Muestreo de alta densidad en los gráficos de dispersión de Power BI
El algoritmo de muestreo de Power BI mejora la forma en que los gráficos de dispersión representan los datos de alta densidad.
Por ejemplo, podría crear un gráfico de dispersión de la actividad de ventas de la organización, donde cada almacén tiene decenas de miles de puntos de datos de cada año. Un gráfico de dispersión de dicha información realizará un muestreo de los datos a partir de una representación significativa de los datos para ilustrar cómo se producen las ventas a través del tiempo. Los detalles del muestreo de datos de alta densidad se describen en este artículo.

Nota:
El algoritmo de muestreo de alta densidad que se describe en este artículo está disponible en los gráficos de dispersión, tanto para Power BI Desktop como para el servicio Power BI.
Modo de funcionamiento de los gráficos de dispersión de alta densidad
Anteriormente, Power BI seleccionaba una colección de puntos de datos de muestra en el intervalo completo de datos subyacentes de manera determinista para crear un gráfico de dispersión. En concreto, Power BI seleccionaría la primera y última fila de datos de la serie del gráfico de dispersión y a continuación dividiría las filas restantes uniformemente para representar un total de 3500 puntos de datos en el gráfico de dispersión. Por ejemplo, si la muestra tiene 35 000 filas, se seleccionan la primera y la última fila para trazar, y se traza cada décima fila (35 000/10 = cada décima fila = 3500 puntos de datos). Anteriormente, los valores NULL o los puntos que no se podían trazar (por ejemplo, los valores de texto) de la serie de datos no se mostraban y, por tanto, no se tenían en cuenta al generar el objeto visual. Con este tipo de muestreo, la densidad percibida del gráfico de dispersión también se basaba en los puntos de datos representativos y, por tanto, la densidad visual implícita era una circunstancia de los puntos de la muestra y no de la colección completa de los datos subyacentes.
Cuando se habilita el muestreo de alta densidad, Power BI implementa un algoritmo que elimina los puntos que se superponen y se asegura de que se puedan alcanzar los puntos del objeto visual al interactuar con este. El algoritmo también garantiza que todos los puntos del conjunto de datos se representan en el objeto visual, lo que proporciona contexto para el significado de los puntos seleccionados, en lugar de simplemente trazar una muestra representativa.
Por definición, se muestrean los datos de alta densidad para crear visualizaciones que responden a interactividad. Si hay demasiados puntos de datos en un objeto visual, estos pueden provocar que se ralentice y disminuya la visibilidad de las tendencias. La forma en la que se muestrean los datos impulsa la creación del algoritmo de muestreo, para proporcionar la mejor experiencia de visualización y asegurarse de que todos los datos están representados. En Power BI, el algoritmo se ha mejorado para proporcionar la mejor combinación de capacidad de respuesta, representación y conservación de los puntos importantes en el conjunto de datos.
Nota
Los gráficos de dispersión que usan el algoritmo de muestreo de alta densidad se trazan mejor en objetos visuales cuadrados, al igual que ocurre con todos los gráficos de dispersión.
Modo de funcionamiento del algoritmo de muestreo de gráficos de dispersión
El algoritmo de muestreo de alta densidad para gráficos de dispersión emplea métodos que capturan y representan los datos subyacentes de forma más eficaz, y elimina los puntos que se superponen. Lo hace comenzando con un radio pequeño para cada punto de datos (el tamaño del círculo visual de un punto dado en la visualización). A continuación, aumenta el radio de todos los puntos de datos. Cuando se superponen dos (o más) puntos de datos, un círculo único (con el tamaño del radio aumentado) representa los puntos de datos superpuestos. El algoritmo continúa aumentando el radio de los puntos de datos hasta que dicho valor del radio da como resultado un número razonable de puntos de datos (3500) para mostrar en el gráfico de dispersión.
Los métodos de este algoritmo garantizan que los valores atípicos se representarán en el objeto visual resultante. El algoritmo también respeta la escala a la hora de determinar la superposición, de modo que se visualicen las escalas exponenciales con fidelidad en los puntos visualizados subyacentes.
El algoritmo también conserva la forma general del gráfico de dispersión.
Nota
Cuando se usa el algoritmo de muestreo de alta densidad para gráficos de dispersión, la distribución precisa de los datos es el objetivo, no la densidad visual implícita. Por ejemplo, puede ver un gráfico de dispersión con muchos círculos que se solapan (densidad) en una zona determinada e imaginar que muchos puntos de datos deben estar agrupados allí. Dado que el algoritmo de muestreo de alta densidad puede usar un círculo para representar muchos puntos de datos, la densidad visual implícita o la "agrupación" no se mostrarán. Para obtener más detalles de una zona determinada, puede utilizar controles deslizantes para acercar la vista.
Además, se omiten los puntos de datos que no se pueden trazar (por ejemplo, los valores NULL o valores de texto), por lo que se selecciona otro valor que se puede trazar. Así, se garantiza aún más que la forma real del gráfico de dispersión se mantenga.
Cuándo se usa el algoritmo estándar para los gráficos de dispersión
Hay circunstancias en las que el muestreo de alta densidad no se puede aplicar a un gráfico de dispersión y se usa el algoritmo original. Estas circunstancias son:
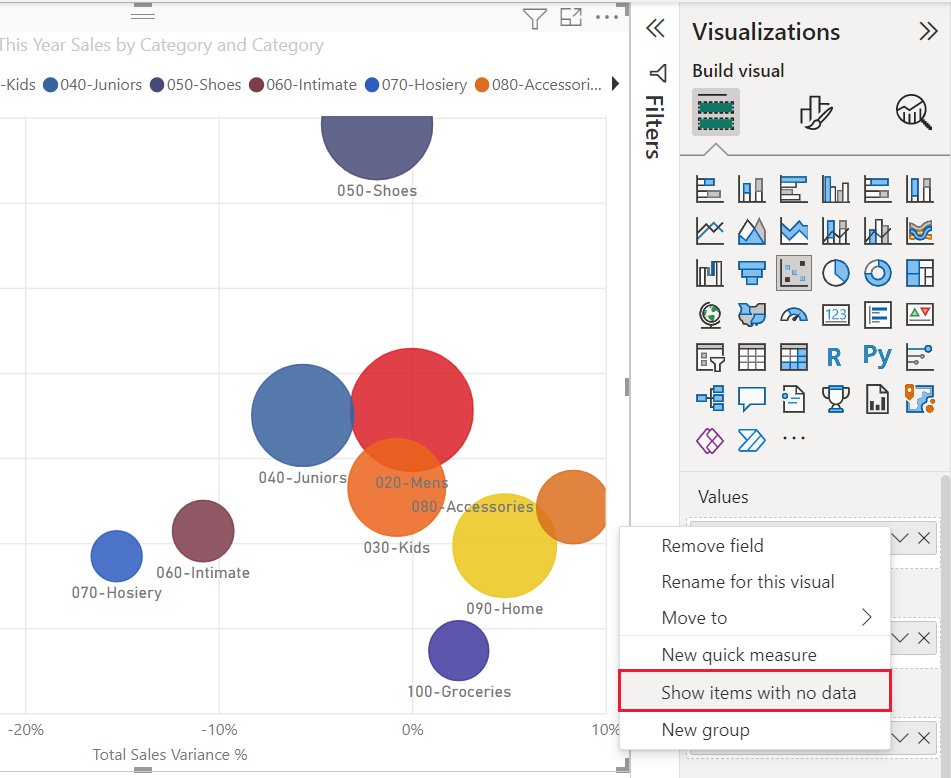
Si hace clic con el botón derecho en un valor en Valores y lo establece en Mostrar elementos sin datos en el menú, el gráfico de dispersión volverá al algoritmo original.
Cualquier valor del campo Eje de reproducción da como resultado que el gráfico de dispersión vuelva al algoritmo original.
Si faltan los ejes X e Y en un gráfico de dispersión, el gráfico vuelve al algoritmo original.
El uso de una línea de relación en el panel Análisis hace que el gráfico se revierte al algoritmo original.

Activación del muestreo de alta densidad para un gráfico de dispersión
Para cambiar el muestreo de alta densidad a Activado, seleccione un gráfico de dispersión, vaya al panel Formato visual, expanda la tarjeta General y, cerca de la parte inferior de la tarjeta, deslice el control deslizante Muestreo de alta densidad a Activar.

Nota:
Una vez que el control deslizante está activado, Power BI intentará usar el algoritmo Muestreo de alta densidad siempre que sea posible. Cuando el algoritmo no se puede usar (por ejemplo, si se coloca un valor en el eje Reproducir), el control deslizante permanece en la posición Activado aunque el gráfico se haya revertido al algoritmo estándar. Si después quita un valor del eje Reproducir (o cambian las condiciones para habilitar el uso del algoritmo de muestreo de alta densidad), el gráfico usará automáticamente el muestreo de alta densidad para ese gráfico porque la característica está activa.
Nota
Los puntos de datos se agrupan o se seleccionan por el índice. Tener una leyenda no afecta al muestreo del algoritmo. Solo afecta al orden del objeto visual.
Consideraciones y limitaciones
El algoritmo de muestreo de alta densidad es una mejora importante para Power BI. Sin embargo, el algoritmo de muestreo de alta densidad solo funciona con conexiones dinámicas a modelos basados en el servicio Power BI, modelos importados o DirectQuery.