Procedimientos recomendados para diseñar y desarrollar flujos de datos complejos
Si el flujo de datos que está desarrollando se está volviendo más grande y más complejo, estas son algunas cosas que puede hacer para mejorar el diseño original.
Dividirlo en varios flujos de datos
No hacerlo todo en un flujo de datos. Un flujo de datos único y complejo no solo hace que el proceso de transformación de datos sea más largo, sino que también dificulta la comprensión y reutilización del flujo de datos. La separación del flujo de datos en varios flujos de datos se puede realizar separando tablas en diferentes flujos de datos o incluso una tabla en varios flujos de datos. Puede usar el concepto de una tabla calculada o una tabla vinculada para crear parte de la transformación en un flujo de datos y reutilizarla en otros flujos de datos.
Dividir los flujos de datos de transformación de datos y los flujos de datos de almacenamiento provisional o extracción
Tener algunos flujos de datos solo para extraer datos (es decir, flujos de datos de almacenamiento provisional) y otros solo para transformar datos es útil no solo para crear una arquitectura multicapa, también para reducir la complejidad de los flujos de datos. Algunos pasos simplemente extraen datos del origen de datos, como obtener datos, navegación y cambios en el tipo de datos. Al separar los flujos de datos de almacenamiento provisional y los flujos de datos de transformación, los flujos de datos son más sencillos de desarrollar.
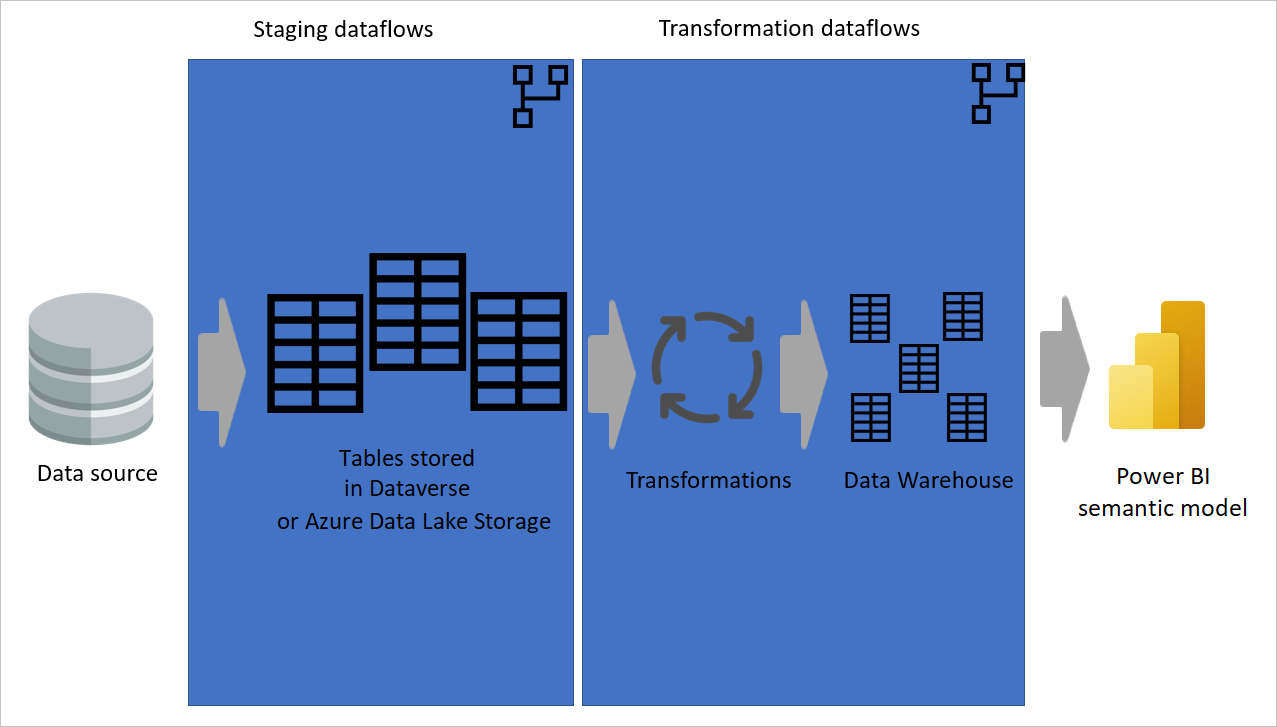
Imagen que muestra la extracción de datos de un origen de datos a flujos de datos de almacenamiento provisional, donde las tablas se almacenan en Dataverse o Azure Data Lake Storage. A continuación, los datos se mueven a flujos de datos de transformación donde se transforman y convierten en la estructura del almacenamiento de datos. A continuación, los datos se mueven al modelo semántico.
Usar funciones personalizadas
Las funciones personalizadas son útiles en escenarios en los que es necesario realizar un determinado número de pasos para una serie de consultas de orígenes diferentes. Las funciones personalizadas se pueden desarrollar a través de la interfaz gráfica en el editor de Power Query o mediante un script de M. Las funciones se pueden reutilizar en un flujo de datos en tantas tablas como sea necesario.
Tener una función personalizada ayuda a tener solo una versión del código fuente, por lo que no es necesario duplicar el código. Como resultado, mantener la lógica de transformación de Power Query y todo el flujo de datos es mucho más fácil. Para obtener más información, vaya a la siguiente entrada de blog: Custom Functions Made Easy in Power BI Desktop (Funciones personalizadas fáciles en Power BI Desktop).
Nota:
A veces, puede recibir una notificación que indica que se requiere una capacidad prémium para actualizar un flujo de datos con una función personalizada. Puede omitir este mensaje y volver a abrir el editor de flujo de datos. Esto suele resolver el problema a menos que la función haga referencia a una consulta "habilitada para carga".
Colocar consultas en carpetas
El uso de carpetas para consultas ayuda a agrupar consultas relacionadas. Al desarrollar el flujo de datos, dedique un poco más de tiempo a organizar las consultas en carpetas que tengan sentido. Con este enfoque, podrá encontrar las consultas más fácilmente en el futuro y mantener el código resultará mucho más fácil.
Usar tablas calculadas
Las tablas calculadas no solo hacen que el flujo de datos sea más comprensible, sino que también proporcionan un mejor rendimiento. Cuando se usa una tabla calculada, las demás tablas a las que se hace referencia obtienen datos de una tabla "ya procesada y almacenada". La transformación es mucho más sencilla y rápida.
Aprovechar el motor de proceso mejorado
En el caso de los flujos de datos desarrollados en el portal de administración de Power BI, asegúrese de usar el motor de proceso mejorado realizando primero combinaciones y transformaciones de filtro en una tabla calculada antes de realizar otros tipos de transformaciones.
Dividir muchos pasos en varias consultas
Es difícil realizar un seguimiento de un gran número de pasos en una tabla. En su lugar, debe dividir los grandes números de pasos en varias tablas. Puede usar Habilitar carga para otras consultas y deshabilitarlas si son consultas intermedias y solo cargar la tabla final a través del flujo de datos. Cuando tiene varias consultas con pasos más pequeños en cada una, es más fácil usar el diagrama de dependencias y realizar un seguimiento de cada consulta para realizar una investigación más detallada, en lugar de realizar cientos de pasos en una consulta.
Adición de propiedades para consultas y pasos
La documentación es la clave para tener código fácil de mantener. En Power Query, puede agregar propiedades a las tablas y también a los pasos. El texto que agrega en las propiedades se muestra como información sobre herramientas al mantener el puntero sobre esa consulta o paso. Esta documentación le ayuda a mantener el modelo en el futuro. Con un vistazo a una tabla o paso, puede comprender lo que está sucediendo allí, en lugar de tener que repensar y recordar lo que ha hecho en ese paso.
Asegurarse de que la capacidad está en la misma región
Los flujos de datos no admiten actualmente varios países o regiones. La capacidad Premium debe estar en la misma región que el inquilino de Power BI.
Separar orígenes locales de orígenes en la nube
Se recomienda crear un flujo de datos independiente para cada tipo de origen, como local, nube, SQL Server, Spark y Dynamics 365. La separación de flujos de datos por tipo de origen facilita la solución de problemas rápida y evita límites internos al actualizar los flujos de datos.
Separar flujos de datos en función de la actualización programada necesaria para las tablas
Si tiene una tabla de transacciones de ventas que se actualiza en el sistema de origen cada hora y una tabla de asignación de productos que se actualiza cada semana, divida estas dos tablas en dos flujos de datos con diferentes programaciones de actualización de datos.
Evitar la programación de la actualización de tablas vinculadas en la misma área de trabajo
Si regularmente se produce un bloqueo en los flujos de datos que contienen tablas vinculadas, podría deberse a que hay un flujo de datos dependiente en la misma área de trabajo bloqueada durante la actualización del flujo de datos. Este bloqueo proporciona precisión transaccional y garantiza que ambos flujos de datos se actualicen correctamente, pero puede impedirle realizar cambios.
Si configura una programación independiente para el flujo de datos vinculado, los flujos de datos se pueden actualizar innecesariamente e impedir que realice cambios en el flujo de datos. Hay dos recomendaciones para evitar este problema:
- No establezca una programación de actualización para un flujo de datos vinculado en la misma área de trabajo que el flujo de datos de origen.
- Si desea configurar una programación de actualización por separado y evitar el comportamiento de bloqueo, mueva el flujo de datos a un área de trabajo independiente.