Tutorial: Uso del diseñador para implementar un modelo de aprendizaje automático
En la primera parte de este tutorial ha entrenado un modelo de regresión lineal que predice los precios de automóviles. En esta segunda parte, usará el diseñador de Azure Machine Learning para implementar el modelo para que otros usuarios puedan usarlo.
Nota:
El diseñador admite dos tipos de componentes: componentes precompilados clásicos (v1) y componentes personalizados (v2). Estos dos tipos de componentes NO son compatibles.
Los componentes precompilados clásicos proporcionan componentes precompilados principalmente para el procesamiento de datos y las tareas tradicionales de aprendizaje automático, como la regresión y la clasificación. Este tipo de componentes siguen siendo compatibles, pero no se agregará ningún componente nuevo.
Los componentes personalizados le permiten encapsular su propio código como componente. Admiten el uso compartido de componentes entre áreas de trabajo y la creación sin problemas en las interfaces de Estudio de Machine Learning, la CLI v2 y el SDK v2.
En el caso de nuevos proyectos, le recomendamos que use componentes personalizados, que son compatibles con Azure Machine Learning v2, por lo que seguirán recibiendo nuevas actualizaciones.
Este artículo se aplica a los componentes precompilados clásicos y no es compatible con la CLI v2 y el SDK v2.
En este tutorial, hizo lo siguiente:
- Crear una canalización de inferencia en tiempo real.
- Crear un clúster de inferencia.
- Implementación del punto de conexión en tiempo real.
- Prueba del punto de conexión en tiempo real.
Requisitos previos
Complete la parte uno del tutorial para aprender a entrenar y puntuar un modelo de Machine Learning en el diseñador.
Importante
Si no ve los elementos gráficos que se mencionan en este documento, como los botones en Estudio o en el diseñador, es posible que no tenga el nivel de permisos adecuado para el área de trabajo. Póngase en contacto con el administrador de suscripciones de Azure para verificar que se le ha concedido el nivel de acceso correcto. Para obtener más información, consulte Administración de usuarios y roles.
Crear una canalización de inferencia en tiempo real
Para implementar la canalización, antes debe convertir la canalización de entrenamiento en una canalización de inferencia en tiempo real. Este proceso quita los componentes de entrenamiento y agrega entradas y salidas de servicios web para administrar las solicitudes.
Nota:
La característica de creación de una canalización de inferencia admite canalizaciones de entrenamiento que solo contengan los componentes integrados del diseñador y que tengan un componente como Entrenar modelo que genere el modelo entrenado.
Crear una canalización de inferencia en tiempo real
Seleccione Canalizaciones en el panel de navegación lateral y, luego, abra el trabajo de canalización que ha creado. En la página de detalles, encima del lienzo de la canalización, seleccione los puntos suspensivos ... y, luego, elija Crear canalización de inferencia>Canalización de inferencia en tiempo real.

La nueva canalización tendrá este aspecto:

Al seleccionar Create inference pipeline (Crear canalización de inferencia), suceden varias cosas:
- El modelo entrenado se almacena como un componente de Conjunto de datos en la paleta de componentes. Puede encontrarlo en My Datasets (Mis conjuntos de datos).
- Se quitan los componentes de entrenamiento como Train Model (Entrenar modelo) y Split Data (Dividir datos).
- El modelo entrenado guardado se vuelve a agregar a la canalización.
- Se agregan los componentes Entrada de servicio web y Salida de servicio web. Estos componentes muestran dónde entran los datos del usuario en la canalización y dónde se devuelven.
Nota:
De forma predeterminada, la entrada del servicio web espera el mismo esquema de datos que los datos de salida del componente que se conecta al mismo puerto de bajada. En este ejemplo, la entrada del servicio web y los datos de precios de automóviles (sin procesar) se conectan al mismo componente de bajada, por lo que la entrada de servicio web espera el mismo esquema de datos que los datos de precios de automóviles (sin procesar) y la columna de variable de destino
priceque se incluyen en el esquema. Sin embardo, cuando asigne una puntuación a los datos, no conocerá los valores de las variables de destino. En ese caso, puede quitar la columna de variable de destino de la canalización de inferencia mediante el componente Seleccionar columnas de conjunto de datos. Asegúrese de que la salida de Seleccionar columnas de conjunto de datos que quita la columna de variable de destino está conectada al mismo puerto que la salida del componente Entrada del servicio web.Seleccione Configurar y enviary use el mismo destino de proceso y experimento que usó en la parte uno.
Si este es el primer trabajo, la ejecución de la canalización puede tardar hasta 20 minutos en finalizar. La configuración del proceso predeterminada tiene un tamaño de nodo mínimo de 0, lo que significa que el diseñador debe asignar recursos después de estar inactivo. Los trabajos de canalización repetidos tardarán menos en terminar, dado que los recursos del proceso ya están asignados. Además, el diseñador usa resultados almacenados en la caché de cada componente para mejorar aún más la eficiencia.
Vaya al detalle del trabajo de canalización de inferencia en tiempo real seleccionando Detalles del trabajo en el panel izquierdo.
Seleccione Implementar en la página de detalles del trabajo.



Creación de un clúster de inferencia
En el cuadro de diálogo que aparece, puede seleccionar entre los clústeres de Azure Kubernetes Service (AKS) existentes aquel en el que quiere implementar el modelo. Si no tiene un clúster de AKS, use los pasos siguientes para crear uno.
Vaya a la página Proceso seleccionando Proceso en el cuadro de diálogo.
En la cinta de navegación, seleccione Clústeres de Kubernetes>+ Nuevo.
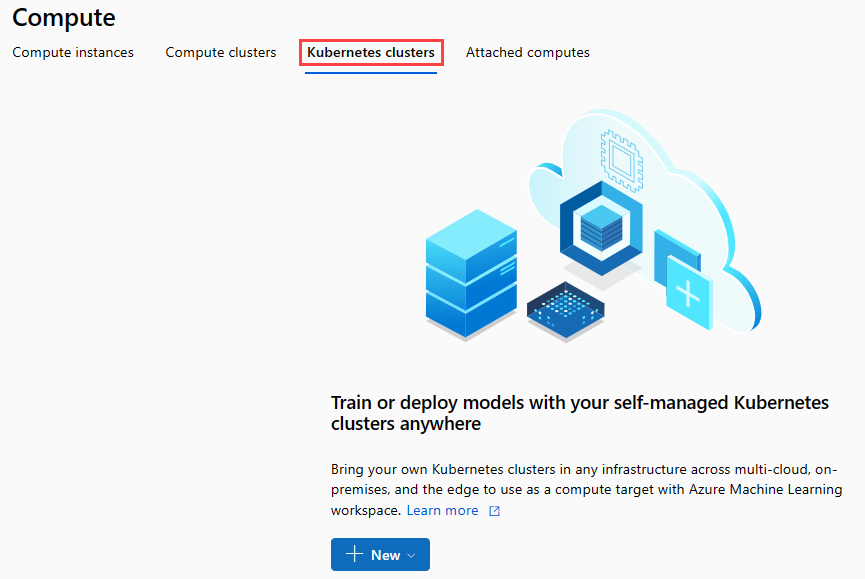
En el panel del clúster de inferencia, configure un nuevo servicio de Kubernetes.
Escriba aks-compute en Compute name (Nombre de proceso).
Seleccione una región cercana que esté disponible para la región.
Seleccione Crear.
Nota
La creación de un servicio AKS tarda unos 15 minutos. Puede comprobar el estado de aprovisionamiento en la página Inference Clusters (Clústeres de inferencia).
Implementación del punto de conexión en tiempo real
Después de que el servicio de AKS haya terminado de aprovisionarse, vuelva a la canalización de inferencia en tiempo real para finalizar la implementación.
Seleccione Implementar encima del lienzo.
Seleccione Deploy new real-time endpoint (Implementar nuevo punto de conexión en tiempo real).
Seleccione el clúster de AKS que ha creado.
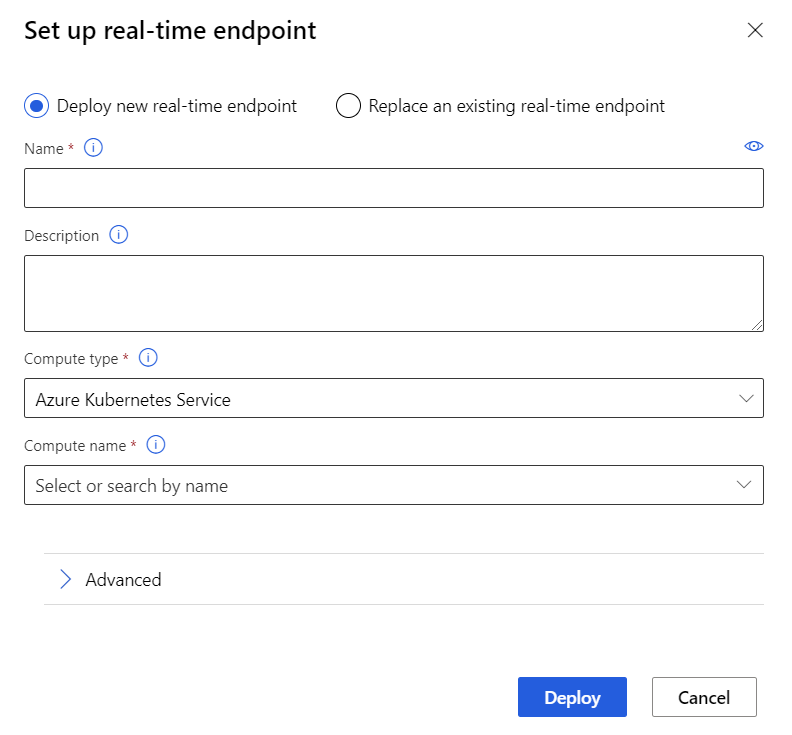
También puede cambiar la configuración avanzada del punto de conexión en tiempo real.
Configuración avanzada Descripción Enable Application Insights diagnostics and data collection (Habilitar la recopilación de datos y el diagnóstico de Application Insights) Permite que Azure Application Insights recopile datos de los puntos de conexión implementados.
Valor predeterminado: false.Scoring timeout (Tiempo de espera de la puntuación) Tiempo de espera en milisegundos para forzar la puntuación de las llamadas al servicio web.
De forma predeterminada: 60 000.Auto scale enabled (Escalado automático habilitado) Permite la escalabilidad automática para el servicio web.
Valor predeterminado: true.Min replicas (Número mínimo de réplicas) Número mínimo de contenedores que se van a usar al escalar automáticamente este servicio web.
De forma predeterminada: 1.Max replicas (Número máximo de réplicas) Número máximo de contenedores que se van a usar al escalar automáticamente este servicio web.
De forma predeterminada: 10.Target utilization (Uso de destino) El uso de destino (como porcentaje) que el escalador automático debe intentar mantener para este servicio web.
De forma predeterminada: 70.Refresh period (Período de actualización) Frecuencia (en segundos) con la que la escalabilidad automática intenta escalar este servicio web.
De forma predeterminada: 1.CPU reserve capacity (Capacidad de reserva de CPU) Número de núcleos de CPU que se asigna a este servicio web.
De forma predeterminada: 0.1.Memory reserve capacity (Capacidad de reserva de memoria) Cantidad de memoria (en GB) que se va a asignar a este servicio web.
De forma predeterminada: 0.5.Seleccione Implementar.
Aparece una notificación de éxito del centro de notificaciones después de finalizar la implementación. Esto puede llevar unos minutos.


Sugerencia
También puede implementar en una instancia de contenedor de Azure si selecciona Instancia de contenedor de Azure para Tipo de proceso en el cuadro de configuración de punto de conexión en tiempo real. Instancia de Azure Container se usa con fines de pruebas o desarrollo. Use una instancia de contenedor de Azure para cargas de trabajo basadas en CPU a baja escala que requieran menos de 48 GB de RAM.
Prueba del punto de conexión en tiempo real
Una vez finalizada la implementación, puede ver el punto de conexión en tiempo real; para ello, vaya a la página Endpoints (Puntos de conexión).
En la página Puntos de conexión, seleccione el punto de conexión que implementó.
En la pestaña Detalles, puede ver más información, como el identificador URI de REST, la definición de Swagger, el estado y las etiquetas.
En la pestaña Consumir, encontrará código de consumo de ejemplo y claves de seguridad. Además, podrá establecer los métodos de autenticación.
En la pestaña Registros de implementación, puede encontrar los registros de implementación detallados del punto de conexión en tiempo real.
Para probar el punto de conexión, vaya a la pestaña Prueba. Aquí puede especificar los datos de prueba y seleccionar Probar para verificar la salida del punto de conexión.
Actualización del punto de conexión en tiempo real
Puede actualizar el punto de conexión en línea con el nuevo modelo entrenado en el diseñador. En la página de detalles del punto de conexión en línea, busque el trabajo de canalización de entrenamiento anterior y el trabajo de canalización de inferencia.
Puede encontrar y modificar el borrador de canalización de entrenamiento en la página principal del diseñador.
También puede abrir el vínculo del trabajo de canalización de entrenamiento y, a continuación, clonarlo en un nuevo borrador de canalización para continuar con la edición.

Después de enviar la canalización de entrenamiento modificada, vaya a la página de detalles del trabajo.
Cuando finalice el trabajo, haga clic con el botón derecho en Entrenar modelo y seleccione Registrar datos.

Escriba el nombre de entrada y seleccione Tipo de archivo.
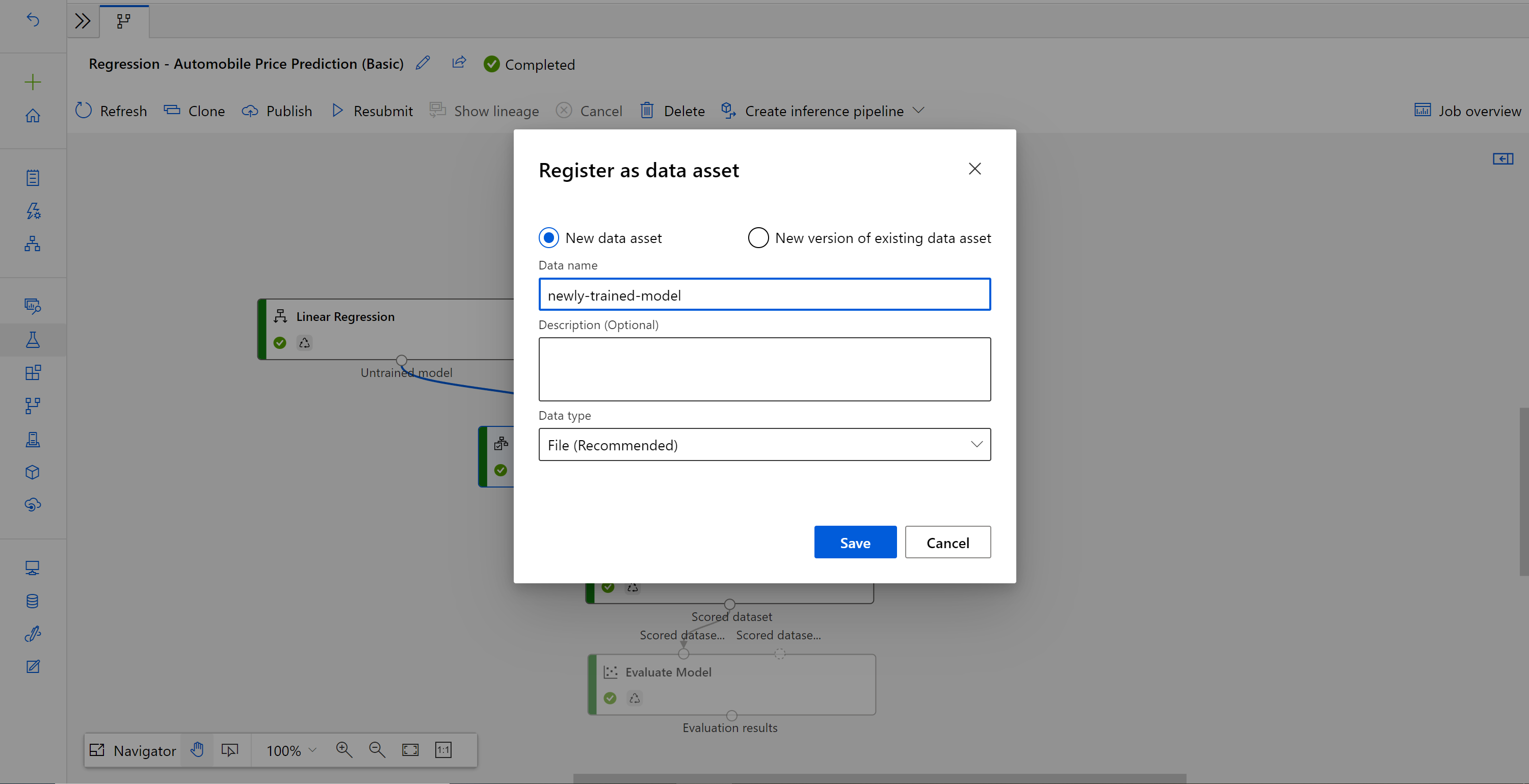
Después de que el conjunto de datos se registre correctamente, abra el borrador de canalización de inferencia o clone el trabajo de canalización de inferencia anterior en un nuevo borrador. En el borrador de canalización de inferencia, reemplace el modelo entrenado anterior que se muestra como el nodo MD-XXXX conectado al componente Score Model por el conjunto de datos recién registrado.

Si necesita actualizar el elemento de preprocesamiento de datos en la canalización de entrenamiento y quiere actualizarlo en la canalización de inferencia, el procesamiento es similar a los pasos anteriores.
Para ello, es preciso registrar la salida de la transformación del componente de transformación como conjunto de datos.
Luego, reemplace de forma manual el componente TD- en la canalización de inferencia con el conjunto de datos registrado.

Después de modificar la canalización de inferencia con el modelo o transformación recién entrenados, envíela. Una vez completado el trabajo, impleméntelo en el punto de conexión en línea existente implementado anteriormente.
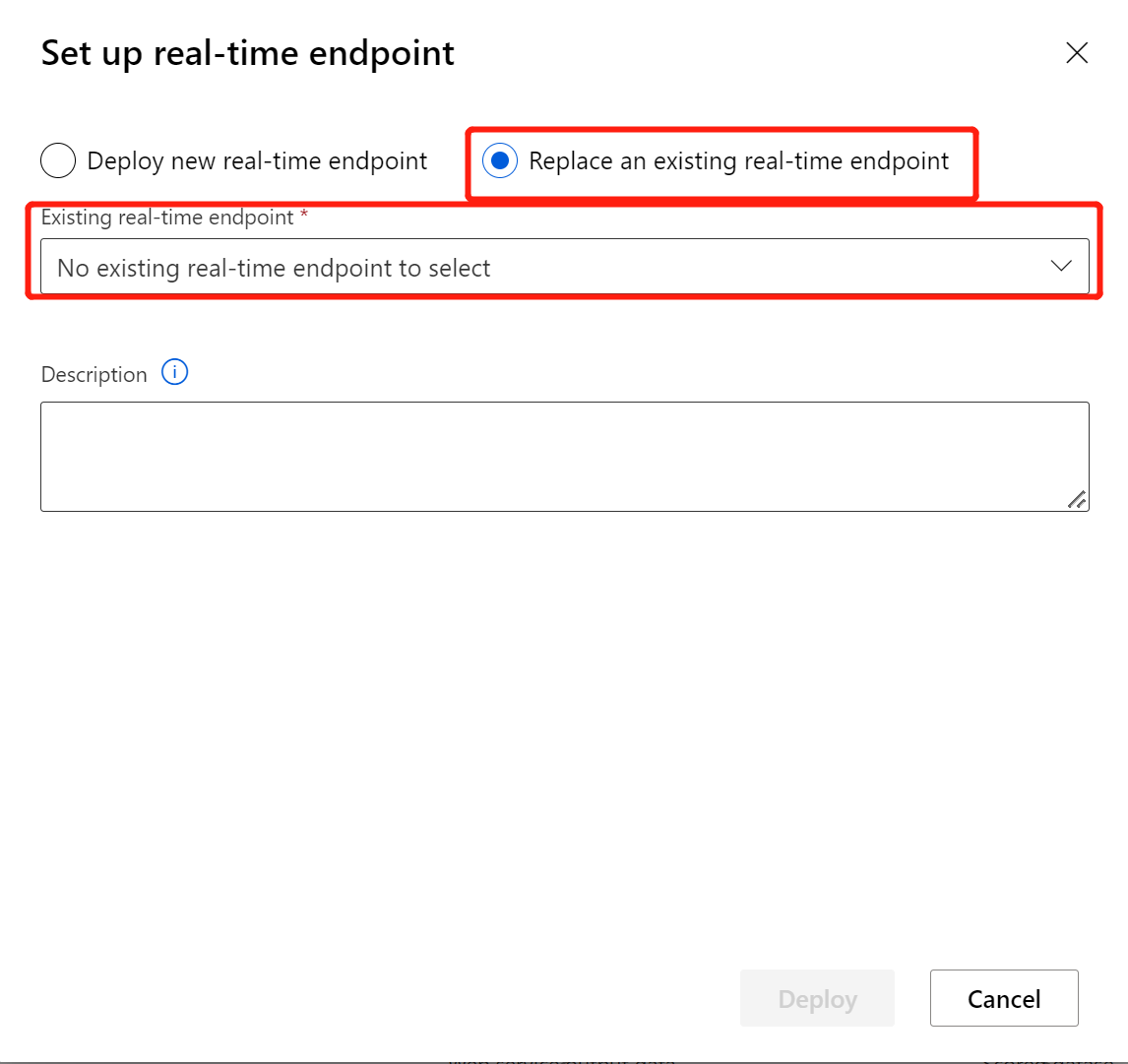




Limitaciones
Debido a la limitación del acceso al almacén de datos, si la canalización de inferencia contiene el componente Importar datos o Exportar datos, se quitará automáticamente cuando se implemente en el punto de conexión en tiempo real.
Si tiene conjuntos de datos en la canalización de inferencia en tiempo real y quiere implementarlos en el punto de conexión en tiempo real, este flujo actualmente solo admite conjuntos de datos registrados del almacén de datos Blob. Si quiere usar conjuntos de datos de otros almacenes de datos de tipo, puede usar Seleccionar columna para conectarse con el conjunto de datos inicial con los valores de seleccionar todas las columnas, registrar las salidas deSeleccionar columna como conjunto de datos de archivo y, luego, reemplazar el conjunto de datos inicial en la canalización de inferencia en tiempo real por este conjunto de datos recién registrado.
Si el gráfico de inferencia contiene el componente Escribir datos manualmente, que no está conectado al mismo puerto que el componente Entrada de servicio web, el componente Escribir datos manualmente no se ejecutará durante el procesamiento de llamadas HTTP. Una solución es registrar las salidas de ese componente Escribir datos manualmente como un conjunto de datos y, luego, en el borrador de canalización de inferencia, reemplazar el componente Escribir datos manualmente por el conjunto de datos registrado.


Limpieza de recursos
Importante
Los recursos que creó pueden usarse como requisitos previos de otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Eliminar todo el contenido
Si no va a usar nada de lo que ha creado, elimine el grupo de recursos completo para que no le genere gastos.
En Azure Portal, seleccione Grupos de recursos en la parte izquierda de la ventana.

En la lista, seleccione el grupo de recursos que creó.
Seleccione Eliminar grupo de recursos.
Al eliminar el grupo de recursos también se eliminan todos los recursos que creó en el diseñador.
Eliminación de recursos individuales
En diseñador donde creó el experimento, elimine recursos individuales; para ello, selecciónelos y, luego, haga clic en el botón Eliminar.
El destino de proceso que ha creado aquí se escala automáticamente a cero nodos cuando no se usa. Esta acción se lleva a cabo para minimizar los cargos. Si quiere eliminar el destino de proceso, siga estos pasos:
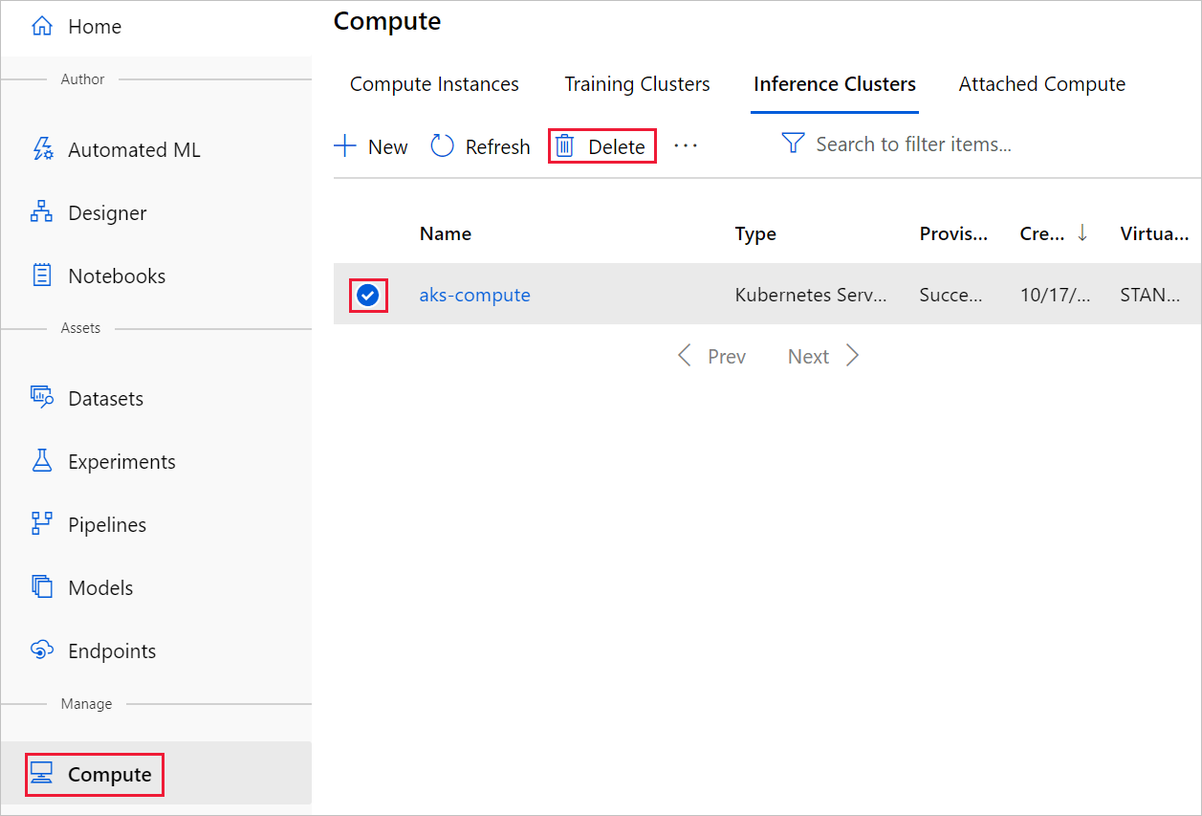
Puede anular el registro de los conjuntos de datos del área de trabajo seleccionando cada conjunto de datos y Anular el registro.
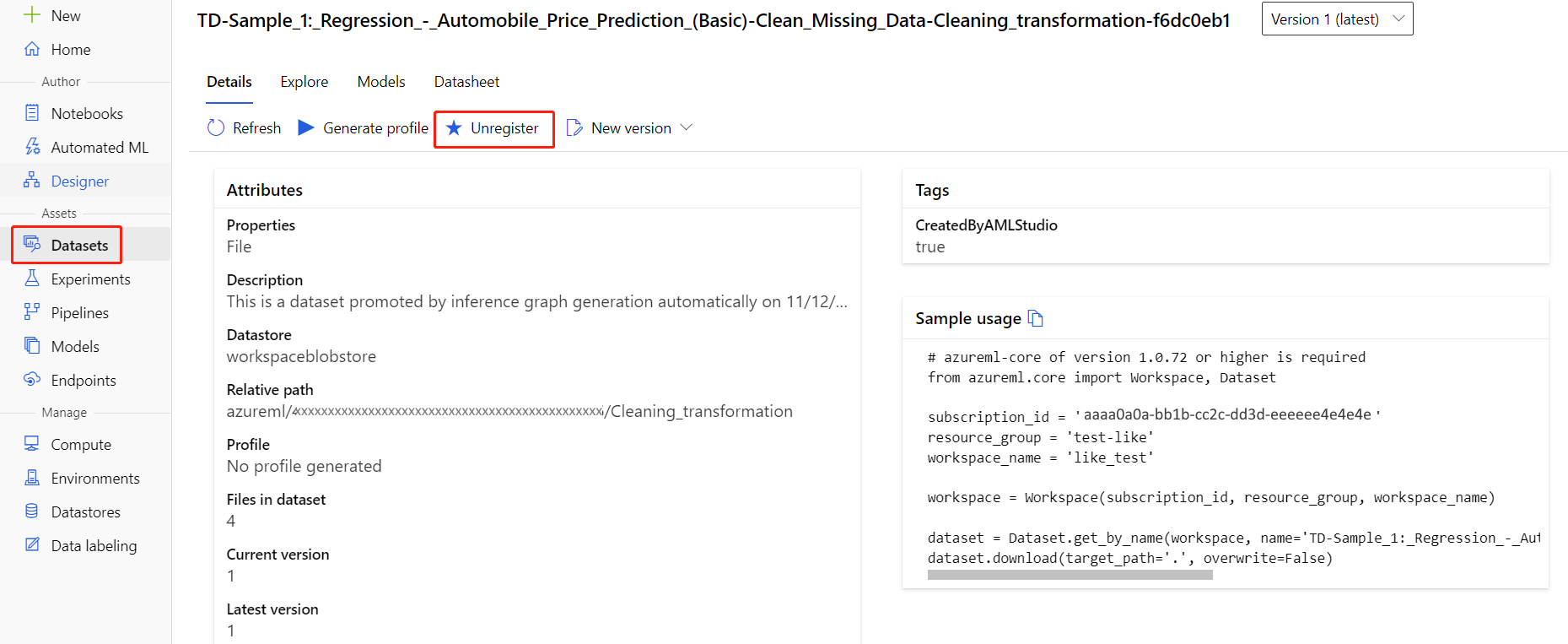
Para eliminar un conjunto de datos, vaya a la cuenta de almacenamiento mediante Azure Portal o el Explorador de Azure Storage y elimine manualmente esos recursos.
Contenido relacionado
En este tutorial, ha aprendido cómo crear, implementar y usar un modelo de aprendizaje automático en el diseñador. Para obtener más información sobre cómo usar el diseñador, consulte los artículos siguientes: