Cómo dar forma a los resultados en Azure AI Search
En este artículo se explica cómo trabajar con una respuesta de consulta en Azure AI Search. La estructura de una respuesta viene determinada por los parámetros de la propia consulta, como se describe en Buscar documentos (REST) o Clase SearchResults (Azure para .NET).
Los parámetros de la consulta determinan lo siguiente:
- Selección de campo
- Recuento de coincidencias encontradas en el índice de la consulta
- Paginación
- Número de resultados en la respuesta (hasta 50, de forma predeterminada)
- Criterio de ordenación
- Resaltado de términos dentro de un resultado, coincidencia con el término completo o parcial en el cuerpo del resultado
Redacción de los resultados
Los resultados son tabulares, compuestos por campos de todos los campos "recuperables" o limitados a solo los campos especificados en los $select parámetros. Las filas son los documentos coincidentes.
Puede elegir qué campos se encuentran en los resultados de la búsqueda. Aunque un documento de búsqueda puede tener un gran número de campos, normalmente solo se necesitan unos pocos para representar cada documento en los resultados. En una solicitud de consulta, anexe $select=<field list> para especificar qué campos "recuperables" deben aparecer en la respuesta.
Elija los campos que ofrecen contraste y diferenciación entre los documentos, proporcionando información suficiente para invitar a una respuesta click-through en la parte del usuario. En un sitio de comercio electrónico, puede tratarse del nombre de un producto, la descripción, la marca, el color, el tamaño, el precio y la clasificación. Para el índice de hotels-samples integrado, podrían ser los campos "select" en el ejemplo siguiente:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Sugerencias para resultados inesperados
En ocasiones, la salida de la consulta no es lo que espera ver. Por ejemplo,es posible que compruebe que algunos resultados parezcan ser duplicados, o bien que un resultado que debería aparecer junto a la parte superior aparezca más abajo. Cuando los resultados de la consulta no son los esperados, puede probar estas modificaciones en la consulta para ver si mejoran:
Cambie
searchMode=any(predeterminado) asearchMode=allpara requerir coincidencias en todos los criterios en lugar de en cualquiera de ellos. Esto sucede especialmente cuando se incluyen operadores booleanos en la consulta.Experimente con diferentes analizadores léxicos o personalizados para ver si cambia el resultado de la consulta. El analizador predeterminado divide las palabras con guiones y reduce las palabras a los formularios raíz, lo que normalmente mejora la solidez de una respuesta de consulta. Sin embargo, si necesita conservar los guiones o si las cadenas incluyen caracteres especiales, es posible que tenga que configurar analizadores personalizados para asegurarse de que el índice contenga los tokens en el formato correcto. Para más información, consulte Búsqueda de términos parciales y patrones con caracteres especiales (guiones, carácter comodín, expresión regular y patrones).
Recuento de coincidencias
El parámetro recuento devuelve el número de documentos del índice que se consideran una coincidencia para la consulta. Para devolver el recuento, agregue $count=true a la solicitud de consulta. El servicio de búsqueda no impone ningún valor máximo. Según la consulta y el contenido de los documentos, el recuento podría ser tan alto como todos los documentos del índice.
El recuento es preciso cuando el índice es estable. Si el sistema está agregando, actualizando o eliminando documentos activamente, el recuento es aproximado, excluyendo los documentos que no están totalmente indexados.
El recuento no se verá afectado por el mantenimiento rutinario ni por otras cargas de trabajo en el servicio de búsqueda. Sin embargo, si tiene varias particiones y una sola réplica, podría experimentar fluctuaciones a corto plazo en el recuento de documentos (varios minutos) a medida que se reinician las particiones.
Sugerencia
Para comprobar las operaciones de indexación, puede confirmar si el índice contiene el número esperado de documentos agregando $count=true en una consulta de búsqueda search=* vacía. El resultado es el recuento completo de documentos del índice.
Al probar la sintaxis de consulta, $count=true puede avisarle rápidamente si las modificaciones devuelven resultados mayores o menores, lo que puede ser útil para los comentarios.
Paginación de resultados
De forma predeterminada, el motor de búsqueda devuelve hasta las primeras 50 coincidencias. Las 50 primeras se determinan por puntuación de búsqueda, suponiendo que la consulta es una búsqueda de texto completo o una semántica. De lo contrario, los 50 principales son un orden arbitrario para las consultas de coincidencia exactas (donde "@searchScore=1.0" uniforme indica una clasificación arbitraria).
El límite superior es de 1000 documentos devueltos por página de resultados de búsqueda, por lo que puede establecer top para devolver hasta 1000 documentos en el primer resultado. En las API de versión preliminar más recientes, si usa una consulta híbrida, puede especificar maxTextRecallSize para devolver hasta 10 000 documentos.
Para controlar la paginación de todos los documentos devueltos en un conjunto de resultados, agregue $top y $skip parámetros a una solicitud GET o top y skip a una solicitud POST. En la lista siguiente se explica la lógica.
Devuelve el primer conjunto de 15 documentos coincidentes más un recuento total de coincidencias:
GET /indexes/<INDEX-NAME>/docs?search=<QUERY STRING>&$top=15&$skip=0&$count=true.Devuelve el segundo conjunto, omitiendo los 15 primeros para obtener los 15 siguientes:
$top=15&$skip=15. Repita para el tercer conjunto de 15:$top=15&$skip=30
No se garantiza que los resultados de las consultas paginadas sean estables si el índice subyacente cambia. La paginación cambia el valor de $skip para cada página, pero cada consulta es independiente y funciona en la vista actual de los datos tal como existen en el índice en el momento de la consulta (es decir, no se almacenan en caché ni se hacen instantáneas de los resultados, como los que se encuentran en una base de datos de uso general).
A continuación, encontrará un ejemplo de cómo podría obtener duplicados. Supongamos que tiene un índice con cuatro documentos:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Ahora supongamos que desea que los resultados se devuelvan dos a la vez, ordenados por calificación. Ejecutaría esta consulta para obtener la primera página de resultados: $top=2&$skip=0&$orderby=rating desc, lo que produce los siguientes resultados:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
En el servicio, suponga que se agrega un quinto documento al índice entre las llamadas de consulta: { "id": "5", "rating": 4 }. Poco después, ejecuta una consulta para capturar la segunda página: $top=2&$skip=2&$orderby=rating desc, y obtiene estos resultados:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Observe que el documento 2 se captura dos veces. Esto se debe a que el nuevo documento 5 tiene un valor mayor de calificación, por lo que se ordena antes del documento 2 y se sitúa en la primera página. Si bien este comportamiento podría ser inesperado, es típico de cómo se comporta un motor de búsqueda.
Paginación a través de un gran número de resultados
El uso de $top y $skip permite que una consulta de búsqueda pagine a través de 100 000 resultados. Pero ¿qué ocurre si los resultados son superiores a 100 000? Para paginar a través de una respuesta de este tamaño, use un criterio de ordenación y un filtro de rango como solución alternativa a $skip.
En esta solución alternativa, la ordenación y el filtro se aplican a un campo de identificador de documento o a otro campo que sea único para cada documento. El campo único debe tener la atribución filterable y sortable en el índice de búsqueda.
Emita una consulta para devolver una página completa de resultados ordenados.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Elija el último resultado devuelto por la consulta de búsqueda. Aquí se muestra un resultado de ejemplo con un valor de identificador.
{ "id": "50" }Use ese valor de identificación en una consulta de intervalo para capturar la siguiente página de resultados. Este campo Id. debe tener valores únicos; de lo contrario, la paginación podría incluir resultados duplicados.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }La paginación finaliza cuando la consulta devuelve cero resultados.
Nota:
Los atributos "filtrables" y "ordenables" solo se pueden habilitar cuando se agrega un campo por primera vez a un índice; no se pueden habilitar en un campo existente.
Ordenar resultados
En una consulta de búsqueda de texto completo, los resultados se pueden clasificar por:
- una puntuación de búsqueda
- una puntuación de cambio de puntuación semántico
- un criterio de ordenación en un campo "ordenable"
También puede aumentar las coincidencias encontradas en campos específicos agregando un perfil de puntuación.
Ordenación por puntuación de búsqueda
En el caso de las consultas de búsqueda de texto completo, los resultados se clasifican automáticamente mediante una puntuación de búsqueda, calculada en función de la frecuencia de los términos y la proximidad en un documento (se deriva de TF-IDF), donde los documentos con más coincidencias o con coincidencias más exactas de un término de búsqueda reciben las puntuaciones más altas.
El rango "@search.score" es ilimitado, o de 0 a (pero sin incluir) 1,00 en servicios más antiguos.
Para cualquiera de los algoritmos, un valor de "@search.score" igual a 1,00 indica un conjunto de resultados sin puntuar o sin clasificar, donde la puntuación 1,0 es uniforme en todos los resultados. Los resultados sin puntuar se producen cuando el formulario de consulta es una búsqueda aproximada, una consulta con caracteres comodín o expresión regular, o una búsqueda vacía (search=*). Si tiene que imponer una estructura de clasificación sobre los resultados sin puntuar, considere una expresión $orderby para lograr ese objetivo.
Ordenación por el cambio de puntuación semántico
Si usa clasificador semántico, "@search.rerankerScore" determina el criterio de ordenación de los resultados.
El intervalo "@search.rerankerScore" es de 1 a 4,00, donde una puntuación más alta indica una coincidencia semántica más fuerte.
Ordenación con $orderby
Si el orden coherente es un requisito de la aplicación, puede definir una expresión $orderby en un campo. Solo los campos que se indexan como «ordenables» se pueden usar para ordenar los resultados.
Entre los campos que se usan normalmente en $orderby se incluyen los de clasificación, fecha y ubicación. El filtrado por ubicación necesita que la expresión de filtro llame a la función geo.distance(), además del nombre del campo.
Los campos numéricos (Edm.Double, Edm.Int32, Edm.Int64) se clasifican en orden numérico (por ejemplo, 1, 2, 10, 11, 20).
Los campos de cadena (Edm.String, Edm.ComplexType subcampos) se clasifican en criterio de ordenación ASCII o criterio de ordenación Unicode, según el idioma.
El contenido numérico de los campos de cadena se ordena alfabéticamente (1, 10, 11, 2, 20).
Las cadenas en mayúsculas se ordenan antes que las minúsculas (APPLE, Apple, BANANA, Banana, apple, banana). Puede asignar un normalizador de texto para preprocesar el texto antes de la ordenación para cambiar este comportamiento. El uso del tokenizador en minúsculas en un campo no tiene ningún efecto en el comportamiento de ordenación porque Azure AI Search se ordena en una copia noanalyzed del campo.
Las cadenas que empiezan con diacríticos aparecen en último lugar (Äpfel, Öffnen, Üben).
Cómo aumentar la relevancia mediante un perfil de puntuación
Otro enfoque que promueve la coherencia del orden es el uso de un perfil de puntuación personalizado. Los perfiles de puntuación ofrecen mayor control sobre la clasificación de los elementos en los resultados de la búsqueda, con la capacidad de aumentar las coincidencias que se encuentran en campos específicos. La lógica de puntuación adicional puede ayudar a invalidar las diferencias menores entre las réplicas, ya que las puntuaciones de búsqueda de cada documento están más alejadas. Para este enfoque, se recomienda usar el algoritmo de clasificación.
Resaltado de referencias
El resaltado de referencias hace referencia al formato del texto (por ejemplo, negrita o resaltados en amarillo) que se aplica a los términos coincidentes en un resultado, lo que facilita la ubicación de las coincidencias. La opción de resaltado resulta útil para los campos de contenido más largos, como un campo de descripción, en el que la coincidencia no es evidente de inmediato.
Observe que el resaltado se aplica a términos concretos. No hay ninguna funcionalidad de resaltado para el contenido de un campo completo. Si desea resaltar sobre una frase, debe proporcionar los términos coincidentes (o frase) en una cadena de consulta entre comillas. Esta técnica se describe más adelante en esta sección.
Se proporcionan instrucciones de resaltado de referencias en la solicitud de consulta. Las consultas que desencadenan la expansión de consultas en el motor, como las búsquedas aproximadas y las de caracteres comodín, tienen una compatibilidad limitada con el resaltado de referencias.
Requisitos para el resaltado de líneas ejecutadas
- Los campos deben ser
Edm.StringoCollection(Edm.String) - Los campos deben tener atributos que se puedan buscar
Especificación del resaltado en la solicitud
Para devolver términos resaltados, incluya el parámetro "highlight" en la solicitud de consulta. El parámetro se establece en una lista de campos delimitada por comas.
De manera predeterminada, el marcado de formato es <em>, pero puede reemplazar la etiqueta mediante los parámetros highlightPreTag y highlightPostTag. El código cliente controla la respuesta (por ejemplo, la aplicación de una fuente en negrita o un fondo amarillo).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
De forma predeterminada, Azure AI Search devuelve hasta cinco elementos resaltados por campo. Puede ajustar este número si anexa un guión seguido de un entero. Por ejemplo, "highlight": "description-10" devuelve hasta 10 elementos resaltados sobre el contenido coincidente en el campo "description".
Resultados resaltados
Cuando se agrega resaltado a la consulta, la respuesta incluye "@search.highlights" para cada resultado, a fin de que el código de la aplicación se pueda destinar a esa estructura. La lista de campos especificados para "highlight" se incluyen en la respuesta.
En una búsqueda de palabras clave, se examina cada término de forma independiente. Una consulta para "secretos divinos" devuelve coincidencias en cualquier documento que contenga cualquiera de los términos.
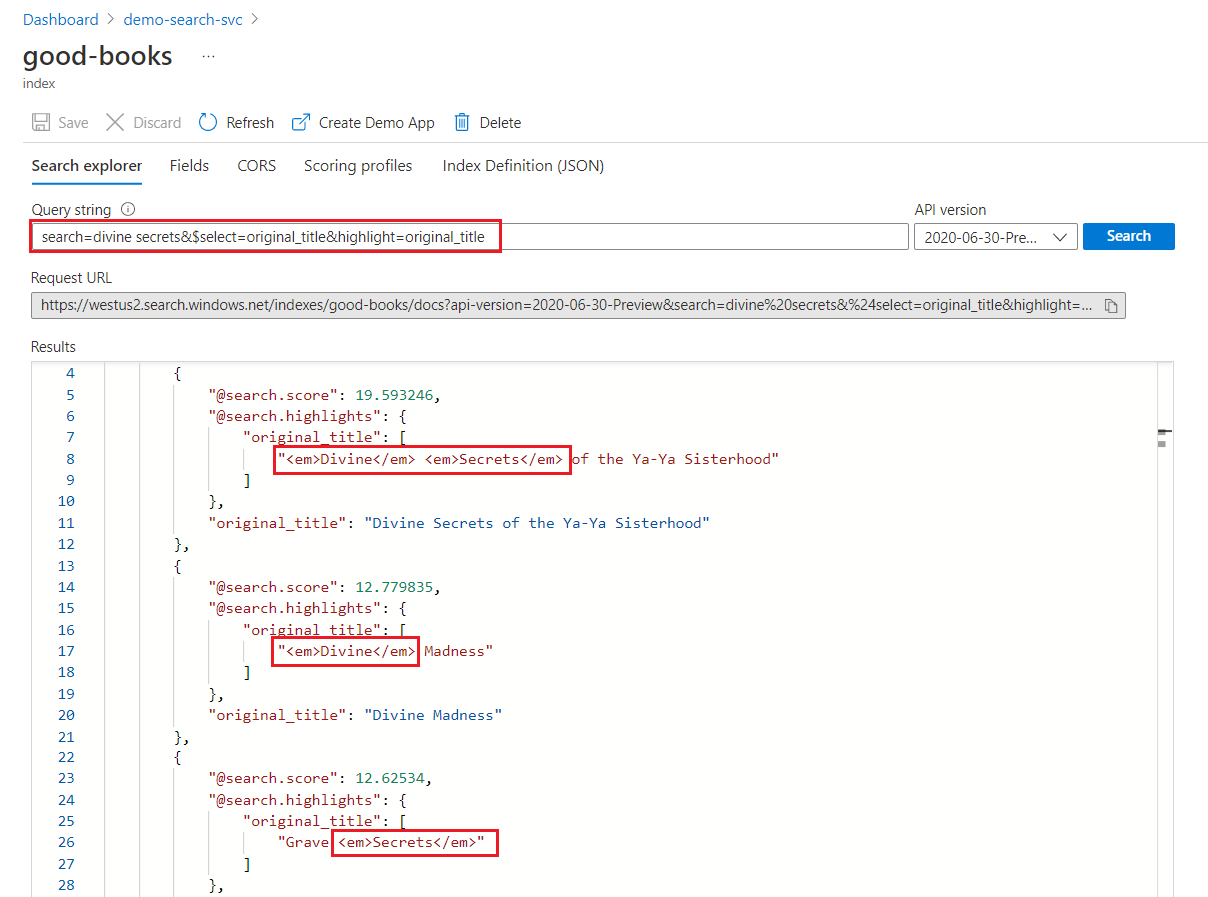
Resaltado de búsqueda de palabras clave
En un campo resaltado, el formato se aplica a términos completos. Por ejemplo, en una coincidencia de "The Divine Secrets of the Ya-Ya Sisterhood", el formato se aplica a cada término de forma independiente, aunque sean consecutivos.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Resaltado de frases de búsqueda
El formato de término completo se aplica incluso en una búsqueda de frases, donde cada término se incluye entre comillas dobles. El ejemplo siguiente es la misma consulta, a excepción de que "secretos divinos" se envía como una frase entre comillas (en algunos clientes de REST es necesario aplicar escape a las comillas internas mediante una barra invertida \"):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Dado que los criterios ahora tienen ambos términos, solo se encuentra una coincidencia en el índice de búsqueda. La respuesta a la consulta anterior tiene este aspecto:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Resaltado de frases en servicios antiguos
Los servicios de búsqueda creados antes del 15 de julio de 2020 implementan otra experiencia de resaltado para las consultas de frases.
Para los ejemplos siguientes, imagine una cadena de consulta que incluya la frase entre comillas "super bowl". Antes de julio de 2020, se resalta cualquier término de la frase:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Para los servicios de búsqueda creados después de julio de 2020, solo las frases que coincidan con la consulta de frase completa se devolverán en "@search.highlights":
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Pasos siguientes
Para generar rápidamente una página de búsqueda para el cliente, tenga en cuenta estas opciones:
La aplicación de demostración Create, en el portal, crea una página HTML con una barra de búsqueda, navegación por facetas y un área de resultados que incluye imágenes.
Agregación de una búsqueda a una aplicación de ASP.NET Core (MVC) es un tutorial y un ejemplo de código que compila un cliente funcional.
Adición de búsqueda a aplicaciones web es un tutorial y un ejemplo de código en el que se usan bibliotecas React de JavaScript para la experiencia del usuario. La aplicación se implementa mediante Azure Static Web Apps.