Migración de grupos de Spark de Azure Synapse a Fabric
Mientras que Azure Synapse ofrece grupos de Spark, Fabric ofrece grupos de inicio y grupos personalizados. El grupo de inicio puede ser una buena opción si tiene un único grupo sin configuraciones ni bibliotecas personalizadas en Azure Synapse y si el tamaño de nodo medio cumple sus requisitos. Sin embargo, si busca más flexibilidad con las configuraciones del grupo de Spark, se recomienda usar grupos personalizados. Aquí hay dos opciones:
- Opción 1: mueva el grupo de Spark al grupo predeterminado de un área de trabajo.
- Opción 2: mueva el grupo de Spark a un entorno personalizado de Fabric.
Si tiene varios grupos de Spark y planea moverlos a la misma área de trabajo de Fabric, se recomienda utilizar la opción 2 y crear varios entornos y grupos personalizados.
Para más información sobre los grupos de Spark, consulte las diferencias entre Azure Synapse Spark y Fabric.
Requisitos previos
Si aún no tiene una, cree un área de trabajo de Fabric en el inquilino.
Opción 1: desde un grupo de Spark al grupo predeterminado de un área de trabajo
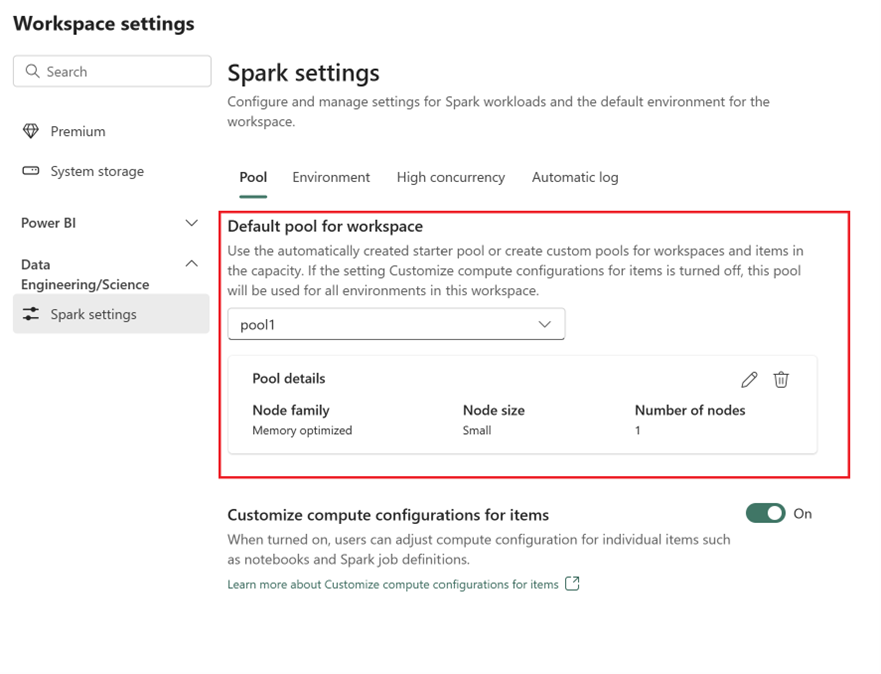
Puede crear un grupo de Spark personalizado desde su área de trabajo de Fabric y utilizarlo como grupo predeterminado en el área de trabajo. El grupo predeterminado lo usan todos los cuadernos y definiciones de trabajo de Spark de la misma área de trabajo.
Para mover un grupo de Spark existente de Azure Synapse a un grupo predeterminado de un área de trabajo:
- Acceder al área de trabajo de Azure Synapse: inicie sesión en Azure. Vaya al área de trabajo de Apache Synapse, luego a Grupos de Analytics y seleccione Grupos de Apache Spark.
- Buscar el grupo de Spark: en los grupos de Apache Spark, busque el grupo de Spark que desea mover a Fabric y compruebe las propiedades del grupo.
- Obtener propiedades: obtenga las propiedades del grupo de Spark, como la versión de Apache Spark, la familia del tamaño de los nodos, el tamaño de los nodos o la escalabilidad automática. Para ver las diferencias, consulte las consideraciones sobre los grupos de Spark.
- Crear un grupos de Spark personalizado en Fabric:
- Vaya al área de trabajo Fabric y seleccione Configuración del área de trabajo.
- Vaya a Ingeniería de datos/ciencia y seleccione Configuración de Spark.
- Seleccione la pestaña Grupo y en la sección Grupo predeterminado del área de trabajo, expanda el menú desplegable u seleccione Crear grupo.
- Cree su grupo personalizado con los valores de destino correspondientes. Rellene las opciones de nombre, familia de los nodos, tamaño de los nodos, escalado automático y asignación dinámica del ejecutor.
- Seleccionar una versión del runtime:
- Vaya a la pestaña Entorno y seleccione la versión del runtime requerida. Vea aquí los runtimes disponibles.
- Deshabilite la opción Establecer entorno predeterminado.
Nota:
En esta opción, no se admiten las bibliotecas o las configuraciones de nivel de grupo. Sin embargo, puede ajustar la configuración del proceso de los elementos individuales, como cuadernos y definiciones de trabajos de Spark, y agregar bibliotecas insertadas. Si necesita agregar configuraciones y bibliotecas personalizadas a un entorno, considere la posibilidad de usar un entorno personalizado.
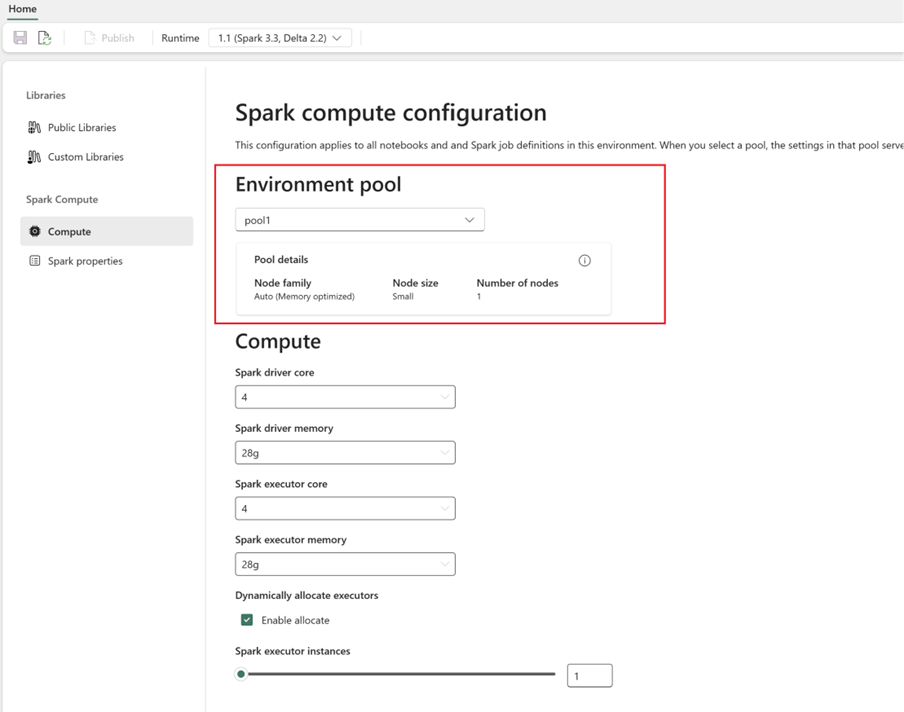
Opción 2: desde un grupo de Spark a un entorno personalizado
Con los entornos personalizados, puede configurar las bibliotecas y propiedades personalizadas de Spark. Para crear un entorno personalizado:
- Acceder al área de trabajo de Azure Synapse: inicie sesión en Azure. Vaya al área de trabajo de Apache Synapse, luego a Grupos de Analytics y seleccione Grupos de Apache Spark.
- Buscar el grupo de Spark: en los grupos de Apache Spark, busque el grupo de Spark que desea mover a Fabric y compruebe las propiedades del grupo.
- Obtener propiedades: obtenga las propiedades del grupo de Spark, como la versión de Apache Spark, la familia del tamaño de los nodos, el tamaño de los nodos o la escalabilidad automática. Para ver las diferencias, consulte las consideraciones sobre los grupos de Spark.
- Crear un grupo de Spark personalizados:
- Vaya al área de trabajo Fabric y seleccione Configuración del área de trabajo.
- Vaya a Ingeniería de datos/ciencia y seleccione Configuración de Spark.
- Seleccione la pestaña Grupo y en la sección Grupo predeterminado del área de trabajo, expanda el menú desplegable u seleccione Crear grupo.
- Cree su grupo personalizado con los valores de destino correspondientes. Rellene las opciones de nombre, familia de los nodos, tamaño de los nodos, escalado automático y asignación dinámica del ejecutor.
- Cree un elemento Entorno si no lo tiene.
- Configurar el proceso de Spark:
- En Entorno, vaya a Proceso de Spark>Proceso.
- Seleccione el grupo recién creado del nuevo entorno.
- Puede configurar los núcleos y la memoria del controlador y de los ejecutores.
- Seleccione una versión del runtime para el entorno. Vea aquí los runtimes disponibles.
- Haga clic en Guardar y Publicar cambios.
Obtenga más información sobre la creación y el uso de un Entorno.