Utilización de un cuaderno para cargar datos en un almacén de lago
En este tutorial, aprenderá a leer y escribir datos en el almacén de lago de Fabric con ayuda de un cuaderno. Fabric admite la API de Spark y la API de Pandas para lograr este objetivo.
Cargar datos con una API de Apache Spark
En la celda de código del cuaderno, use el ejemplo de código siguiente para leer datos del origen y cargarlos en Archivos, Tablas o ambas secciones del lago de datos.
Para especificar la ubicación desde la que se va a leer, puede usar la ruta de acceso relativa si los datos proceden del almacén de lago predeterminado del cuaderno actual. O bien, si los datos proceden de otro almacén de lago, puede usar la ruta de acceso Azure Blob File System (ABFS) absoluta. Copie esta ruta de acceso desde el menú contextual de los datos.
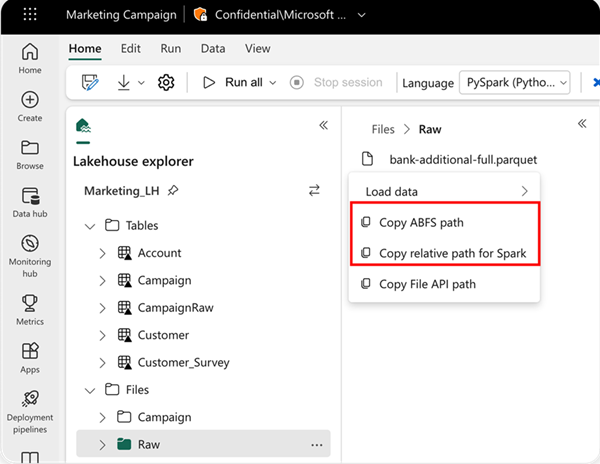
Copiar la ruta de acceso de ABFS: esta opción devuelve la ruta de acceso absoluta del archivo.
Copiar la ruta de acceso relativa para Spark: esta opción devuelve la ruta de acceso relativa del archivo en el almacén de lago predeterminado.
df = spark.read.parquet("location to read from")
# Keep it if you want to save dataframe as CSV files to Files section of the default lakehouse
df.write.mode("overwrite").format("csv").save("Files/ " + csv_table_name)
# Keep it if you want to save dataframe as Parquet files to Files section of the default lakehouse
df.write.mode("overwrite").format("parquet").save("Files/" + parquet_table_name)
# Keep it if you want to save dataframe as a delta lake, parquet table to Tables section of the default lakehouse
df.write.mode("overwrite").format("delta").saveAsTable(delta_table_name)
# Keep it if you want to save the dataframe as a delta lake, appending the data to an existing table
df.write.mode("append").format("delta").saveAsTable(delta_table_name)
Cargar datos con una API Pandas
Para admitir la API Pandas, el almacén de lago predeterminado se montará automáticamente en el cuaderno. El punto de montaje es "/lakehouse/default/". Puede usar este punto de montaje para leer y escribir datos desde o hacia el lago de datos predeterminado. La opción "Copiar ruta de acceso de la API de archivo" del menú contextual devolverá la ruta de acceso de la API de archivo desde ese punto de montaje. La ruta de acceso devuelta desde la opción Copiar ruta de acceso ABFS también funciona para la API Pandas.
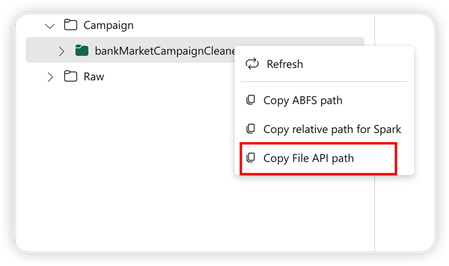
Copiar ruta de acceso de la API de archivo: esta opción devuelve la ruta de acceso bajo el punto de montaje del almacén de lago predeterminado.
# Keep it if you want to read parquet file with Pandas from the default lakehouse mount point
import pandas as pd
df = pd.read_parquet("/lakehouse/default/Files/sample.parquet")
# Keep it if you want to read parquet file with Pandas from the absolute abfss path
import pandas as pd
df = pd.read_parquet("abfss://DevExpBuildDemo@msit-onelake.dfs.fabric.microsoft.com/Marketing_LH.Lakehouse/Files/sample.parquet")
Sugerencia
En el caso de la API Spark, use la opción Copiar ruta de acceso ABFS o Copiar ruta de acceso relativa para Spark para obtener la ruta de acceso del archivo. Para la API Pandas, use la opción Copiar la ruta de acceso ABFS o Copiar la ruta de acceso de la API de archivo para obtener la ruta de acceso del archivo.
La manera más rápida de hacer funcionar el código para trabajar con la API Spark o la API Pandas es usar la opción Cargar datos y seleccionar la API que quiere usar. El código se generará automáticamente en una nueva celda de código del cuaderno.
