Obtención de datos del centro en tiempo real (versión preliminar)
En este artículo, aprenderás a obtener datos de una secuencia de evento existente en una tabla nueva o existente.
Importante
Esta característica se encuentra en versión preliminar.
Nota:
Actualmente, el centro en tiempo real solo admite secuencias de eventos como origen. El centro en tiempo real está actualmente en versión preliminar.
Requisitos previos
- Un área de trabajo con una capacidad habilitada para Microsoft Fabric
- Una base de datos KQL con permisos de edición
- Un eventstream con un origen de datos
Source
Para obtener datos del centro en tiempo real, debes seleccionar una secuencia en tiempo real del centro de datos en tiempo real como origen de datos. Puedes seleccionar centro en tiempo real de las siguientes maneras:
En la cinta inferior de la base de datos KQL:
En el menú desplegable Obtener datos, en Continuo, selecciona Centro en tiempo real (versión preliminar).
Selecciona Obtener datos y, a continuación, en la ventana Obtener datos, selecciona una secuencia en la sección Centro en tiempo real.

Selecciona un flujo de datos en la lista Flujo del centro en tiempo real.

Configurar
Seleccione una tabla de destino. Si desea ingerir datos en una nueva tabla, seleccione + Nueva tabla y escriba un nombre de tabla.
Nota:
Los nombres de tabla pueden tener hasta 1024 caracteres, entre los que se incluyen espacios, alfanuméricos, guiones y caracteres de subrayado. No se admiten caracteres especiales.
En Configurar el origen de datos, rellena los valores mediante la información de la tabla siguiente. Parte de la información de configuración se rellena automáticamente desde la secuencia de eventos.

Configuración Descripción Área de trabajo Ubicación del área de trabajo de tu secuencia de datos. El nombre del área de trabajo se rellena automáticamente. Nombre de eventstream El nombre del eventstream. El nombre de la secuencia de eventos se rellena automáticamente. Nombre de la conexión de datos Nombre que se usa para hacer referencia y administrar la conexión de datos en el área de trabajo. El nombre de la conexión de datos se rellena automáticamente. También, puede escribir un nombre nuevo. El nombre solo puede contener caracteres alfanuméricos, guiones y puntos, y tener hasta 40 caracteres de longitud. Procesar evento antes de la ingesta en Eventstream Esta opción permite configurar el procesamiento de datos antes de ingerir datos en la tabla de destino. Si está seleccionado, continuará el proceso de ingesta de datos en Eventstream. Para obtener más información, consulte Procesar evento antes de la ingesta en Eventstream. Filtros avanzados Compresión Compresión de datos de los eventos, como procede del centro. Las opciones son None (valor predeterminado) o compresión Gzip. Propiedades del sistema de eventos Si hay varios registros por cada mensaje de evento, las propiedades del sistema se agregan al primero de ellos. Para más información, consulte Propiedades del sistema de eventos. Fecha de inicio de recuperación de eventos La conexión de datos recupera los eventos existentes creados desde la fecha de inicio de la recuperación de eventos. Solo puede recuperar eventos retenidos por el centro en función de su período de retención. La zona horaria es UTC. Si no se especifica ninguna hora, la hora predeterminada es la hora en la que se crea la conexión de datos. Seleccione Siguiente.

Procesar evento antes de la ingesta en Eventstream
La opción Evento de proceso antes de la ingesta en Eventstream permite procesar los datos antes de ingerirlos en la tabla de destino. Con esta opción, el proceso de obtención de datos continúa sin problemas en Eventstream, con la tabla de destino y los detalles del origen de datos rellenados automáticamente.
Para procesar el evento antes de la ingesta en Eventstream:
En la pestaña Configurar, seleccione Procesar evento antes de la ingesta en Eventstream.
En el cuadro de diálogo Procesar eventos en Eventstream, seleccione Continuar en Eventstream.
Importante
Al seleccionar Continuar en Eventstream finaliza el proceso de obtención de datos en inteligencia en tiempo real y continúa en Eventstream con la tabla de destino y los detalles del origen de datos rellenados automáticamente.

En Eventstream, seleccione el nodo de destino de la base de datos KQL y, en el panel Base de datos de KQL, compruebe que está seleccionado Procesar evento antes de la ingesta y que los detalles de destino son correctos.
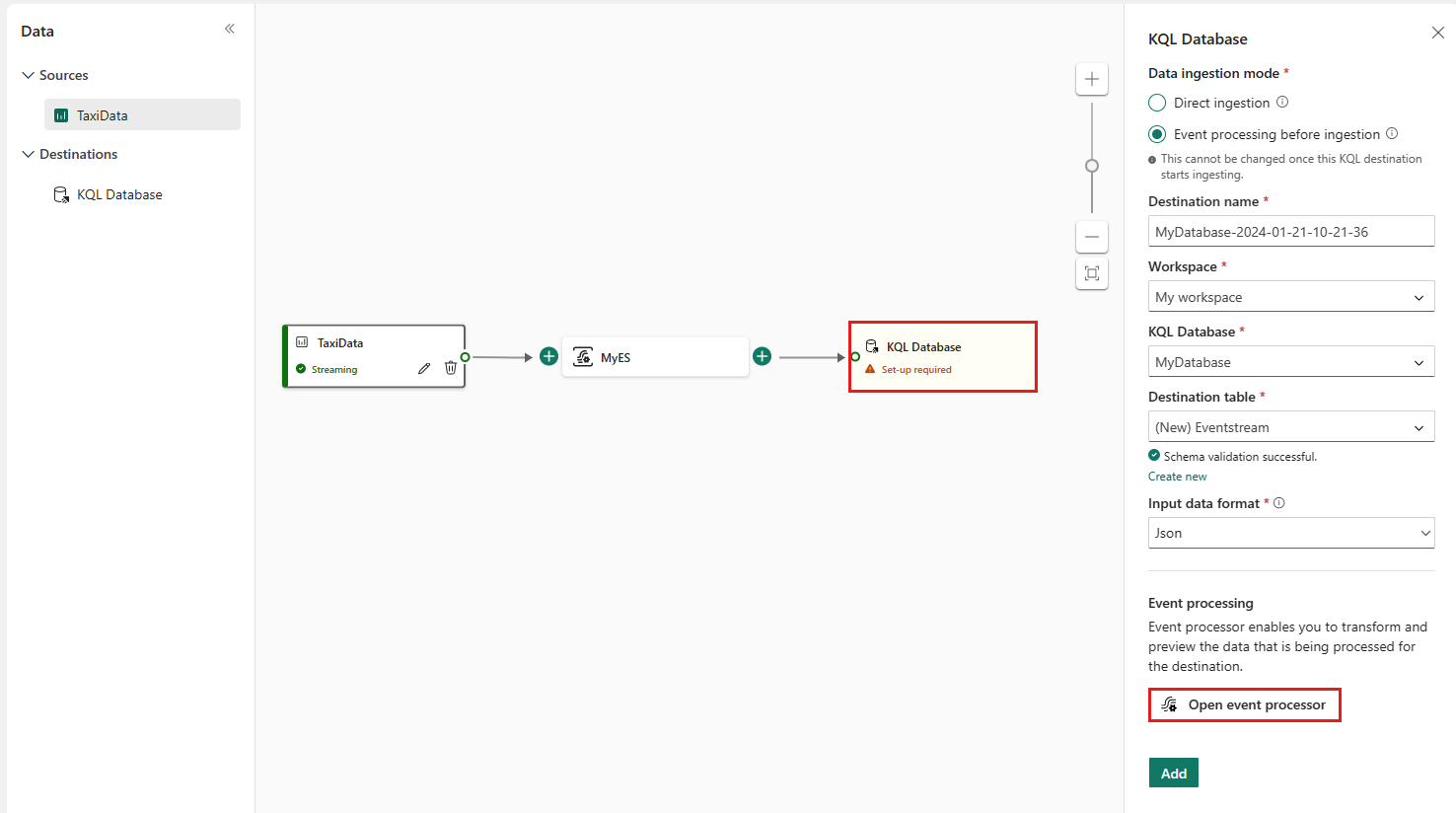
Seleccione Abrir procesador de eventos para configurar el procesamiento de datos y, a continuación, seleccione Guardar. Para obtener más información, consulte Procesamiento de datos de eventos con el editor del procesador de eventos.
De nuevo en el panel Base de datos KQL, seleccione Agregar para completar la configuración del nodo de destino de la Base de datos KQL.
Compruebe que los datos se ingieren en la tabla de destino.


Nota:
El evento de proceso antes de la ingesta en el proceso Eventstream está completo y no se requieren los pasos restantes de este artículo.
Inspeccionar
La pestaña Inspeccionar se abre con una vista previa de los datos.
Para completar el proceso de ingesta, seleccione Finalizar.

Opcionalmente:
- Seleccione Visor de comandos para ver y copiar los comandos automáticos generados a partir de los valores que haya introducido.
- Cambie el formato de datos inferido automáticamente seleccionando el formato deseado en la lista desplegable. Los datos se leen desde el centro en forma de objetos EventData. Los formatos admitidos son Avro, Apache Avro, CSV, JSON, ORC, Parquet, PSV, RAW, SCsv, SOHsv, TSV, TXT y TSVE.
- Editar columnas.
- Explore las Opciones avanzadas basadas en el tipo de datos.
Editar columnas
Nota:
- En el caso de formatos tabulares (CSV, TSV, PSV), no se puede asignar una columna dos veces. Para asignar a una columna existente, elimine primero la nueva columna.
- No se puede cambiar un tipo de columna existente. Si intenta asignar a una columna con un formato diferente, puede acabar con columnas vacías.
Los cambios que pueda realizar a una tabla dependerán de los siguientes parámetros:
- El tipo de tabla es nuevo o existente
- El tipo de asignación es nuevo o existente
| Tipo de tabla. | Tipo de asignación | Ajustes disponibles |
|---|---|---|
| Tabla nueva | Asignación nueva | Cambio del nombre de columna, cambio del tipo de datos, cambio del origen de datos, la asignación de transformaciones, adición de columna, eliminación de columna |
| Tabla existente | Asignación nueva | Adición de columna (en la que puede cambiar el tipo de datos, cambiar el nombre y actualizar) |
| Tabla existente | Asignación existente | None |

Asignación de transformaciones
Algunas de las asignaciones de formato de datos (Parquet, JSON y Avro) admiten transformaciones sencillas en el momento de la ingesta. Para aplicar la asignación de transformaciones, cree o actualice una columna en la ventana Editar columnas.
La asignación de transformaciones se puede realizar en una columna de tipo string o datetime y un origen con un tipo de datos int o long. Las asignaciones de transformaciones que se admiten son:
- DateTimeFromUnixSeconds
- DateTimeFromUnixMilliseconds
- DateTimeFromUnixMicroseconds
- DateTimeFromUnixNanoseconds
Opciones avanzadas basadas en el tipo de datos
Tabular (CSV, TSV, PSV):
Los datos tabulares no incluyen necesariamente los nombres de columna que se usan para asignar datos de origen a las columnas existentes. Para usar la primera fila como nombres de columna, activa La primera fila es el encabezado de la columna.

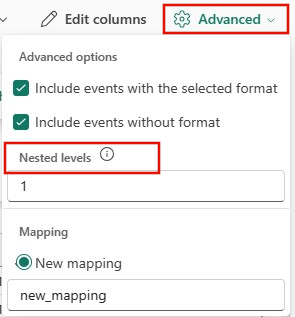
JSON:
Para determinar la división de columnas de datos JSON, seleccione Opciones avanzadas>Niveles anidados, de 1 a 100.
Resumen
En la ventana Preparación de datos, los tres pasos se marcan con marcas de verificación verdes cuando la ingesta de datos se haya completado correctamente. Puede seleccionar una tarjeta a la que consultar, quitar los datos ingeridos o ver un panel del resumen de ingesta. Seleccione Cerrar para cerrar la ventana.

Contenido relacionado
- Para administrar la base de datos, consulte Administrar datos
- Para crear, almacenar y exportar consultas, consulte Consulta de datos en un conjunto de consultas KQL
- Para obtener datos de un nuevo centro de eventos, consulta Obtención de datos de un nuevo centro de eventos