Migración: Grupos de SQL dedicados de Azure Synapse Analytics
Esto se aplica a:✅ Warehouse en Microsoft Fabric
En este artículo se detallan la estrategia, las consideraciones y los métodos de migración del almacenamiento de datos en grupos de SQL dedicados de Azure Synapse Analytics a Microsoft Fabric Warehouse.
Introducción a la migración
Microsoft presentó Microsoft Fabric, una solución de análisis SaaS todo en uno para empresas que ofrece un conjunto completo de servicios, como Data Factory, Ingeniería de datos, Almacenamiento de datos, Ciencia de datos, Inteligencia en tiempo real y Power BI.
Este artículo se centra en las opciones de migración de esquemas (DDL), migración de código de base de datos (DML) y migración de datos. Microsoft ofrece varias opciones, y aquí se describe cada una en detalle y se proporciona orientación sobre cuál de estas debe tener en cuenta para su escenario. En este artículo se usa el punto de referencia del sector TPC-DS para las pruebas de ilustración y rendimiento. El resultado real puede variar en función de muchos factores, como el tipo de datos, los tipos de datos, el ancho de las tablas, la latencia del origen de datos, etc.
Preparación para la migración
Planee cuidadosamente el proyecto de migración antes de empezar y asegúrese de que el esquema, el código y los datos son compatibles con Fabric Warehouse. Existen algunas limitaciones que debe tener en cuenta. Cuantifique el trabajo de refactorización de los elementos incompatibles, así como cualquier otro recurso necesario antes de la entrega de la migración.
Otro objetivo importante de la planeación es ajustar el diseño para garantizar que la solución aprovecha al máximo el alto rendimiento de las consultas que el diseño de Azure Synapse Analytics facilita. El diseño de almacenamientos de datos con fines de escalabilidad presenta diferentes patrones de diseño, por lo que los enfoques tradicionales no son siempre los mejores. Revise las directrices de rendimiento de Fabric Warehouse, ya que, aunque se pueden realizar algunos ajustes de diseño después de la migración, realizar cambios anteriormente en el proceso le ahorrará tiempo y esfuerzo. La migración de una tecnología o entorno a otra siempre es un esfuerzo importante.
En el siguiente diagrama se muestra el ciclo de vida de migración que enumera los principales pilares que constan de valoración y evaluación, plan y diseño, migración, supervisión y control, optimización y modernización de pilares con las tareas asociadas de cada pilar para planear y preparar la migración sin problemas.

Runbook para la migración
Tenga en cuenta las siguientes actividades como runbook de planificación para la migración desde grupos de SQL dedicados de Synapse a Fabric Warehouse.
- Valoración y evaluación
- Identifique objetivos y motivaciones. Establezca resultados deseados claros.
- Detecte, evalúe y establezca la línea de base de la arquitectura existente.
- Identifique las partes interesadas y los patrocinadores clave.
- Defina el ámbito de lo que se va a migrar.
- Comience por algo pequeño y sencillo, prepárese para varias migraciones pequeñas.
- Comience a supervisar y documentar todas las fases del proceso.
- Generar el inventario de datos y procesos para la migración.
- Definir los cambios en el modelo de datos (si procede).
- Configure el área de trabajo de Fabric.
- ¿Cuál es su conjunto de aptitudes o preferencias?
- Automatice siempre que sea posible.
- Uso de herramientas y características integradas de Azure para reducir el esfuerzo de migración.
- Entrene al personal en la nueva plataforma desde el principio.
- Identificación de las necesidades de mejora y los recursos de entrenamiento, incluido Microsoft Learn.
- Plan y diseño
- Defina la arquitectura deseada.
- Seleccione el método o herramientas de la migración para realizar las siguientes tareas:
- Extracción de datos del origen.
- Conversión de esquema (DDL), incluidos los metadatos para tablas y vistas
- Ingesta de datos, incluidos los datos históricos.
- Si procede, vuelva a diseñar el modelo de datos, con el nuevo rendimiento y escalabilidad de la plataforma.
- Migración de código de base de datos (DML).
- Migre o refactorice los procedimientos almacenados y los procesos empresariales.
- Realice un inventario y extraiga las características de seguridad y los permisos de objeto del origen.
- Diseñe y planee reemplazar o modificar los procesos ETL/ELT existentes para la carga incremental.
- Cree procesos ETL/ELT paralelos en el nuevo entorno.
- Prepare un plan de migración detallado.
- Asigne el estado actual al nuevo estado deseado.
- Migrar
- Realice el esquema, los datos y la migración de código.
- Extracción de datos del origen.
- Conversión de esquema (DDL)
- Ingesta de datos
- Migración de código de base de datos (DML).
- Si procede, escale los recursos del grupo de SQL dedicados temporalmente para ayudar a acelerar la migración.
- Aplique seguridad y permisos.
- Migre los procesos ETL/ELT existentes para la carga incremental.
- Migre o refactorice los procesos de carga incremental ETL/ELT.
- Pruebe y compare los procesos de carga de incrementos paralelos.
- Adapte el plan de migración detallado según sea necesario.
- Realice el esquema, los datos y la migración de código.
- Supervisión y control
- Ejecute en paralelo y compárelo con el entorno de origen.
- Pruebe aplicaciones, plataformas de inteligencia empresarial y herramientas de consulta.
- Realice evaluaciones comparativas y optimice el rendimiento de las consultas.
- Supervise y administre los costos, la seguridad y el rendimiento.
- Punto de referencia y valoración de la gobernanza.
- Ejecute en paralelo y compárelo con el entorno de origen.
- Optimización y modernización
- Cuando la empresa se sienta cómoda, realice la transición de aplicaciones y plataformas de informes principales a Fabric.
- Escale o reduzca verticalmente los recursos a medida que la carga de trabajo cambie de Azure Synapse Analytics a Microsoft Fabric.
- Cree una plantilla repetible a partir de la experiencia adquirida para futuras migraciones. Itere.
- Identifique oportunidades de optimización de costos, seguridad, escalabilidad y excelencia operativa
- Identifique las oportunidades para modernizar el patrimonio de datos con las características más recientes de Fabric.
- Cuando la empresa se sienta cómoda, realice la transición de aplicaciones y plataformas de informes principales a Fabric.
¿Migración mediante lift-and-shift o modernización?
En general, hay dos tipos de escenarios de migración, independientemente del propósito y el ámbito de la migración planeada: lift-and-shift, o un enfoque por fases que incorpore cambios arquitectónicos y de código.
Lift-and-shift
En una migración mediante lift-and-shift, se migra un modelo de datos existente con cambios menores en el nuevo almacenamiento de Fabric. Este enfoque minimiza el riesgo y el tiempo de migración al reducir el nuevo trabajo necesario para obtener las ventajas de la migración.
La migración mediante lift-and-shift es una buena opción para estos escenarios:
- Tiene un entorno existente con un pequeño número de data marts que se van a migrar.
- Tiene un entorno existente con datos que ya están en un esquema de estrella o copo de nieve bien diseñado.
- Está bajo presión de tiempo y costos para pasar a Fabric Warehouse.
En resumen, este enfoque funciona bien para esas cargas de trabajo optimizadas con el entorno actual de grupos de SQL dedicados de Synapse y, por lo tanto, no requiere cambios importantes en Fabric.
Modernización en un enfoque por fases con cambios arquitectónicos
Si un almacén heredado ha evolucionado con el tiempo, es posible que tenga que volver a diseñarlo para mantener el rendimiento necesario.
También puede que quiera rediseñar la arquitectura para aprovechar los nuevos motores y características disponibles en el área de trabajo de Fabric.
Diferencias de diseño: grupos de SQL dedicados de Synapse y Fabric Warehouse
Tenga en cuenta las siguientes diferencias de almacenamiento de datos de Azure Synapse y Microsoft Fabric, comparando los grupos de SQL dedicados con Fabric Warehouse.
Consideraciones sobre las tablas
Al migrar tablas entre distintos entornos, normalmente solo se migran físicamente los datos sin procesar y los metadatos que los describen. Otros elementos de base de datos del sistema de origen, como los índices, normalmente no se migran porque podrían ser innecesarios o implementados de forma diferente en el nuevo entorno.
Las optimizaciones de rendimiento en el entorno de origen, como los índices, indican dónde puede agregar optimizaciones del rendimiento en un nuevo entorno, pero ahora Fabric se encarga de eso automáticamente.
Consideraciones de T-SQL
Hay varias diferencias de sintaxis del lenguaje de manipulación de datos (DML) que hay que tener en cuenta. Consulte área expuesta de T-SQL en Microsoft Fabric. Considere también una evaluación de código al elegir métodos de migración para el código de base de datos (DML).
En función de las diferencias de paridad en el momento de la migración, es posible que tenga que volver a escribir partes del código DML de T-SQL.
Diferencias de asignación de tipos de datos
Hay varias diferencias de tipo de datos en Fabric Warehouse. Para obtener más información, consulte Tipos de datos en Microsoft Fabric.
En la siguiente tabla se proporciona la asignación de tipos de datos admitidos de grupos de SQL dedicados de Synapse a Fabric Warehouse.
| Grupos de SQL dedicados de Synapse | Fabric Warehouse |
|---|---|
| money | decimal(19,4) |
| smallmoney | decimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| NCHAR | char |
| nvarchar | varchar |
| TINYINT | smallint |
| binary | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 no almacena la información adicional de desplazamiento de zona horaria en la que se almacena. Dado que el tipo de datos datetimeoffset no se admite actualmente en Fabric Warehouse, los datos de desplazamiento de zona horaria deben extraerse en una columna independiente.
Métodos de migración de esquemas, código y datos
Revise e identifique cuál de estas opciones se ajusta a su escenario, a las aptitudes del personal y a las características de los datos. Las opciones elegidas dependerán de su experiencia, preferencia y de las ventajas de cada una de las herramientas. Nuestro objetivo es seguir desarrollando herramientas de migración que mitiguen la fricción y la intervención manual para que esa experiencia de migración sea perfecta.
En esta tabla se resume la información del esquema de datos (DDL), el código de base de datos (DML) y los métodos de migración de datos. Más adelante en este artículo, vinculado en la columna Opción, ampliaremos cada escenario.
| Número de opción | Opción | Lo que hace | Aptitud/Preferencia | Escenario |
|---|---|---|---|---|
| 1 | Data Factory | Conversión de esquema (DDL) Extracción de datos Ingesta de datos |
ADF/Canalización | Se ha simplificado todo en un esquema (DDL) y la migración de datos. Se recomienda para las tablas de dimensiones. |
| 2 | Data Factory con partición | Conversión de esquema (DDL) Extracción de datos Ingesta de datos |
ADF/Canalización | El uso opciones de creación de particiones para aumentar el paralelismo de lectura y escritura proporciona un rendimiento 10 veces superior frente a la opción 1, recomendada para las tablas de hechos. |
| 3 | Data Factory con código acelerado | Conversión de esquema (DDL) | ADF/Canalización | Convierta y migre primero el esquema (DDL), use CETAS para extraer y COPY/Data Factory para ingerir datos para obtener un rendimiento de ingesta general óptimo. |
| 4 | Código acelerado de procedimientos almacenados | Conversión de esquema (DDL) Extracción de datos Valoración del código |
T-SQL | Usuario de SQL que usa IDE con un control más pormenorizado sobre las tareas en las que desea trabajar. Use COPY/Data Factory para ingerir datos. |
| 5 | Extensión Proyecto de SQL Database para Azure Data Studio | Conversión de esquema (DDL) Extracción de datos Valoración del código |
Proyecto de SQL | Proyecto de SQL Database para la implementación con la integración de la opción 4. Use COPY o Data Factory para ingerir datos. |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | Extracción de datos | T-SQL | Extracción de datos rentable y de alto rendimiento en Azure Data Lake Storage (ADLS) Gen2. Use COPY/Data Factory para ingerir datos. |
| 7 | Migración mediante dbt | Conversión de esquema (DDL) Conversión de código de base de datos (DML) |
dbt | Los usuarios de dbt existentes pueden usar el adaptador de dbt Fabric para convertir su DDL y DML. A continuación, debe migrar datos mediante otras opciones de esta tabla. |
Elección de la carga de trabajo para la migración inicial
Al decidir dónde empezar en el grupo de SQL dedicado de Synapse al proyecto de migración de Fabric Warehouse, elija un área de carga de trabajo donde pueda:
- Demostrar la viabilidad de la migración a Azure Synapse con la obtención de beneficios rápidos del nuevo entorno. Comience por algo pequeño y sencillo, prepárese para varias migraciones pequeñas.
- Permitir que el personal técnico interno tenga tiempo para obtener experiencia relevante con los procesos y herramientas que usan al migrar a otras áreas.
- Crear una plantilla para realizar migraciones adicionales específicas del entorno de Synapse de origen, así como las herramientas y los procesos implementados para ayudar.
Sugerencia
Crear un inventario de objetos que deban migrarse y documente el proceso de migración de principio a fin, de modo que se pueda repetir para otros grupos o cargas de trabajo de SQL dedicados.
El volumen de datos migrados en una migración inicial debe ser lo suficientemente grande como para demostrar las funcionalidades y ventajas del entorno de Azure Synapse, pero no demasiado grande para demostrar rápidamente el valor. Un tamaño en el rango de 1 a 10 terabytes es lo habitual.
Migración con Fabric Data Factory
En esta sección, se describen las opciones que usan Data Factory para el rol de código bajo o sin código que está familiarizado con Azure Data Factory y la canalización de Synapse. Esta opción de interfaz de usuario de arrastrar y colocar proporciona un paso sencillo para convertir el DDL y migrar los datos.
Fabric Data Factory puede realizar las siguientes tareas:
- Convertir el esquema (DDL) en sintaxis de Fabric Warehouse.
- Crear el esquema (DDL) en Fabric Warehouse.
- Migrar los datos a Fabric Warehouse.
Opción 1. Migración de esquemas y datos: asistente para copia y actividad de copia ForEach
Este método usa el Asistente para copia de Data Factory para conectarse al grupo de SQL dedicado de origen, convertir la sintaxis DDL del grupo de SQL dedicado en Fabric y copiar datos en Fabric Warehouse. Puede seleccionar una o más tablas de destino (para el conjunto de datos TPC-DS hay 22 tablas). Genera ForEach para recorrer en bucle la lista de tablas seleccionadas en la interfaz de usuario y generar 22 subprocesos de actividad de copia en paralelo.
- Se han generado y ejecutado 22 Consultas SELECT (una para cada tabla seleccionada) en el grupo de SQL dedicado.
- Asegúrese de que tiene la clase de recursos y DWU adecuada para permitir que se ejecuten las consultas generadas. Para este caso, necesita un mínimo de DWU1000 con
staticrc10para permitir que un máximo de 32 consultas controle 22 consultas enviadas. - La copia directa de datos de Data Factory desde el grupo de SQL dedicado a Fabric Warehouse requiere almacenamiento provisional. El proceso de ingesta consta de dos fases.
- La primera fase consiste en extraer los datos del grupo de SQL dedicado en ADLS y se conoce como almacenamiento provisional.
- La segunda fase consiste en ingerir los datos de ensayo en Fabric Warehouse. La mayor parte del tiempo de ingesta de datos se encuentra en la fase de almacenamiento provisional. En resumen, el almacenamiento provisional tiene un gran impacto en el rendimiento de la ingesta.
Uso recomendado
Con el Asistente para copia para generar una interfaz de usuario de ForEach se proporciona una interfaz de usuario sencilla para convertir DDL e ingerir las tablas seleccionadas del grupo de SQL dedicado en Fabric Warehouse en un paso.
Sin embargo, no es óptimo con el rendimiento general. El requisito de usar el almacenamiento provisional, la necesidad de paralelizar la lectura y escritura del paso "Origen a fase" son los principales factores para la latencia de rendimiento. Se recomienda usar esta opción solo para tablas de dimensiones.
Opción 2. Migración de DDL y datos: canalización de datos mediante la opción de partición
Para abordar la mejora del rendimiento para cargar tablas de hechos más grandes mediante la canalización de datos de Fabric, se recomienda usar la actividad de copia para cada tabla de hechos con la opción de partición. Esto proporciona el mejor rendimiento con la actividad de copia.
Tiene la opción de usar la creación de particiones físicas de la tabla de origen, si está disponible. Si la tabla no tiene particiones físicas, debe especificar la columna de partición y proporcionar valores mín/máx para usar la creación de particiones dinámicas. En la siguiente captura de pantalla, las opciones de Origen de la canalización de datos especifican un intervalo dinámico de particiones en función de la columna ws_sold_date_sk.

Aunque el uso de la partición puede aumentar el rendimiento con la fase de almacenamiento provisional, hay consideraciones para realizar los ajustes adecuados:
- En función del intervalo de particiones, podría usar todas las ranuras de simultaneidad, ya que podría generar más de 128 consultas en el grupo de SQL dedicado.
- Es necesario escalar a un mínimo de DWU6000 para permitir que se ejecuten todas las consultas.
- Por ejemplo, para la tabla TPC-DS
web_sales, se enviaron 163 consultas al grupo de SQL dedicado. En DWU6000, se ejecutaron 128 consultas mientras se ponen en cola 35 consultas. - La partición dinámica selecciona automáticamente la partición de intervalo. En este caso, un intervalo de 11 días para cada consulta SELECT enviada al grupo de SQL dedicado. Por ejemplo:
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Uso recomendado
Para las tablas de hechos, se recomienda usar Data Factory con la opción de creación de particiones para aumentar el rendimiento.
Sin embargo, el aumento de las lecturas en paralelo requiere un grupo de SQL dedicado para escalar a una DWU superior para permitir que se ejecuten las consultas de extracción. Aprovechando la creación de particiones, la velocidad se mejora 10 veces más que ninguna opción de partición. Puede aumentar la DWU para obtener un rendimiento adicional a través de recursos de proceso, pero el grupo de SQL dedicado tiene un máximo de 128 consultas activas permitidas.
Nota:
Para obtener más información sobre la asignación de DWU a Fabric de Synapse, consulte Blog: Asignación de grupos de SQL dedicados de Azure Synapse al proceso de almacenamiento de datos de Fabric.
Opción 3. Migración de DDL: actividad de copia del Asistente para copia de ForEach
Las dos opciones anteriores son excelentes opciones de migración de datos para bases de datos más pequeñas. Pero si necesita un mayor rendimiento, se recomienda una opción alternativa:
- Extraiga los datos del grupo de SQL dedicado a ADLS, lo que mitiga la sobrecarga de rendimiento de la fase.
- Use Data Factory o el comando COPY para ingerir los datos en Fabric Warehouse.
Uso recomendado
Puede seguir usando Data Factory para convertir el esquema (DDL). Con el Asistente para copia, puede seleccionar la tabla específica o Todas las tablas. Por diseño, esto migra el esquema y los datos en un paso, lo que extrae el esquema sin ninguna fila, con la condición false, TOP 0 en la instrucción de consulta.
En el siguiente ejemplo de código se trata la migración del esquema (DDL) con Data Factory.
Ejemplo de código: migración de esquema (DDL) con Data Factory
Puede usar Canalizaciones de datos de Fabric para migrar fácilmente a través de DDL (esquemas) para objetos de tabla desde cualquier instancia de Azure SQL Database de origen o grupo de SQL dedicado. Esta canalización de datos se migra a través del esquema (DDL) de las tablas de grupo de SQL dedicadas de origen a Fabric Warehouse.

Diseño de canalización: parámetros
Esta canalización de datos acepta un parámetro SchemaName, que permite especificar qué esquemas se van a migrar. El esquema dbo es el valor predeterminado.
En el campo Valor predeterminado, escriba una lista delimitada por comas del esquema de tabla que indica qué esquemas se van a migrar: 'dbo','tpch' para proporcionar dos esquemas: dbo y tpch.

Diseño de canalización: actividad de búsqueda
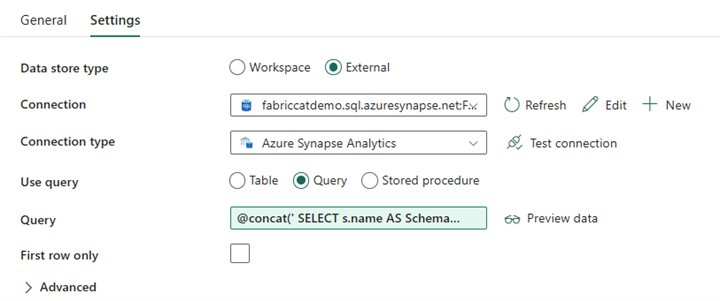
Cree una actividad de búsqueda y establezca la conexión para que apunte a la base de datos de origen.
En la pestaña Configuración:
Establezca Tipo de almacén de datos en Externo.
Conexión es el grupo de SQL dedicado de Azure Synapse. Tipo de conexión: seleccione Azure Synapse Analytics.
Usar consulta está establecido en Consulta.
El campo Consulta debe crearse mediante una expresión dinámica, lo que permite usar el parámetro SchemaName en una consulta que devuelve una lista de tablas de origen de destino. Seleccione Consulta y, a continuación, seleccione Agregar contenido dinámico.
Esta expresión dentro de la actividad de búsqueda genera una instrucción SQL para consultar las vistas del sistema para recuperar una lista de esquemas y tablas. Hace referencia al parámetro SchemaName para permitir el filtrado en esquemas SQL. El resultado es una matriz de esquemas SQL y tablas que se usarán como entrada en la actividad ForEach.
Usa el siguiente código para devolver una lista de todas las tablas de usuario con su nombre de esquema.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
Diseño de canalización: bucle ForEach
Para el bucle ForEach, configure las siguientes opciones en la pestaña Configuración:
- Deshabilite Secuencial para permitir que varias iteraciones se ejecuten simultáneamente.
- Establezca Recuento de lotes en
50, limitando el número máximo de iteraciones simultáneas. - El campo Elementos debe usar contenido dinámico para hacer referencia a la salida de la actividad de búsqueda. Use el siguiente fragmento de código:
@activity('Get List of Source Objects').output.value

Diseño de canalización: actividad de copia dentro del bucle ForEach
Dentro de la actividad ForEach, agregue una actividad de copia. Este método usa el lenguaje de expresiones dinámicas dentro de las canalizaciones de datos para compilar un SELECT TOP 0 * FROM <TABLE> para migrar solo el esquema sin datos a Fabric Warehouse.
En la pestaña Origen:
- Establezca Tipo de almacén de datos en Externo.
- Conexión es el grupo de SQL dedicado de Azure Synapse. Tipo de conexión: seleccione Azure Synapse Analytics.
- Establezca Usar consulta en Consulta.
- En el campo Consulta, pegue la consulta de contenido dinámico y use esta expresión que devolverá cero filas, solo el esquema de la tabla:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

En la pestaña Destino:
- Establezca Tipo de almacén de datos en Área de trabajo.
- El tipo de almacén de datos del área de trabajo es Data Warehouse y Data Warehouse se establece en Fabric Warehouse.
- El esquema y el nombre de la tabla de destino se definen mediante contenido dinámico.
- El esquema hace referencia al campo de la iteración actual, SchemaName con el fragmento de código:
@item().SchemaName - La tabla hace referencia a TableName con el fragmento de código:
@item().TableName
- El esquema hace referencia al campo de la iteración actual, SchemaName con el fragmento de código:

Diseño de canalización: Receptor
En Receptor, apunte al almacén y haga referencia al nombre de esquema y tabla de origen.
Una vez que ejecute esta canalización, verá que el almacenamiento de datos se rellena con cada tabla del origen, con el esquema adecuado.
Migración mediante procedimientos almacenados en el grupo de SQL dedicado de Synapse
Esta opción usa procedimientos almacenados para realizar la migración de Fabric.
Puede obtener los ejemplos de código en microsoft/fabric-migration en GitHub.com. Este código se comparte como código abierto, así que no dude en colaborar y ayudar a la comunidad.
Qué pueden hacer los procedimientos almacenados de migración:
- Convertir el esquema (DDL) en sintaxis de Fabric Warehouse.
- Crear el esquema (DDL) en Fabric Warehouse.
- Extraer datos del grupo de SQL dedicado de Synapse a ADLS.
- Marcar la sintaxis de Fabric no admitida para códigos T-SQL (procedimientos almacenados, funciones, vistas).
Uso recomendado
Esta es una excelente opción para aquellos que:
- Están familiarizados con T-SQL.
- Quieren usar un entorno de desarrollo integrado como SQL Server Management Studio (SSMS).
- Desean un control más pormenorizado sobre las tareas en las que quieren trabajar.
Puede ejecutar el procedimiento almacenado específico para la conversión del esquema (DDL), la extracción de datos o la evaluación de código de T-SQL.
Para la migración de datos, deberá usar COPY INTO o Data Factory para ingerir los datos en Fabric Warehouse.
Migrar mediante los proyectos de base de datos de SQL
Se admite Data Warehouse de Microsoft Fabric en la extensión Proyectos de SQL Database disponible dentro de Azure Data Studio y Visual Studio Code.
Esta extensión está disponible en Azure Data Studio y Visual Studio Code. Esta característica permite funcionalidades para el control de código fuente, las pruebas de base de datos y la validación de esquemas.
Para obtener más información sobre el control de código fuente para almacenes en Microsoft Fabric, incluidas las canalizaciones de integración e implementación de Git, consulte Control de código fuente con almacenamiento.
Uso recomendado
Esta es una excelente opción para aquellos que prefieren usar el proyecto de SQL Database para su implementación. Esta opción integra básicamente los procedimientos almacenados de migración de Fabric en el proyecto de SQL Database para proporcionar una experiencia de migración sin problemas.
Un proyecto de SQL Database puede:
- Convertir el esquema (DDL) en sintaxis de Fabric Warehouse.
- Crear el esquema (DDL) en Fabric Warehouse.
- Extraer datos del grupo de SQL dedicado de Synapse a ADLS.
- Marcar la sintaxis no admitida para códigos T-SQL (procedimientos almacenados, funciones, vistas).
Para la migración de datos, usará COPY INTO o Data Factory para ingerir los datos en Fabric Warehouse.
Además de la compatibilidad de Azure Data Studio con Microsoft Fabric, el equipo CAT de Microsoft Fabric ha proporcionado un conjunto de scripts de PowerShell para controlar la extracción, creación e implementación del esquema (DDL) y el código de base de datos (DML) mediante un proyecto de SQL Database. Para ver un tutorial sobre el uso del proyecto de SQL Database con nuestros scripts útiles de PowerShell, consulte microsoft/fabric-migration en GitHub.com.
Para obtener más información sobre proyectos de SQL Database, consulte Introducción a la extensión Proyectos de SQL Database y Compilación y publicación de un proyecto.
Migración de datos con CETAS
El comando T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) proporciona el método más rentable y óptimo para extraer datos de grupos de SQL dedicados de Synapse a Azure Data Lake Storage (ADLS) Gen2.
Qué puede hacer CETAS:
- Extraer datos en ADLS.
- Esta opción requiere que los usuarios creen el esquema (DDL) en Fabric Warehouse antes de ingerir los datos. Tenga en cuenta las opciones de este artículo para migrar el esquema (DDL).
Las ventajas de esta opción son:
- Solo se envía una sola consulta por tabla en el grupo de SQL dedicado de Synapse de origen. No usará todas las ranuras de simultaneidad, por lo que no bloqueará las consultas ETL/ETL de producción simultáneas del cliente.
- El escalado a DWU6000 no es necesario, ya que solo se usa una sola ranura de simultaneidad para cada tabla, por lo que los clientes pueden usar DWU inferiores.
- La extracción se ejecuta en paralelo en todos los nodos de proceso y esta es la clave para mejorar el rendimiento.
Uso recomendado
Use CETAS para extraer los datos en ADLS como archivos Parquet. Los archivos Parquet proporcionan la ventaja del almacenamiento de datos eficaz con compresión de columnas que necesitará menos ancho de banda para moverse por la red. Además, dado que Fabric almacenó los datos como formato Delta Parquet, la ingesta de datos será 2,5 veces más rápida en comparación con el formato de archivo de texto, ya que no hay ninguna conversión a la sobrecarga de formato Delta durante la ingesta.
Para aumentar el rendimiento de CETAS:
- Agregue operaciones CETAS paralelas, lo que aumenta el uso de ranuras de simultaneidad, pero permite más rendimiento.
- Escale la DWU en el grupo de SQL dedicado de Synapse.
Migración a través de dbt
En esta sección, se describe la opción dbt para aquellos clientes que ya usan dbt en su entorno actual del grupo de SQL dedicado de Synapse.
Qué puede hacer dbt:
- Convertir el esquema (DDL) en sintaxis de Fabric Warehouse.
- Crear el esquema (DDL) en Fabric Warehouse.
- Convertir el código de base de datos (DML) en sintaxis de Fabric.
El marco dbt genera DDL y DML (scripts SQL) sobre la marcha con cada ejecución. Con los archivos de modelo expresados en instrucciones SELECT, DDL/DML se puede traducir al instante a cualquier plataforma de destino cambiando el perfil (cadena de conexión) y el tipo de adaptador.
Uso recomendado
El marco dbt es el enfoque de code-first. Los datos deben migrarse mediante opciones enumeradas en este documento, como CETAS o COPY/Data Factory.
El adaptador de dbt para Microsoft Fabric Data Warehouse permite migrar los proyectos de dbt existentes destinados a distintas plataformas, como grupos de SQL dedicados de Synapse, Snowflake, Databricks, Google Big Query o Amazon Redshift, con un simple cambio de configuración.
Para empezar a trabajar con un proyecto de dbt destinado a Fabric Warehouse, consulte Tutorial: Configuración de dbt para Fabric Data Warehouse. En este documento también se muestra una opción para moverse entre diferentes almacenes o plataformas.
Ingesta de datos en Fabric Warehouse
Para la ingesta en Fabric Warehouse, use COPY INTO o Fabric Data Factory, según sus preferencias. Ambos métodos son las opciones recomendadas y de mejor rendimiento, ya que tienen un rendimiento equivalente, dado que los archivos ya se extraen en Azure Data Lake Storage (ADLS) Gen2.
Varios factores que se deben tener en cuenta para que pueda diseñar el proceso para obtener el máximo rendimiento:
- Con Fabric, no hay ninguna contención de recursos al cargar varias tablas de ADLS a Fabric Warehouse simultáneamente. Como resultado, no hay ninguna degradación del rendimiento al cargar los subprocesos paralelos. El rendimiento máximo de ingesta solo estará limitado por la potencia de proceso de la capacidad de Fabric.
- La administración de cargas de trabajo de Fabric proporciona separación de los recursos asignados para la carga y consulta. No hay contención de recursos mientras las consultas y la carga de datos se ejecutan al mismo tiempo.