Asistentes para la importación en Búsqueda de Azure AI
Búsqueda de Azure AI tiene dos asistentes para la importación, que automatizan la indexación y las definiciones de objetos para que pueda empezar a realizar consultas inmediatamente. Si es la primera vez que utiliza Búsqueda de Azure AI, estos asistentes son una de las características más eficaces que tiene a su disposición. Con un mínimo esfuerzo, puede crear una canalización de indexación o enriquecimiento que ejercite la mayor parte de la funcionalidad de Azure AI Search.
El Asistente para la importación de datos admite flujos de trabajo no vectoriales. Puede extraer texto alfanumérico de documentos sin formato. También puede configurar la IA aplicada y las aptitudes integradas que infieren la estructura y generan contenido que permite búsquedas de texto a partir de archivos de imagen y datos no estructurados.
El Asistente para la importación y vectorización de datos admite la vectorización. Debe especificar una implementación existente de un modelo de inserción, pero el asistente realiza la conexión, formula la solicitud y controla la respuesta. Genera contenido vectorial a partir de contenido de texto o imágenes.
Si usa el asistente para pruebas de concepto, en este artículo se explica el funcionamiento interno de los asistentes para que pueda usarlos de forma más eficaz.
Este artículo no es una guía paso a paso. Para obtener ayuda sobre cómo usar el asistente con datos de ejemplo integrados, consulte:
- Inicio rápido: Creación de un índice de búsqueda
- Inicio rápido: Creación de una traducción de texto y un conjunto de aptitudes de entidad
- Inicio rápido: Creación de un índice vectorial
- Inicio rápido: Búsqueda de imágenes (vectores)
Inicio de los asistentes
En Azure Portal, abra la página del servicio de búsqueda desde el panel o busque el servicio en la lista.
En la parte superior de la página de información general del servicio, seleccione Importar datos o Importar y vectorizar datos.
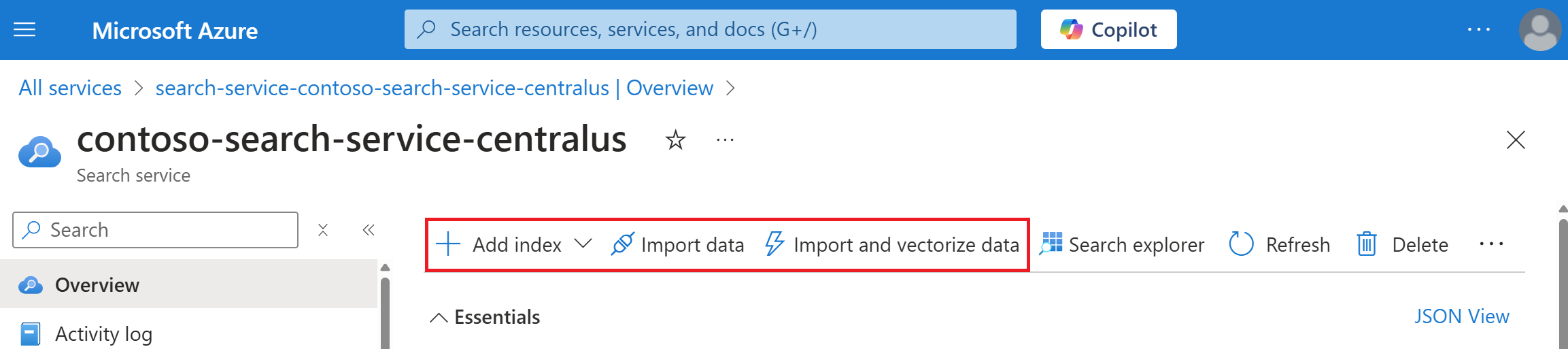
Los asistentes se abren totalmente expandidos en la ventana del explorador para que tenga más espacio para trabajar.
Si seleccionó Importar datos, puede seleccionar la opción Ejemplos para usar una muestra precompilada de datos de un origen de datos compatible.
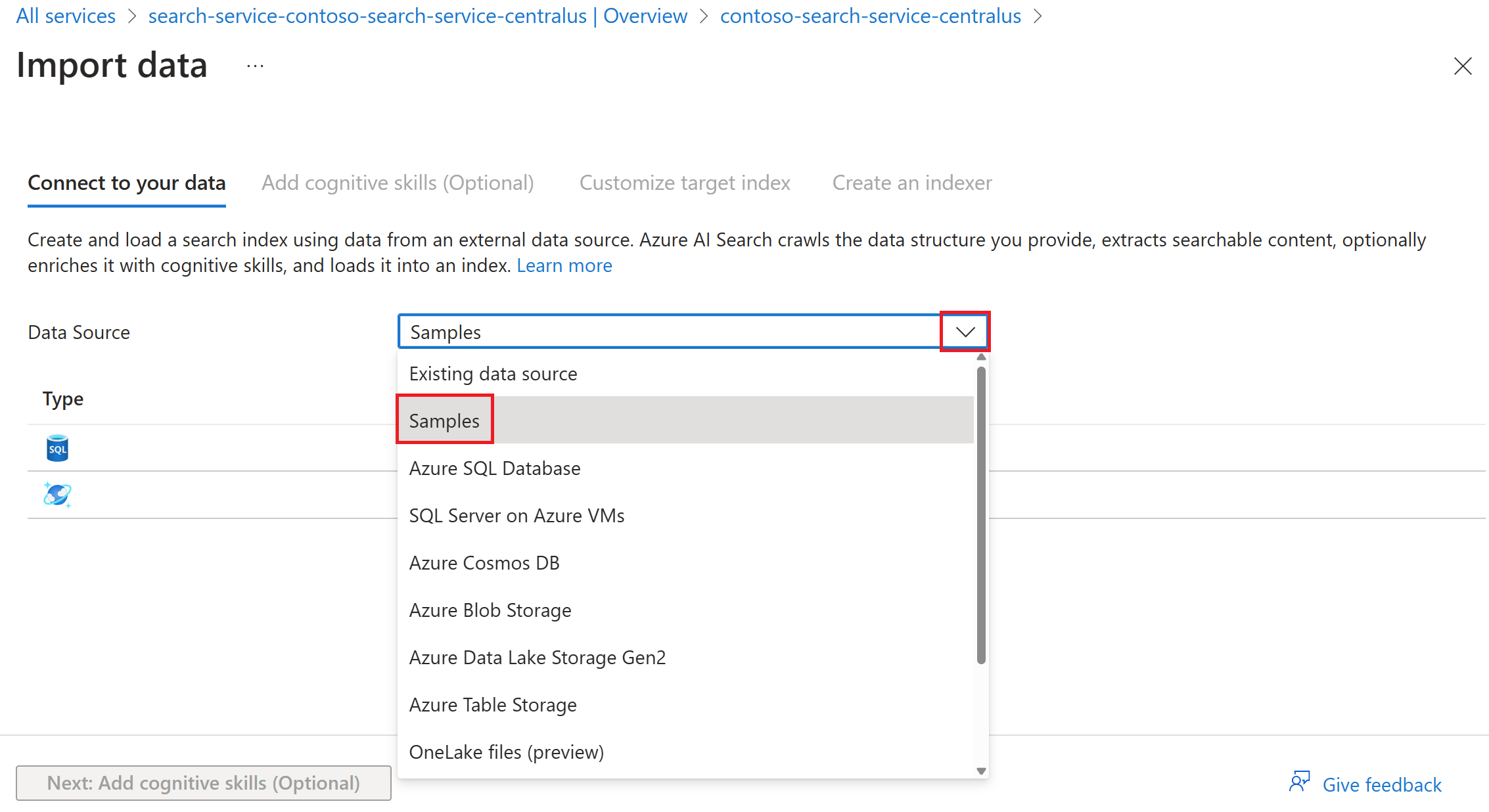
Siga los pasos restantes del asistente para crear el índice y el indexador.
Importar datos también se puede ejecutar desde otros servicios de Azure, como Azure Cosmos DB, Azure SQL Database, SQL Managed Instance y Azure Blob Storage. Busque Agregar Azure AI Search en el panel de navegación izquierdo de la página de información general del servicio.
Objetos creados por el asistente
El asistente generará los objetos de la tabla siguiente. Una vez creados los objetos, puede revisar sus definiciones JSON en el portal o llamarlos desde el código.
| Object | Descripción |
|---|---|
| Indexador | Un objeto de configuración que especifica un origen de datos, un índice de destino, un conjunto de aptitudes opcional, una programación opcional y valores de configuración opcionales para el control de errores y la codificación en base 64. |
| Origen de datos | Conserva la información de conexión en un origen de datos compatible en Azure. Un objeto de origen de datos se utiliza exclusivamente con indexadores. |
| Índice | Estructura de datos física que se usa para la búsqueda de texto completo y otras consultas. |
| Conjunto de aptitudes | Opcional. Un conjunto completo de instrucciones para manipular, transformar y dar forma al contenido que incluye el análisis y la extracción de información de archivos de imagen. Los conjuntos de aptitudes también se usan para la vectorización integrada. A menos que el volumen de trabajo esté por debajo del límite de 20 transacciones por indexador al día, el conjunto de aptitudes debe incluir una referencia a un recurso de varios servicios de Azure AI, que proporcione enriquecimiento. Para la vectorización integrada, puede usar Visión de Azure AI o un modelo de inserción en el catálogo de modelos de Estudio de IA de Azure. |
| Almacén de conocimiento | Opcional. Almacena la salida en tablas y blobs de Azure Storage para realizar análisis independientes o procesamientos de bajada en escenarios que no incluyan búsqueda. |
Ventajas
Antes de escribir cualquier código, puede usar los asistentes para crear prototipos y pruebas de concepto. Los asistentes se conectan a orígenes de datos externos, muestrean los datos para crear un índice inicial y, luego, los importan (y, opcionalmente, vectorizan) como documentos JSON en un índice de Búsqueda de Azure AI.
Si va a evaluar conjuntos de aptitudes, el asistente controlará todas las asignaciones de los campos de salida y agregará funciones auxiliares para crear objetos utilizables. La división de texto se agrega si especifica un modo de análisis. La combinación de texto se agrega si elige el análisis de imágenes para que el asistente pueda volver a unir descripciones de texto con el contenido de la imagen. Se agregan las aptitudes de conformador para admitir proyecciones válidas si elige la opción de almacén de conocimiento. Todas las tareas anteriores incluyen una curva de aprendizaje. Si es la primera vez que utiliza el enriquecimiento, la capacidad de controlar estos pasos le permite medir el valor de una aptitud sin tener que invertir mucho tiempo ni esfuerzo.
El muestreo es el proceso mediante el cual se infiere un esquema de índice y tiene algunas limitaciones. Al crear el origen de datos, el asistente elige una muestra aleatoria de documentos para decidir las columnas que forman parte del origen de datos. No se leen todos los archivos, ya que esto podría tardar horas en el caso de orígenes de datos muy grandes. Dada una selección de documentos, los metadatos de origen como, por ejemplo, el nombre o el tipo de campo, se usan para crear una colección de campos en un esquema de índice. En función de la complejidad de los datos de origen, es posible que tenga que modificar el esquema inicial para que sea más preciso, o bien ampliarlo para que sea más exhaustivo. Puede insertar los cambios en la página de definición del índice.
En general, las ventajas del uso del asistente son claras: siempre que se cumplan los requisitos, puede crear un índice consultable en cuestión de minutos. Algunas de las dificultades de la indexación como, por ejemplo, serializar datos como documentos JSON, se controlan mediante el asistente.
Limitaciones
El asistente no está exento de limitaciones. A continuación se resumen las restricciones:
El asistente no admite la iteración ni la reutilización. Cada paso a través del asistente crea una nueva configuración del índice, del conjunto de aptitudes y del indexador. Solo los orígenes de datos se pueden conservar y reutilizar en el asistente. Para editar o refinar otros objetos, elimínelos y empiece de nuevo o use las API de REST o el SDK de .NET para modificar las estructuras.
El contenido de origen debe residir en un origen de datos compatible.
El muestreo se realiza sobre un subconjunto de los datos de origen. En el caso de orígenes de datos de gran tamaño, es posible que el asistente omita algunos campos. Es posible que tenga que ampliar el esquema o corregir los tipos de datos inferidos si el muestreo es insuficiente.
El enriquecimiento con IA, tal como se expone en el portal, se limita a un subconjunto de aptitudes integradas.
El almacén de conocimiento, que se puede crear mediante el asistente, se limita a algunas proyecciones predeterminadas y usa la convención de nomenclatura predeterminada. Si quiere personalizar los nombres o las proyecciones, deberá crear el almacén de conocimiento mediante la API REST o los SDK.
Conexiones seguras
Los asistentes para la importación realizan conexiones salientes mediante el controlador del portal y los puntos de conexión públicos. No podrá usar los asistentes si se accede a los recursos de Azure a través de una conexión privada o a través de un vínculo privado compartido.
Puede usar los asistentes a través de conexiones públicas restringidas, pero no todas las funcionalidades están disponibles.
En un servicio de búsqueda, la importación de los datos de ejemplo integrados requiere un punto de conexión público y ninguna regla de firewall.
Los datos de ejemplo se hospedan en Microsoft en recursos específicos de Azure. El controlador del portal se conecta a esos recursos a través de un punto de conexión público. Si coloca el servicio de búsqueda detrás de un firewall, obtendrá este error al intentar recuperar los datos de ejemplo integrados:
Import configuration failed, error creating Data Source, seguido de"An error has occured.".En los orígenes de datos de Azure admitidos y protegidos por firewalls, podrá recuperar datos si tiene implementadas las reglas de firewall correctas.
El recurso de Azure debe admitir solicitudes de red desde la dirección IP del dispositivo usado en la conexión. También debe incluir Búsqueda de Azure AI como servicio de confianza en la configuración de red del recurso. Por ejemplo, en Azure Storage, puede incluir
Microsoft.Search/searchServicescomo servicio de confianza.En las conexiones a una cuenta de varios servicios de Azure AI que proporcione, o en las conexiones para insertar modelos implementados en Estudio de IA de Azure o Azure OpenAI, debe habilitarse el acceso a Internet público. Se llama a estos recursos de Azure cuando se usan aptitudes integradas en el Asistente para la importación de datos o la vectorización integrada en el asistente para la importación y vectorización de datos.
En el asistente para la importación y vectorización de datos, el error es
"Access denied due to Virtual Network/Firewall rules."En el asistente para la importación de datos, no hay ningún error, pero no se creará el conjunto de aptitudes.
Si la configuración del firewall impide que los flujos de trabajo del asistente se realicen correctamente, considere la posibilidad de usar scripts o enfoques mediante programación en su lugar.
Flujo de trabajo
El asistente se organiza en cuatro pasos principales:
Conexión a un origen de datos de Azure compatible.
Creación de un esquema de índice que se deduce mediante el muestreo de los datos de origen.
Opcionalmente, agregue IA aplicada para extraer o generar contenido y estructura. En este paso se recopilan entradas para crear un almacén de conocimiento.
Ejecute el asistente para crear objetos, opcionalmente vectorizar datos, cargar datos en un índice, establecer una programación y otras opciones de configuración.
El flujo de trabajo es una canalización, por lo que es de dirección única. No puede usar el asistente para editar ninguno de los objetos creados, pero puede usar otras herramientas del portal, como el diseñador de índices o de indexadores o los editores JSON, para las actualizaciones permitidas.
Configuración del origen de datos en el asistente
Los asistentes se conectan a un origen de datos admitido externo mediante la lógica interna que proporcionan los indexadores de Búsqueda de Azure AI, que están equipados para muestrear el origen, leer los metadatos, descifrar documentos para leer el contenido y la estructura, y serializar el contenido como JSON para la importación posterior en Búsqueda de Azure AI.
Puede pegar una conexión a un origen de datos compatible en una suscripción o región diferente, pero el selector Elegir una conexión existente tiene como ámbito la suscripción activa.
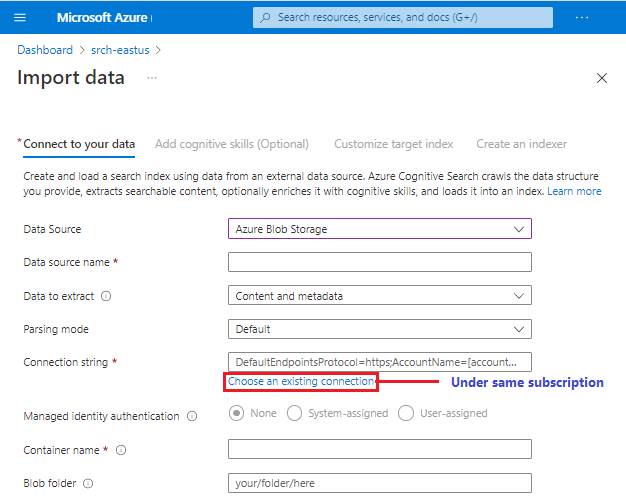
No se garantiza que todos los orígenes de datos de la versión preliminar estén disponibles en el asistente. Como cada origen de datos tiene el potencial de introducir otros cambios de nivel inferior, solo se agregará un origen de datos de la versión preliminar a la lista de orígenes de datos si es totalmente compatible con todas las experiencias del asistente, como la definición del conjunto de aptitudes y la inferencia de esquemas de índice.
Solo se puede importar desde una única tabla, vista de base de datos o estructura de datos equivalente; sin embargo, la estructura puede incluir subestructuras jerárquicas o anidadas. Para más información, consulte el artículo sobre la Cómo modelar tipos complejos.
Configuración del conjunto de aptitudes en el asistente
La configuración del conjunto de aptitudes se produce después de la definición del origen de datos, porque el tipo de origen de datos informará de la disponibilidad de determinadas aptitudes integradas. En concreto, si va a indexar archivos de Blob Storage, la elección del modo de análisis de dichos archivos determinará si el análisis de sentimiento estará disponible.
El asistente agrega las aptitudes que elija. También agrega otras aptitudes necesarias para lograr un resultado exitoso. Por ejemplo, si especifica un almacén de conocimiento, el asistente agrega una aptitud de conformador para admitir proyecciones (o estructuras de datos físicos).
Los conjuntos de aptitudes son opcionales y hay un botón en la parte inferior de la página para saltar si no quiere el enriquecimiento con IA.
Configuración del esquema de índice en el asistente
Los asistentes muestrean el origen de datos para detectar los campos y sus tipos. En función del origen de datos, también puede ofrecer campos para indexar metadatos.
Como el muestreo es un ejercicio impreciso, revise el índice para atender a las consideraciones siguientes:
¿La lista de campos es precisa? Si el origen de datos contiene campos que no se han seleccionado en el muestreo, puede agregar manualmente los nuevos campos que falten en el muestreo y quitar los que no agreguen valor a una experiencia de búsqueda o que no se vayan a utilizar en una expresión de filtro o en un perfil de puntuación.
¿Es el tipo de datos adecuado para los datos entrantes? Azure AI Search admite los tipos de datos de Entity Data Model (EDM). En el caso de datos de Azure SQL, hay un gráfico de asignaciones que muestra valores equivalentes. Para más información, consulte Transformaciones y asignaciones de campos.
¿Tiene un campo que pueda actuar como clave? Este campo debe ser Edm.string y debe identificar de forma exclusiva un único documento. En el caso de los datos relacionales, se podría asignar a una clave principal. En el caso de los blobs, esta podría ser
metadata-storage-path. Si los valores de campo incluyen espacios o guiones, debe establecer la opción Claves de codificación Base 64 del paso Crear un indexador en Opciones avanzadas, a fin de suprimir la comprobación de validación para estos caracteres.Establezca los atributos para determinar cómo se utiliza ese campo en un índice.
Realice con cuidado este paso porque los atributos determinarán la expresión física de los campos del índice. Si desea cambiar los atributos más adelante, incluso mediante programación, casi siempre tendrá que quitar y recompilar el índice. Los atributos principales como Searchable y Retrievable tienen un impacto insignificante en el almacenamiento. La habilitación de filtros y el uso de proveedores de sugerencias aumentan los requisitos de almacenamiento.
Searchable permite la búsqueda de texto completo. Todos los campos utilizados en consultas de formato libre o en expresiones de consulta deben tener este atributo. Para cada campo que marque como Searchable, se crearán índices invertidos.
Retrievable devuelve el campo en los resultados de búsqueda. Todos los campos que proporcionan contenido a los resultados de búsqueda deben tener este atributo. Establecer este campo no afecta considerablemente al tamaño del índice.
Filterable permite que se haga referencia al campo en las expresiones de filtro. Cada campo utilizado en una expresión $filter debe tener este atributo. Las expresiones de filtro son para coincidencias exactas. Dado que las cadenas de texto permanecen intactas, se necesita más almacenamiento para dar cabida al contenido textual.
Facetable permite que el campo se use en la navegación con facetas. Solo los campos marcados también como Filterable pueden marcarse como Facetable.
Sortable permite que el campo se use en una ordenación. Cada campo utilizado en una expresión $Orderby debe tener este atributo.
¿Necesita análisis léxico? En el caso de los campos Edm.string que son Searchable, puede establecer un analizador si quiere indexación y consulta con un lenguaje mejorado.
La opción predeterminada es Estándar - Lucene, pero puede elegir Inglés - Microsoft si desea usar el analizador de Microsoft para procesamiento léxico avanzado, como para la resolución de formas verbales y sustantivos irregulares. Solo los analizadores de idiomas se pueden especificar en el portal. Si usa un analizador personalizado o uno que no sea de lenguaje, como palabra clave, patrón, etc., debe crearlo mediante programación. Para más información acerca de los analizadores, consulte Adición de analizadores de idiomas.
¿Necesita la funcionalidad de escritura anticipada en forma de autocompletar o de resultados sugeridos? Active la casilla Proveedor de sugerencias para habilitar las sugerencias de consultas de escritura anticipada y la función autocompletar en los campos seleccionados. Los proveedores de sugerencias se suman al número de términos con tokens en el índice y, por tanto, consumen más almacenamiento.
Configuración del indizador en el asistente
La última página del asistente recopila entradas de usuario para la configuración del indizador. Puede especificar una programación y establecer otras opciones que variarán según el tipo de origen de datos.
Internamente el asistente también configura las definiciones siguientes, que no están visibles en el indexador hasta después de su creación:
- Asignaciones de campos entre el origen de datos y el índice.
- Asignaciones de campos de salida entre la salida de la aptitud y un índice.
Pasos siguientes
La mejor manera de comprender las ventajas y limitaciones del asistente es recorrer sus pasos. En este inicio rápido se explica cada paso.