaxis específica de la nube.
Para más información sobre todas las funcionalidades de MLflow y Azure Machine Learning admitidas, consulte MLflow y Azure Machine Learning.
Limitaciones
Es posible que algunos métodos disponibles en la API de MLflow no estén disponibles cuando están conectados a Azure Machine Learning. Para más información sobre las operaciones admitidas y no admitidas, consulte Matriz de compatibilidad para consultar ejecuciones y experimentos.
Requisitos previos
- Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Instale el paquete
mlflowdel SDK de MLflow y el complementoazureml-mlflowde Azure Machine Learning para MLflow:pip install mlflow azureml-mlflowSugerencia
Puede usar el paquete de
mlflow-skinny, que es un paquete MLflow ligero sin dependencias de ciencia de datos, interfaz de usuario, servidor o almacenamiento de SQL.mlflow-skinnyse recomienda para los usuarios que necesitan principalmente las funcionalidades de seguimiento y registro de MLflow sin importar el conjunto completo de características, incluidas las implementaciones.Un área de trabajo de Azure Machine Learning. Para crear un área de trabajo, consulte el tutorial Creación de recursos de aprendizaje automático. Revise los permisos de acceso que necesita para realizar las operaciones de MLflow en el área de trabajo.
Si realiza el seguimiento remoto (es decir, realiza un seguimiento de los experimentos que se ejecutan fuera de Azure Machine Learning), configure MLflow para que apunte al URI de seguimiento del área de trabajo de Azure Machine Learning. Para más información sobre cómo conectar MLflow al área de trabajo, consulte Configuración de MLflow para Azure Machine Learning.
Configuración del experimento
MLflow organiza la información en experimentos y ejecuciones (las ejecuciones se denominan trabajos en Azure Machine Learning). De forma predeterminada, las ejecuciones se registran en un experimento llamado Predeterminado que se crea automáticamente para ti. Puede configurar el experimento en el que se está realizando el seguimiento.
Para el entrenamiento interactivo, como en un cuaderno de Jupyter, use el comando mlflow.set_experiment() de MLflow. Por ejemplo, el siguiente fragmento de código configura un experimento:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Configurar la ejecución
Azure Machine Learning realiza un seguimiento de cualquier trabajo de entrenamiento en lo que MLflow llama a una ejecución. Usa ejecuciones para capturar todo el procesamiento que realiza el trabajo.
Al trabajar de forma interactiva, MLflow inicia el seguimiento de la rutina de entrenamiento en cuanto se intenta registrar información que requiere una ejecución activa. Por ejemplo, el seguimiento de MLflow se inicia al registrar una métrica, un parámetro o iniciar un ciclo de entrenamiento y la funcionalidad de registro automático de MLflow está habilitada. Sin embargo, normalmente resulta útil iniciar la ejecución explícitamente, especialmente si se desea capturar el tiempo total del experimento en el campo Duración. Para iniciar la ejecución explícitamente, usa mlflow.start_run().
Tanto si inicia la ejecución manualmente como si no, finalmente debe detener la ejecución, de modo que MLflow sepa que la ejecución del experimento se realiza y puede marcar el estado de la ejecución como Completado. Para detener una ejecución, use mlflow.end_run().
Se recomienda encarecidamente iniciar ejecuciones manualmente para que no olvide terminarlas al trabajar en cuadernos.
Para iniciar una ejecución manualmente y finalizarla cuando haya terminado de trabajar en el cuaderno:
mlflow.start_run() # Your code mlflow.end_run()Normalmente resulta útil usar el paradigma del administrador de contextos para ayudarle a recordar finalizar la ejecución:
with mlflow.start_run() as run: # Your codeAl iniciar una nueva ejecución con
mlflow.start_run(), puede ser útil especificar el parámetrorun_name, que más adelante se traducirá al nombre de la ejecución de la interfaz de usuario de Azure Machine Learning y le ayudará a identificar la ejecución más rápido:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Habilitación del registro automático de MLflow
Puede registrar métricas, parámetros y archivos con MLflow manualmente. Sin embargo, también se puede confiar en la funcionalidad de registro automático de MLflow. Cada marco de aprendizaje automático compatible con MLflow decide qué realizar un seguimiento automáticamente.
Para habilitar el registro automático, inserte el siguiente código antes del código de entrenamiento:
mlflow.autolog()
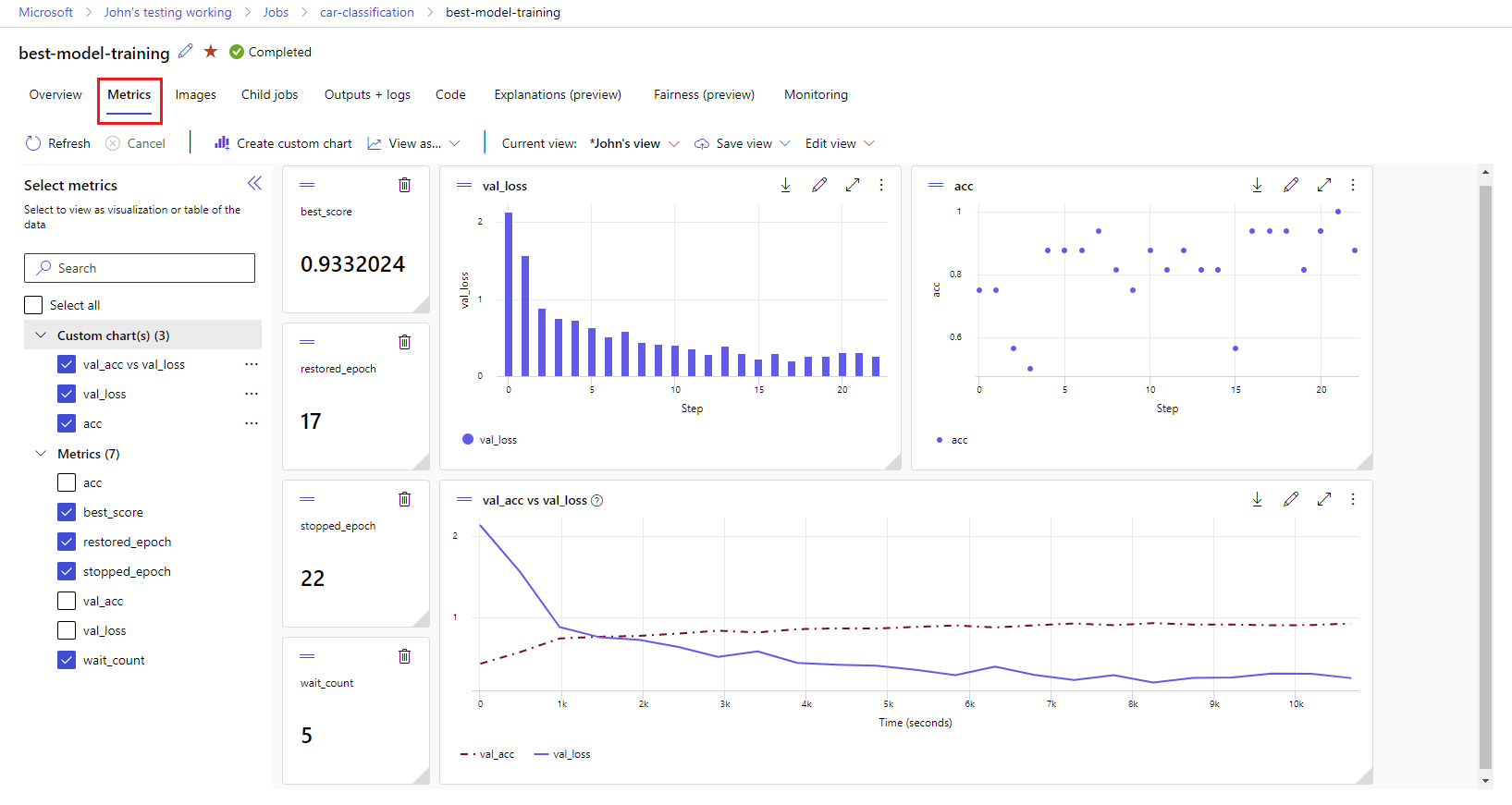
Visualización de las métricas y los artefactos en el área de trabajo
Las métricas y los artefactos procedentes del registro de MLflow se supervisan en el área de trabajo. Puede verlos y acceder a ellos en Studio en cualquier momento o acceder a ellos mediante programación a través del SDK de MLflow.
Para ver métricas y artefactos en Studio:
Vaya a Azure Machine Learning Studio.
Vaya a su área de trabajo.
Busque el experimento por su nombre en el área de trabajo.
Seleccione las métricas registradas para representar gráficos en el lado derecho. Puede personalizar los gráficos aplicando suavizado, cambiando el color o trazando varias métricas en un solo gráfico. También puede cambiar el tamaño y reorganizar el diseño como quiera.
Una vez que haya creado la vista deseada, guárdela para su uso posterior y compártala con sus compañeros de equipo mediante un vínculo directo.

Para el acceso o consulta de métricas, parámetros y artefactos mediante programación a través del SDK de MLflow, use mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Sugerencia
En el caso de las métricas, el código de ejemplo anterior solo devolverá el último valor de una métrica determinada. Si quiere recuperar todos los valores de una métrica determinada, use el método mlflow.get_metric_history. Para obtener más información sobre cómo recuperar valores de una métrica, consulte Obtención de parámetros y métricas de una ejecución.
Para descargar artefactos que ha registrado, como archivos y modelos, use mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Para obtener más información acerca de cómo recuperar o comparar información de experimentos y ejecuciones en Azure Machine Learning mediante MLflow, consulte Consulta y comparación de experimentos y ejecuciones con MLflow