Minimización de los problemas de SQL para migraciones de Oracle
Este artículo es la quinta parte de una serie de siete partes, que proporciona instrucciones sobre cómo migrar de Oracle a Azure Synapse Analytics. Este artículo se centra en los procedimientos recomendados para minimizar los problemas de SQL.
Información general
Características de los entornos de Oracle
El producto de base de datos inicial de Oracle, publicado en 1979, era una base de datos relacional SQL comercial para aplicaciones de procesamiento de transacciones en línea (OLTP), con velocidades de transacción mucho más bajas que hoy en día. Desde esa versión inicial, el entorno de Oracle ha evolucionado para convertirse en mucho más complejo y abarca numerosas características. Las características incluyen arquitecturas cliente-servidor, bases de datos distribuidas, procesamiento paralelo, análisis de datos, alta disponibilidad, almacenamiento de datos, técnicas de datos en memoria y compatibilidad con instancias basadas en la nube.
Sugerencia
Oracle introdujo por primera vez el concepto de "dispositivo de almacenamiento de datos" a principios de los años 2000.
Debido al costo y la complejidad de mantener y actualizar entornos de Oracle locales heredados, muchos usuarios existentes de Oracle desean aprovechar las innovaciones proporcionadas por los entornos de nube. Los entornos de nube modernos, como la nube, IaaS y PaaS, permiten delegar tareas como el mantenimiento de la infraestructura y el desarrollo de plataformas en el proveedor de nube.
Muchos almacenamientos de datos que admiten consultas SQL analíticas complejas en grandes volúmenes de datos usan tecnologías de Oracle. Estos almacenamientos de datos suelen tener un modelo de datos dimensional, como esquemas en estrella o de copo de nieve, y usan data marts para los departamentos individuales.
Sugerencia
Muchas de las instalaciones existentes de Oracle son almacenamientos de datos que usan un modelo de datos dimensional.
La combinación de modelos de datos dimensionales y SQL de Oracle simplifica la migración a Azure Synapse, ya que los conceptos básicos de modelo de datos y SQL se pueden transferir. Microsoft recomienda mover el modelo de datos existente tal cual está a Azure para reducir el riesgo, el esfuerzo y el tiempo de migración. Aunque el plan de migración puede incluir un cambio en el modelo de datos subyacente, como un traslado de un modelo Inmon a un almacén de datos, tiene sentido realizar inicialmente una migración tal cual está. Después de la migración inicial, puede realizar cambios en el entorno de nube de Azure para aprovechar sus ventajas de rendimiento, escalabilidad elástica, características integradas y ventajas de costos.
Aunque el lenguaje SQL está estandarizado, los proveedores individuales a veces implementan extensiones propietarias. Como resultado, es posible que encuentre diferencias de SQL durante la migración que requieren soluciones alternativas en Azure Synapse.
Uso de las utilidades de Azure para implementar una migración controlada por metadatos
Puede automatizar y orquestar el proceso de migración mediante las funcionalidades del entorno de Azure. Este enfoque minimiza el impacto en el rendimiento en el entorno de Oracle existente, que es posible que ya funcione casi a plena capacidad.
Azure Data Factory es un servicio de integración de datos basado en la nube que permite crear flujos de trabajo basados en datos en la nube a fin de orquestar y automatizar el movimiento y la transformación de los datos. Con Azure Data Factory puede crear y programar flujos de trabajo basados en datos (canalizaciones) que ingieren datos de distintos almacenes de datos. Data Factory puede procesar y transformar datos mediante servicios de proceso, como Azure HDInsight Hadoop, Spark, Azure Data Lake Analytics y Azure Machine Learning.
Azure también incluye Azure Database Migration Service para ayudarle a planear y realizar una migración desde entornos como Oracle. SQL Server Migration Assistant (SSMA) para Oracle puede automatizar la migración de bases de datos de Oracle, incluidos, en algunos casos, el código de las funciones y los procedimientos.
Sugerencia
Automatice el proceso de migración con las funcionalidades de Azure Data Factory.
Cuando planee usar las utilidades de Azure, como Data Factory, para administrar el proceso de migración, cree primero metadatos que enumeren todas las tablas de datos que se deben migrar y su ubicación.
Diferencias de DDL de SQL entre Oracle y Azure Synapse
El estándar ANSI SQL define la sintaxis básica para los comandos DDL (Lenguaje de definición de datos). Algunos comandos DDL, como CREATE TABLE y CREATE VIEW, son comunes tanto a Oracle como a Azure Synapse, pero se han ampliado para proporcionar características específicas de la implementación, como la indexación, la distribución de tablas y las opciones de creación de particiones.
Sugerencia
Los comandos DDL CREATE TABLE y CREATE VIEW de SQL tienen elementos principales estándar, pero también se usan para definir opciones específicas de la implementación.
En las secciones siguientes, se describen las opciones específicas de Oracle que se deben tener en cuenta durante una migración a Azure Synapse.
Consideraciones sobre tablas y vistas
Al migrar tablas entre distintos entornos, normalmente solo se migran físicamente los datos sin procesar y los metadatos que los describen. Otros elementos de base de datos del sistema de origen, como los índices y los archivos de registro, normalmente no se migran porque podrían ser innecesarios o estar implementados de forma diferente en el nuevo entorno. Por ejemplo, la opción TEMPORARY en la sintaxis de CREATE TABLE de Oracle equivale a anteponer el nombre de la tabla con el carácter # como prefijo en Azure Synapse.
Las optimizaciones de rendimiento en el entorno de origen, como los índices, indican dónde puede agregar la optimización del rendimiento en el nuevo entorno de destino. Por ejemplo, si las consultas del entorno de Oracle de origen usan con frecuencia índices de mapa de bits, puede indicar que se debe crear un índice no agrupado en Azure Synapse. Otras técnicas de optimización del rendimiento nativas, como la replicación de tablas, pueden ser más adecuadas que la creación directa de un índice equivalente (igual por igual). SSMA para Oracle puede proporcionar recomendaciones de migración para la distribución y la indexación de tablas.
Sugerencia
Los índices que ya existen indican candidatos para la indexación en el almacenamiento migrado.
Las definiciones de vista SQL contienen instrucciones DML (Lenguaje de manipulación de datos) de SQL que definen la vista, normalmente con una o varias instrucciones SELECT. Al migrar instrucciones CREATE VIEW, tenga en cuenta las diferencias de DML entre Oracle y Azure Synapse.
Tipos de objetos de base de datos de Oracle no admitidos
A menudo, las características específicas de Oracle se pueden reemplazar por características de Azure Synapse. Sin embargo, algunos objetos de base de datos de Oracle no se admiten directamente en Azure Synapse. En la siguiente lista de objetos de base de datos de Oracle no admitidos, se describe cómo se puede lograr una funcionalidad equivalente en Azure Synapse:
Opciones de indexación: en Oracle, varias opciones de indexación, como los índices de mapa de bits, los índices basados en funciones y los índices de dominio, no tienen ningún equivalente directo en Azure Synapse. Aunque Azure Synapse no admite esos tipos de índice, puede lograr una reducción similar en la E/S de disco mediante el uso de tipos de índice definidos por el usuario o la creación de particiones. La reducción de la E/S de disco mejora el rendimiento de las consultas.
Puede averiguar qué columnas están indexadas y su tipo de índice consultando las tablas y vistas del catálogo del sistema, como
ALL_INDEXES,DBA_INDEXES,USER_INDEXESyDBA_IND_COL. O bien, puede consultar las vistasdba_index_usageov$object_usagecuando la supervisión está habilitada.Con las características de Azure Synapse, como el procesamiento paralelo de consultas y el almacenamiento en caché en memoria de los datos y los resultados, es probable que se necesiten menos índices para que las aplicaciones de almacenamiento de datos logren excelentes objetivos de rendimiento.
Tablas agrupadas: las tablas de Oracle se pueden organizar para que las filas de la tabla a las que se accede con frecuencia (en función de un valor común) se almacenen físicamente juntas. Esta estrategia reduce la E/S de disco cuando se recuperan los datos. Oracle también tiene una opción de agrupación con hash para tablas individuales, que aplica un valor hash a la clave del clúster y almacena físicamente juntas las filas con el mismo valor hash.
En Azure Synapse, se puede conseguir un resultado similar mediante la creación de particiones y el uso de otros índices.
Vistas materializadas: Oracle admite vistas materializadas y recomienda una o varias de estas vistas en tablas grandes que tengan muchas columnas si solo algunas columnas se usan con frecuencia en las consultas. El sistema actualiza las vistas materializadas automáticamente cuando se actualizan los datos de la tabla base.
En 2019, Microsoft anunció que Azure Synapse admitirá vistas materializadas con la misma funcionalidad que Oracle. Las vistas materializadas ahora son una característica en versión preliminar en Azure Synapse.
Desencadenadores en la base de datos: en Oracle, se puede configurar un desencadenador para que se ejecute automáticamente cuando se produce un evento desencadenador. Los eventos desencadenadores pueden ser:
Se ejecuta una instrucción DML, como
INSERT,UPDATEoDELETE. Si ha definido un desencadenador que se activa antes de una instrucciónINSERTen una tabla de cliente, el desencadenador se activará una vez antes de insertar una nueva fila en la tabla del cliente.Se ejecuta una instrucción DDL, como
CREATEoALTER. Este evento desencadenador se suele usar para registrar los cambios de esquema con fines de auditoría.Un evento del sistema, como el inicio o apagado de la base de datos de Oracle.
Un evento de usuario, como inicio de sesión o cierre de sesión.
Azure Synapse no admite desencadenadores de base de datos de Oracle. Sin embargo, puede lograr una funcionalidad equivalente mediante Data Factory, aunque si lo hace, tendrá que refactorizar los procesos que usan desencadenadores.
Sinónimos: Oracle admite la definición de sinónimos como nombres alternativos para varios tipos de objetos de base de datos. Estos tipos incluyen tablas, vistas, secuencias, procedimientos, funciones almacenadas, paquetes, vistas materializadas, objetos de esquema de clase de Java, objetos definidos por el usuario u otros sinónimos.
Azure Synapse no admite actualmente la definición de sinónimos, aunque si un sinónimo de Oracle hace referencia a una tabla o vista, puede definir una vista en Azure Synapse para que coincida con el nombre alternativo. Si un sinónimo de Oracle hace referencia a una función o procedimiento almacenado, puede reemplazar el sinónimo en Azure Synapse por otra función o procedimiento almacenado que llame al destino.
Tipos definidos por el usuario: Oracle admite objetos definidos por el usuario que pueden contener una serie de campos individuales, cada uno con su propia definición y valores predeterminados. A continuación, se puede hacer referencia a esos objetos dentro de una definición de tabla de la misma manera que los tipos de datos integrados, como
NUMBERoVARCHAR.Azure Synapse no admite actualmente tipos definidos por el usuario. Si los datos que tiene que migrar incluyen tipos de datos definidos por el usuario, puede "aplanarlos" en una definición de tabla convencional o, si son matrices de datos, normalizarlos en una tabla independiente.
Generación de DDL de SQL
Puede editar los scripts con CREATE TABLE y CREATE VIEW de Oracle existentes para lograr definiciones equivalentes en Azure Synapse. Para ello, es posible que tenga que usar tipos de datos modificados y quitar o modificar cláusulas específicas de Oracle, como TABLESPACE.
Sugerencia
Use los metadatos de Oracle existentes para automatizar la generación de instrucciones DDL CREATE TABLE y CREATE VIEW para Azure Synapse.
En el entorno de Oracle, las tablas del catálogo del sistema especifican la definición de vista y tabla actual. A diferencia de la documentación mantenida por el usuario, la información del catálogo del sistema siempre está completa y sincronizada con las definiciones de tabla actuales. Puede acceder a la información del catálogo del sistema mediante utilidades como Oracle SQL Developer. Oracle SQL Developer puede generar instrucciones DDL CREATE TABLE que puede editar para su aplicación en tablas equivalentes en Azure Synapse, como se muestra en la siguiente captura de pantalla.

Oracle SQL Developer genera la siguiente instrucción CREATE TABLE, que contiene cláusulas específicas de Oracle que debe quitar. Asigne los tipos de datos no admitidos antes de ejecutar la instrucción CREATE TABLE modificada en Azure Synapse.
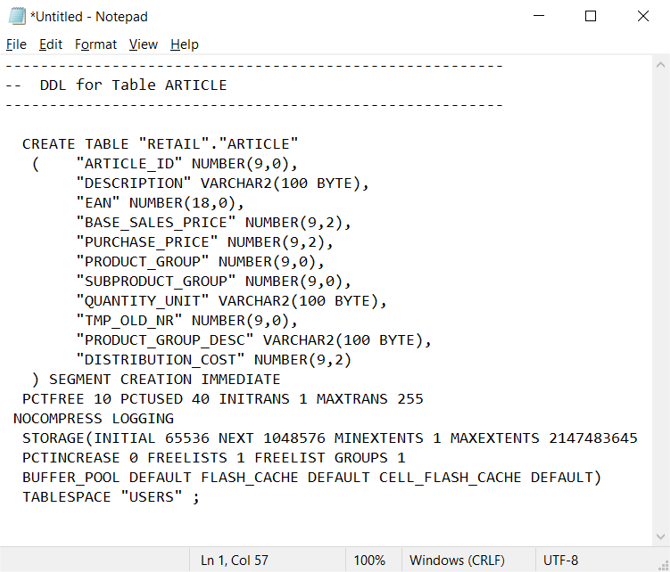
Como alternativa, puede generar automáticamente instrucciones CREATE TABLE a partir de la información de las tablas del catálogo de Oracle mediante consultas SQL, SSMA o herramientas de migración de terceros. Este enfoque es la manera más rápida y coherente de generar instrucciones CREATE TABLE para muchas tablas.
Sugerencia
Herramientas y servicios de terceros pueden automatizar las tareas de asignación de datos.
Hay proveedores de terceros que ofrecen herramientas y servicios para automatizar la migración, incluida la asignación de tipos de datos. Si ya se utiliza una herramienta de ETL de terceros en el entorno de Oracle, utilice dicha herramienta para implementar cualquier transformación de datos necesaria.
Diferencias de DML de SQL entre Oracle y Azure Synapse
El estándar ANSI SQL define la sintaxis básica para los comandos DML, como SELECT, INSERT, UPDATE y DELETE. Aunque Oracle y Azure Synapse admiten comandos DDL, en algunos casos implementan el mismo comando de forma diferente.
Sugerencia
Los comandos DML de SQL estándar SELECT, INSERT y UPDATE pueden tener opciones de sintaxis adicionales en distintos entornos de base de datos.
En las secciones siguientes, se describen los comandos DML específicos de Oracle que se deben tener en cuenta durante una migración a Azure Synapse.
Diferencias de sintaxis de DML de SQL
Hay algunas diferencias de sintaxis de DML de SQL entre Oracle SQL y Azure Synapse T-SQL:
Tabla
DUAL: Oracle tiene una tabla del sistema llamadaDUALque consta de exactamente una columna llamadadummyy un registro con el valorX. La tablaDUALdel sistema se usa cuando una consulta requiere un nombre de tabla por motivos de sintaxis, pero el contenido de la tabla no es necesario.Una consulta de Oracle de ejemplo que usa la tabla
DUALesSELECT sysdate from dual;. El equivalente en Azure Synapse esSELECT GETDATE();. Para simplificar la migración de DML, puede crear una tablaDUALequivalente en Azure Synapse mediante la siguiente instrucción DDL.CREATE TABLE DUAL ( DUMMY VARCHAR(1) ) GO INSERT INTO DUAL (DUMMY) VALUES ('X') GOValores
NULL: un valorNULLen Oracle es una cadena vacía, representada por un tipo de cadenaCHARoVARCHARde longitud0. En Azure Synapse y la mayoría de las demás bases de datos,NULLsignifica otra cosa. Tenga cuidado al migrar datos, o al migrar procesos que controlan o almacenan datos, para asegurarse de que los valoresNULLse controlen de forma coherente.Sintaxis de combinación externa de Oracle: aunque las versiones más recientes de Oracle admiten la sintaxis de combinación externa ANSI, los sistemas de Oracle antiguos usan una sintaxis propietaria para las combinaciones externas que usan un signo más (
+) dentro de la instrucción SQL. Si va a migrar un entorno de Oracle más antiguo, es posible que encuentre la sintaxis anterior. Por ejemplo:SELECT d.deptno, e.job FROM dept d, emp e WHERE d.deptno = e.deptno (+) AND e.job (+) = 'CLERK' GROUP BY d.deptno, e.job;La sintaxis estándar ANSI equivalente es:
SELECT d.deptno, e.job FROM dept d LEFT OUTER JOIN emp e ON d.deptno = e.deptno and e.job = 'CLERK' GROUP BY d.deptno, e.job ORDER BY d.deptno, e.job;Datos de tipo
DATE: en Oracle, el tipo de datosDATEpuede almacenar la fecha y la hora. Azure Synapse almacena la fecha y hora en los tipos de datos independientesDATE,TIMEyDATETIME. Al migrar columnasDATEde Oracle, compruebe si almacenan fecha y hora o solo una fecha. Si solo almacenan una fecha, asigne la columna al tipoDATE, de lo contrario, al tipoDATETIME.Aritmética del tipo
DATE: Oracle admite restar una fecha de otra, por ejemplo,SELECT date '2018-12-31' - date '2018-1201' from dual;. En Azure Synapse, puede restar fechas mediante la funciónDATEDIFF(), por ejemplo,SELECT DATEDIFF(day, '2018-12-01', '2018-12-31');.Oracle puede restar enteros de fechas, por ejemplo,
SELECT hire_date, (hire_date-1) FROM employees;. En Azure Synapse, puede agregar o restar enteros de fechas mediante la funciónDATEADD().Actualizaciones mediante vistas: en Oracle, puede ejecutar operaciones de inserción, actualización y eliminación en una vista para actualizar la tabla subyacente. En Azure Synapse, esas operaciones se ejecutan en una tabla base, no en una vista. Es posible que tenga que volver a diseñar el procesamiento de ETL si se actualiza una tabla de Oracle mediante una vista.
Funciones integradas: en la tabla siguiente, se muestran las diferencias en la sintaxis y el uso de algunas funciones integradas.
| Función de Oracle | Descripción | Equivalente en Synapse |
|---|---|---|
| ADD_MONTHS | Agregar el número de meses especificado | DATEADD |
| CAST | Convertir un tipo de datos integrado en otro | CAST |
| DECODE | Evaluar una lista de condiciones | CASE, expresión |
| EMPTY_BLOB | Crear un valor de BLOB vacío | Constante 0x (cadena binaria vacía) |
| EMPTY_CLOB | Crear un valor de CLOB o NCLOB vacío | '' (cadena vacía) |
| INITCAP | Poner en mayúsculas la primera letra de cada palabra | Función definida por el usuario |
| INSTR | Buscar la posición de una subcadena en una cadena | CHARINDEX |
| LAST_DAY | Obtener la última fecha del mes | EOMONTH |
| LENGTH | Obtener la longitud de una cadena en caracteres | LEN |
| LPAD | Rellenar por la izquierda una cadena hasta la longitud especificada | Expresión que usa REPLICATE, RIGHT y LEFT |
| MOD | Obtener el resto de una división de un número por otro | Operador % |
| MONTHS_BETWEEN | Obtener el número de meses entre dos fechas | DATEDIFF |
| NVL | Reemplazar NULL por una expresión |
ISNULL |
| SUBSTR | Devolver una subcadena de una cadena | SUBSTRING |
| TO_CHAR para datetime | Convertir un valor datetime en una cadena | CONVERT |
| TO_DATE | Convertir una cadena en un valor datetime | CONVERT |
| TRANSLATE | Sustitución de caracteres únicos de uno a uno | Expresiones que usan REPLACE o una función definida por el usuario |
| TRIM | Recortar los caracteres iniciales o finales | LTRIM y RTRIM |
| TRUNC para datetime | Truncar un valor datetime | Expresiones que usan CONVERT |
| UNISTR | Convertir puntos de código Unicode en caracteres | Expresiones que usan NCHAR |
Funciones, procedimientos almacenados y secuencias
Al migrar un almacenamiento de datos de un entorno consolidado como Oracle, probablemente tenga que migrar elementos que no sean tablas y vistas simples. En el caso de funciones, procedimientos almacenados y secuencias, compruebe si las herramientas del entorno de Azure pueden reemplazar su funcionalidad, ya que normalmente es más eficaz usar herramientas integradas de Azure que volver a codificar las funciones de Oracle.
Como parte de la fase de preparación, cree un inventario de objetos que se deban migrar, defina un método para controlarlos y asigne los recursos adecuados en el plan de migración.
Las herramientas de Microsoft, como SSMA para Oracle y Azure Database Migration Service, o los servicios y productos de migración de terceros, pueden automatizar la migración de funciones, procedimientos almacenados y secuencias.
Sugerencia
Los productos y servicios de terceros pueden automatizar la migración de elementos que no son datos.
En las secciones siguientes, se describe la migración de funciones, procedimientos almacenados y secuencias.
Functions
Al igual que en la mayoría de los productos de base de datos, Oracle admite funciones del sistema y funciones definidas por el usuario en una implementación de SQL. Al migrar una plataforma de base de datos heredada a Azure Synapse, las funciones comunes del sistema normalmente se pueden migrar sin cambios. Algunas funciones del sistema pueden tener una sintaxis ligeramente diferente, pero se pueden automatizar los cambios necesarios.
En el caso de las funciones del sistema de Oracle o funciones arbitrarias definidas por el usuario que no tienen ningún equivalente en Azure Synapse, vuelva a codificar esas funciones mediante el lenguaje del entorno de destino. El código de las funciones definidas por el usuario de Oracle se crea en PL/SQL, Java o C. Azure Synapse usa el lenguaje Transact-SQL para implementar las funciones definidas por el usuario.
Procedimientos almacenados
La mayoría de los productos de base de datos modernos permite almacenar los procedimientos en la base de datos. Oracle proporciona el lenguaje PL/SQL para este fin. Normalmente, un procedimiento almacenado contiene instrucciones SQL y lógica de procedimiento, y puede devolver datos o un estado.
Azure Synapse admite procedimientos almacenados mediante T-SQL, por lo que debe volver a codificar los procedimientos almacenados migrados en T-SQL.
Secuencias
En Oracle, una secuencia es un objeto de base de datos con nombre creado con CREATE SEQUENCE. Una secuencia proporciona valores numéricos únicos mediante los métodos CURRVAL y NEXTVAL. Puede usar los números únicos generados como valores de clave suplente para las claves principales. Azure Synapse no implementa CREATE SEQUENCE, pero puede implementar secuencias mediante columnas IDENTITY o código SQL que genera el siguiente número de secuencia de una serie.
Uso de EXPLAIN para validar SQL heredado
Sugerencia
Use consultas reales de los registros de consultas del sistema para buscar posibles problemas de migración.
Suponiendo un modelo de datos migrado tal cual en Azure Synapse con los mismos nombres de tablas y columnas, una manera de probar la compatibilidad de Oracle SQL heredado con Azure Synapse es:
- Capture algunas instrucciones SQL representativas desde los registros del historial de consultas del sistema heredado.
- Anteponga la instrucción
EXPLAINcomo prefijo de esas consultas. - Ejecute las instrucciones
EXPLAINen Azure Synapse.
Cualquier código SQL incompatible producirá un error y la información de los errores se puede usar para determinar la escala de la tarea de programarlo de nuevo. Este enfoque no requiere que cargue ningún dato en el entorno de Azure; solo es necesario crear las tablas y vistas pertinentes.
Resumen
Las instalaciones de Oracle heredadas existentes normalmente están implementadas de forma que la migración a Azure Synapse resulta relativamente sencilla. Ambos entornos utilizan SQL para las consultas analíticas en grandes volúmenes de datos y generalmente usan algún tipo de modelo de datos dimensional. Estos factores hacen que las instalaciones de Oracle sean un buen candidato para la migración a Azure Synapse.
En resumen, nuestras recomendaciones para minimizar la tarea de migrar código SQL de Oracle a Azure Synapse son:
Migre el modelo de datos existente tal cual está para minimizar el riesgo, el esfuerzo y el tiempo de migración, incluso si se planea un modelo de datos diferente, como un almacén de datos.
Comprenda las diferencias entre la implementación de SQL de Oracle y la implementación de Azure Synapse.
Utilice los metadatos y los registros de consultas de la implementación de Oracle existente para evaluar el impacto del cambio de entorno. Planee un enfoque para mitigar las diferencias.
Automatice el proceso de migración para minimizar el riesgo, el esfuerzo y el tiempo de migración. Puede usar herramientas de Microsoft como Azure Database Migration Service y SSMA.
Considere la posibilidad de usar servicios y herramientas especializados de terceros para simplificar la migración.
Pasos siguientes
Para obtener más información sobre herramientas de Microsoft y de terceros, consulte el siguiente artículo de esta serie: Herramientas para la migración del almacenamiento de datos de Oracle a Azure Synapse Analytics.