Creación de un almacén de lago de datos para Direct Lake
En este artículo se describe cómo crear un lakehouse, crear una tabla Delta en el lakehouse y, a continuación, crear un modelo semántico básico para el lakehouse en un área de trabajo de Microsoft Fabric.
Antes de empezar a crear un almacén de lago de datos para Direct Lake, asegúrese de leer Información general de Direct Lake.
Creación de un almacén de lago de datos
En el área de trabajo de Microsoft Fabric, seleccione Nuevo>Más opciones y, después, en Ingeniería de datos, seleccione el icono Almacén de lago de datos.
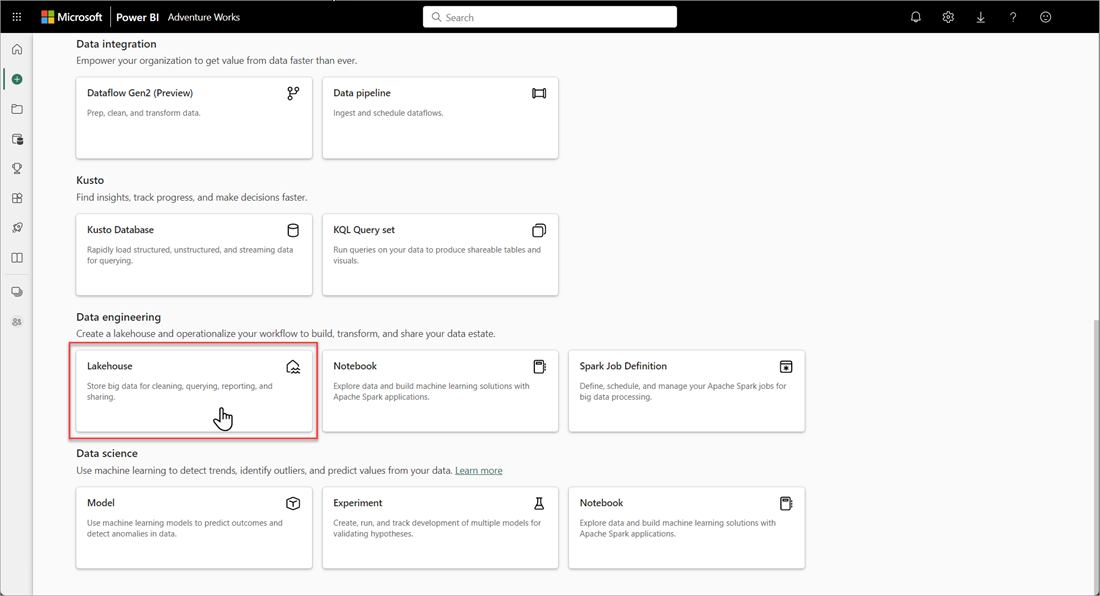
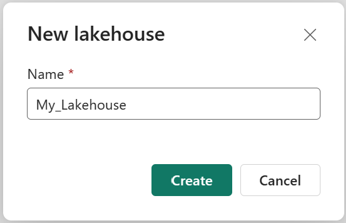
En el cuadro de diálogo Nuevo almacén de lago de datos, escriba un nombre y, después, seleccione Crear. El nombre solo puede contener caracteres alfanuméricos y caracteres de subrayado.
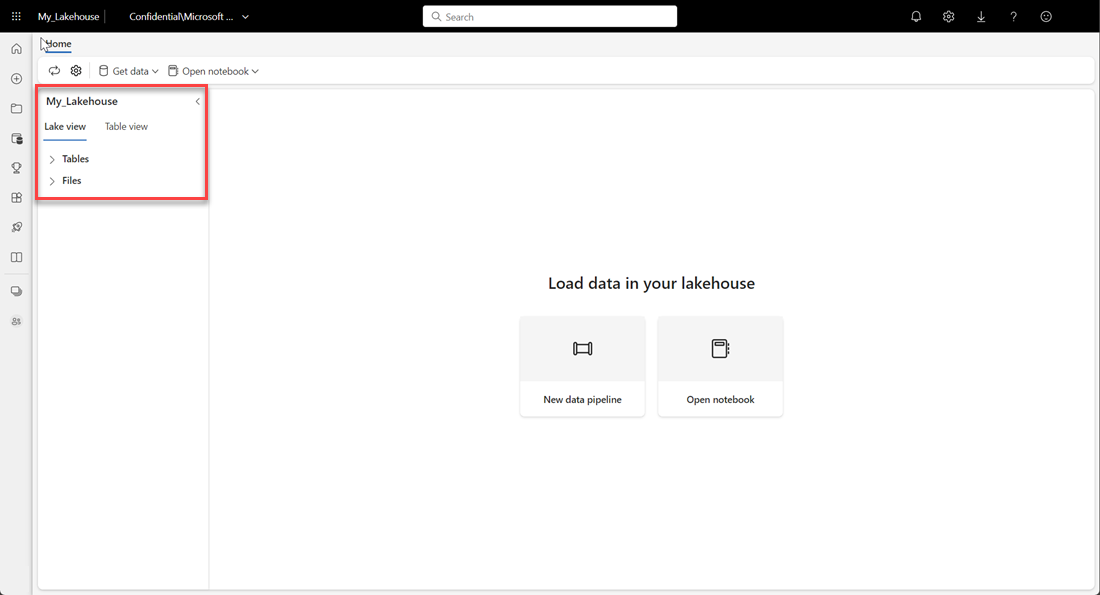
Compruebe que el nuevo almacén de lago de datos se crea y se abre correctamente.
Crear una tabla Delta en la casa del lago
Después de crear un nuevo lakehouse, hay que crear al menos una tabla Delta para que Direct Lake pueda acceder a datos. Direct Lake puede leer archivos con formato parquet, pero para obtener el mejor rendimiento, es mejor comprimir los datos mediante el método de compresión VORDER. VORDER comprime los datos mediante el algoritmo de compresión nativa del motor de Power BI. De este modo, el motor puede cargar los datos en la memoria lo antes posible.
Hay varias opciones para cargar datos en un almacén de lago de datos, incluidas las canalizaciones de datos y los scripts. En los siguientes pasos se utiliza PySpark para añadir una tabla Delta a un almacén de lago de datos basado en una instancia de Azure Open Dataset:
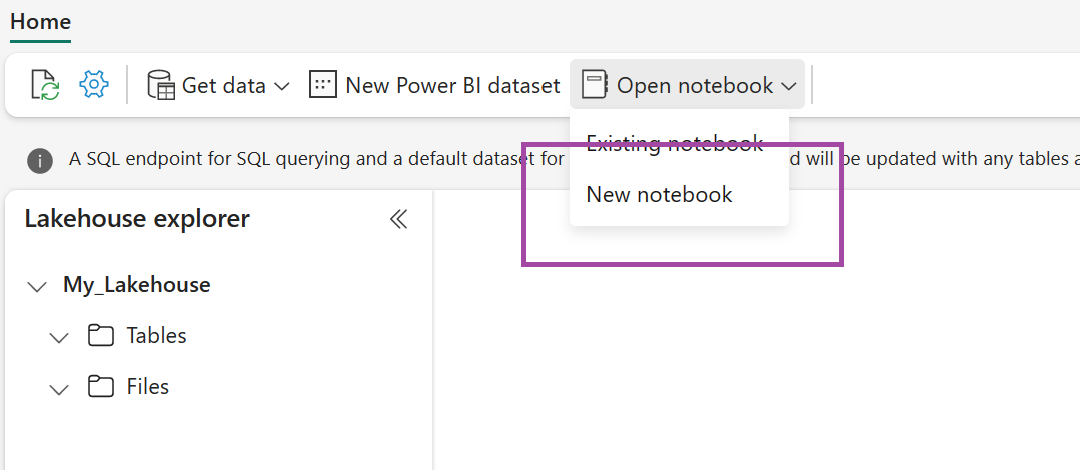
En el almacén de lago de datos recién creado, seleccione Abrir cuaderno y después Nuevo cuaderno.
Copie y pegue el siguiente fragmento de código en la primera celda de código para permitir que SPARK acceda al modelo abierto y presione Mayús + Entrar para ejecutar el código.
# Azure storage access info blob_account_name = "azureopendatastorage" blob_container_name = "holidaydatacontainer" blob_relative_path = "Processed" blob_sas_token = r"" # Allow SPARK to read from Blob remotely wasbs_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path) spark.conf.set( 'fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token) print('Remote blob path: ' + wasbs_path)Compruebe que el código genera correctamente una ruta de acceso de blob remota.
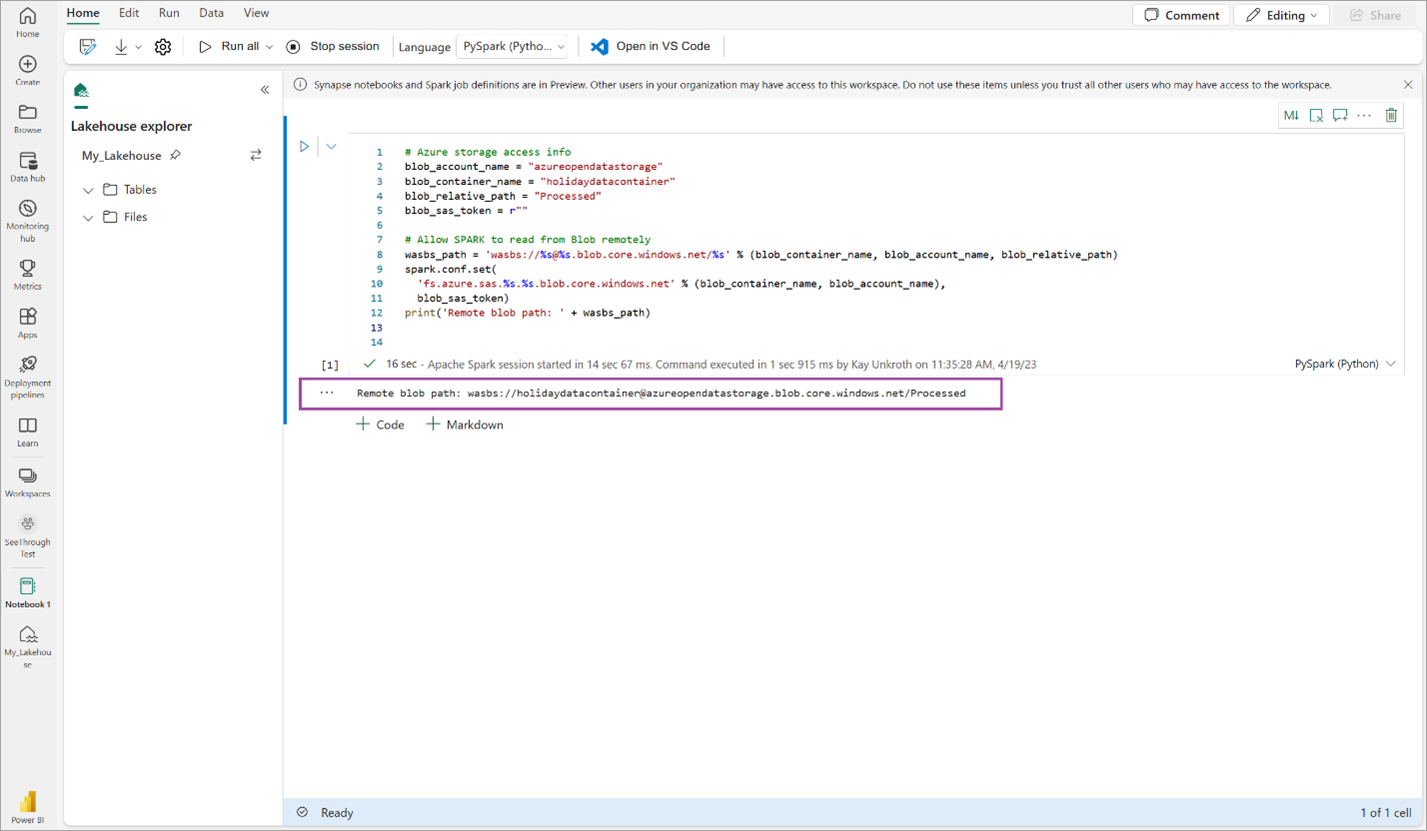
Copie y pegue el código siguiente en la celda siguiente y presione Mayús + Entrar.
# Read Parquet file into a DataFrame. df = spark.read.parquet(wasbs_path) print(df.printSchema())Compruebe que el código genera correctamente el esquema DataFrame.

Copie y pegue las líneas siguientes en la celda siguiente y presione Mayús + Entrar. La primera instrucción habilita el método de compresión VORDER y la siguiente instrucción guarda el DataFrame como una tabla Delta en el lakehouse.
# Save as delta table spark.conf.set("spark.sql.parquet.vorder.enabled", "true") df.write.format("delta").saveAsTable("holidays")Compruebe que todos los trabajos de SPARK se completen correctamente. Expanda la lista de trabajos de SPARK para ver más detalles.

Para comprobar que una tabla se ha creado correctamente, en el área superior izquierdo, junto a Tablas, seleccione la elipsis (...), seleccione Actualizary, a continuación, expanda el nodo Tablas.
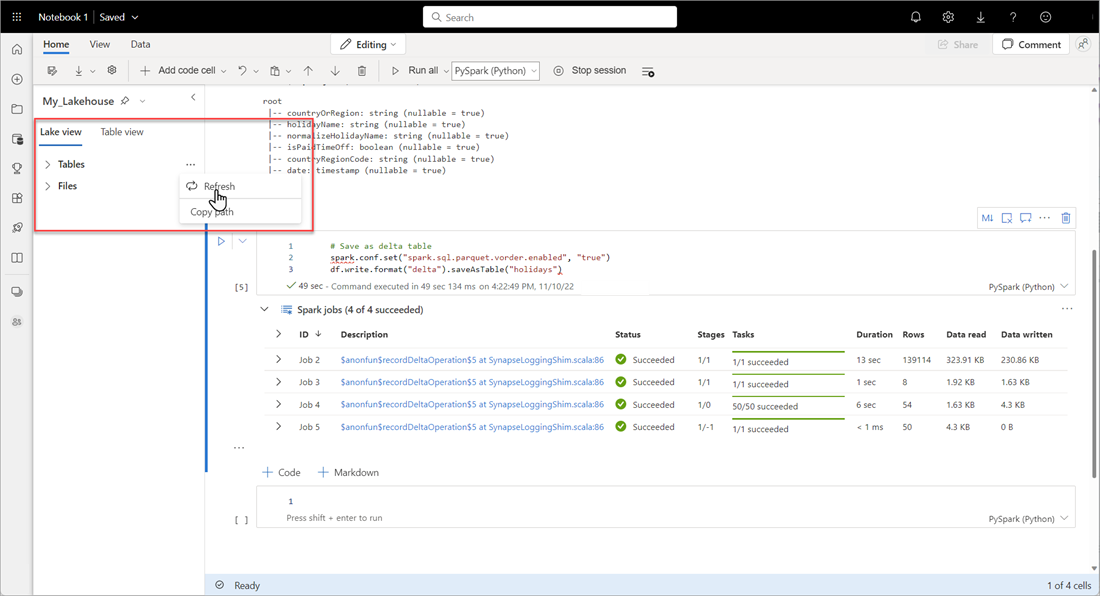
Con el mismo método que antes u otros métodos admitidos, agregue más tablas Delta para los datos que desea analizar.
Creación de un modelo básico de Direct Lake para su lakehouse
En el lakehouse, seleccione Nuevo modelo semánticoy, después, en el cuadro de diálogo, seleccione las tablas que se incluirán.

Seleccione Confirmar para generar el modelo de Direct Lake. El modelo se guarda automáticamente en el área de trabajo en función del nombre del almacén de lago de datos y, después, se abre el modelo.

Seleccione Abrir modelo de datos para abrir la experiencia de modelado web donde puede agregar relaciones de tabla y medidas DAX.

Cuando haya terminado de agregar relaciones y medidas DAX, puede crear informes, crear un modelo compuesto y consultar el modelo a través de puntos de conexión XMLA de la misma manera que cualquier otro modelo.