Reconocimiento de voz en Xamarin.iOS
En este artículo se presenta la nueva API de voz y se muestra cómo implementarla en una aplicación de Xamarin.iOS para admitir el reconocimiento continuo de voz y transcribir la voz (de secuencias de audio en directo o grabadas) en texto.
Tras la llegada de iOS 10, Apple ha lanzado la API de reconocimiento de voz, que permite que una aplicación iOS admita el reconocimiento de voz continuo y transcriba voz (de flujos de audio en directo o grabados) a texto.
Según Apple, la API de reconocimiento de voz tiene las siguientes características y ventajas:
- Altamente preciso
- Estado del arte
- Fácil de usar
- Fast
- Admite varios idiomas
- Respeta la privacidad del usuario
Funcionamiento del reconocimiento de voz
El reconocimiento de voz se implementa en una aplicación de iOS mediante la adquisición de audio en directo o previamente grabado (en cualquiera de los idiomas hablados que admite la API) y su paso a un reconocedor de voz que devuelve una transcripción de texto sin formato de las palabras habladas.

Dictado de teclado
Cuando la mayoría de los usuarios piensan en reconocimiento de voz en un dispositivo iOS, piensan en el asistente de voz de Siri integrado, que se lanzó junto con dictado de teclado en iOS 5 con el iPhone 4S.
El dictado de teclado es compatible con cualquier elemento de interfaz que admita TextKit (como UITextField o UITextArea) y el usuario activa haciendo clic en el botón Dictado (directamente a la izquierda de la barra espaciadora) en el teclado virtual de iOS.
Apple ha publicado las siguientes estadísticas de dictado de teclado (recopiladas desde 2011):
- El dictado de teclado se ha usado ampliamente desde que se lanzó en iOS 5.
- Aproximadamente 65 000 aplicaciones la usan al día.
- Acerca de un tercero de todos los dictados de iOS se realiza en una aplicación de terceros.
El dictado de teclado es extremadamente fácil de usar, ya que no requiere ningún esfuerzo en la parte del desarrollador, aparte del uso de un elemento de interfaz TextKit en el diseño de la interfaz de usuario de la aplicación. El dictado de teclado también tiene la ventaja de no requerir solicitudes de privilegios especiales de la aplicación antes de que se pueda usar.
Las aplicaciones que usan las nuevas API de reconocimiento de voz requerirán que el usuario conceda permisos especiales, ya que el reconocimiento de voz requiere la transmisión y el almacenamiento temporal de datos en los servidores de Apple. Consulte nuestra documentación sobre Mejoras de seguridad y privacidad para obtener más información.
Aunque el dictado de teclado es fácil de implementar, viene con varias limitaciones y desventajas:
- Requiere el uso de un campo de entrada de texto y la presentación de un teclado.
- Funciona solo con entrada de audio en vivo y la aplicación no tiene control sobre el proceso de grabación de audio.
- No proporciona control sobre el idioma que se usa para interpretar la voz del usuario.
- No hay forma de que la aplicación sepa si el botón Dictado está disponible incluso para el usuario.
- La aplicación no puede personalizar el proceso de grabación de audio.
- Proporciona un conjunto muy superficial de resultados que carece de información, como el tiempo y la confianza.
API de reconocimiento de voz
Novedad de iOS 10, Apple ha lanzado la API de reconocimiento de voz, que proporciona una manera más eficaz de implementar un reconocimiento de voz para una aplicación iOS. Esta API es la misma que Apple usa para alimentar Siri y Dictado de teclado y es capaz de proporcionar una transcripción rápida con precisión de última generación.
Los resultados proporcionados por API de reconocimiento de voz se personalizan de forma transparente para los usuarios individuales, sin que la aplicación tenga que recopilar o acceder a los datos de usuario privados.
La API de reconocimiento de voz proporciona resultados a la aplicación que realiza la llamada casi en tiempo real, ya que el usuario habla y proporciona más información sobre los resultados de la traducción que el texto. Entre ellas se incluyen las siguientes:
- Varias interpretaciones de lo que dijo el usuario.
- Niveles de confianza para las traducciones individuales.
- Información de tiempo.
Como se ha indicado anteriormente, el audio para la traducción se puede proporcionar mediante una fuente en vivo o desde un origen previamente grabado y en cualquiera de los más de 50 idiomas y dialectos admitidos por iOS 10.
La API de reconocimiento de voz se puede usar en cualquier dispositivo iOS que ejecute iOS 10 y, en la mayoría de los casos, requiere una conexión a Internet activa, ya que la mayor parte de las traducciones tiene lugar en los servidores de Apple. Dicho esto, algunos dispositivos iOS más recientes admiten siempre activados, la traducción en el dispositivo de idiomas específicos.
Apple ha incluido una API de disponibilidad para determinar si hay un idioma determinado disponible para la traducción en el momento actual. La aplicación debe usar esta API en lugar de probar la conectividad a Internet directamente.
Como se indicó anteriormente en la sección Dictado de teclado, el reconocimiento de voz requiere la transmisión y el almacenamiento temporal de datos en los servidores de Apple a través de Internet, y como tal, la aplicación debe solicitar el permiso del usuario para realizar el reconocimiento incluyendo la clave NSSpeechRecognitionUsageDescription en su archivo Info.plist y llamando al método SFSpeechRecognizer.RequestAuthorization.
En función del origen del audio que se usa para el reconocimiento de voz, es posible que se requieran otros cambios en el archivo Info.plist de la aplicación. Consulte nuestra documentación sobre Mejoras de seguridad y privacidad para obtener más información.
Adopción del reconocimiento de voz en una aplicación
Hay cuatro pasos principales que el desarrollador debe realizar para adoptar el reconocimiento de voz en una aplicación de iOS:
- Proporcione una descripción de uso en el archivo
Info.plistde la aplicación mediante la claveNSSpeechRecognitionUsageDescription. Por ejemplo, una aplicación de cámara podría incluir la siguiente descripción: "Esto le permite tomar una foto simplemente diciendo la palabra "queso". - Solicite autorización llamando al método
SFSpeechRecognizer.RequestAuthorizationpara presentar una explicación (proporcionada en la clave deNSSpeechRecognitionUsageDescriptionanterior) de por qué la aplicación quiere acceso de reconocimiento de voz al usuario en un cuadro de diálogo y permitirle aceptar o rechazar. - Cree una solicitud de reconocimiento de voz:
- Para el audio grabado previamente en el disco, use la clase
SFSpeechURLRecognitionRequest. - Para el audio en directo (o el audio de la memoria), use la clase
SFSPeechAudioBufferRecognitionRequest.
- Para el audio grabado previamente en el disco, use la clase
- Pase la solicitud de reconocimiento de voz a un reconocedor de voz (
SFSpeechRecognizer) para comenzar el reconocimiento. La aplicación puede mantenerse opcionalmente en el devueltoSFSpeechRecognitionTaskpara supervisar y realizar un seguimiento de los resultados del reconocimiento.
Estos pasos se tratarán en detalle a continuación.
Proporcionar una descripción de uso
Para proporcionar la clave NSSpeechRecognitionUsageDescription necesaria en el archivo Info.plist, haga lo siguiente:
Haga doble clic en el archivo
Info.plistpara abrirlo para editarlo.Cambie a la vista Código fuente:

Haga clic en Agregar nueva entrada, escriba
NSSpeechRecognitionUsageDescriptionpara la Propiedad,Stringpara el Tipo y una Descripción de uso como Valor. Por ejemplo:
Si la aplicación controlará la transcripción de audio en vivo, también requerirá una descripción del uso del micrófono. Haga clic en Agregar nueva entrada, escriba
NSMicrophoneUsageDescriptionpara la Propiedad,Stringpara el Tipo y una descripción de uso como Valor. Por ejemplo: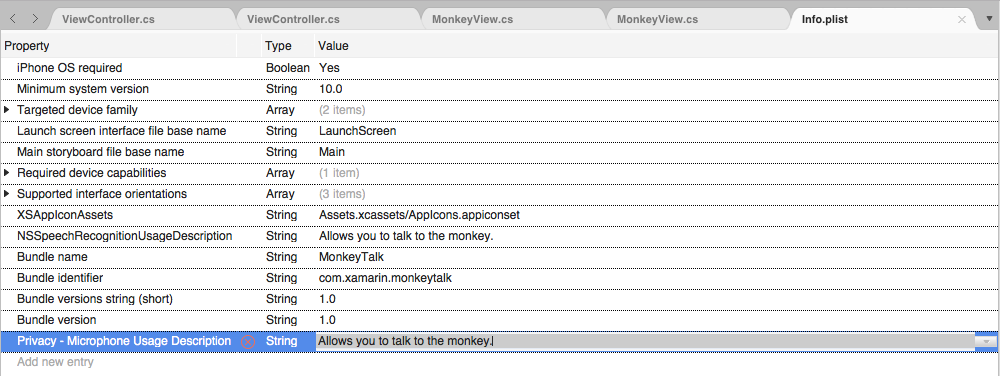
Guarde los cambios en el archivo.





Importante
Si no se proporciona cualquiera de las claves anteriores Info.plist (NSSpeechRecognitionUsageDescription o NSMicrophoneUsageDescription) se puede producir un error en la aplicación sin advertencia al intentar acceder al reconocimiento de voz o al micrófono para el audio en directo.
Solicitud de autorización
Para solicitar la autorización de usuario necesaria que permita a la aplicación acceder al reconocimiento de voz, edite la clase principal View Controller y agregue el código siguiente:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
El método RequestAuthorization de la clase SFSpeechRecognizer solicitará permiso al usuario para acceder al reconocimiento de voz mediante el motivo por el que el desarrollador ha proporcionado en la clave NSSpeechRecognitionUsageDescription del archivo Info.plist.
Se devuelve un SFSpeechRecognizerAuthorizationStatus resultado a la rutina de devolución de llamada del método RequestAuthorization que se puede usar para tomar medidas en función del permiso del usuario.
Importante
Apple sugiere esperar hasta que el usuario haya iniciado una acción en la aplicación que requiere reconocimiento de voz antes de solicitar este permiso.
Reconocimiento de voz previamente grabada
Si la aplicación quiere reconocer la voz de un archivo WAV o MP3 previamente grabado, puede usar el código siguiente:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
Al examinar este código con detalle, primero intenta crear un reconocedor de voz (SFSpeechRecognizer). Si el idioma predeterminado no se admite para el reconocimiento de voz, null se devuelve y se cierran las funciones.
Si Speech Recognizer está disponible para el idioma predeterminado, la aplicación comprueba si está disponible actualmente para el reconocimiento mediante la propiedad Available. Por ejemplo, es posible que el reconocimiento no esté disponible si el dispositivo no tiene una conexión a Internet activa.
Se crea un SFSpeechUrlRecognitionRequest a partir de la ubicación NSUrl del archivo grabado previamente en el dispositivo iOS y se entrega al reconocedor de voz para procesar con una rutina de devolución de llamada.
Cuando se llama a la devolución de llamada, si NSError no null se ha producido un error que se debe controlar. Dado que el reconocimiento de voz se realiza de forma incremental, se puede llamar a la rutina de devolución de llamada más de una vez, por lo que la SFSpeechRecognitionResult.Final propiedad se prueba para ver si la traducción está completa y se escribe la mejor versión de la traducción (BestTranscription).
Reconocimiento de Live Speech
Si la aplicación quiere reconocer la voz en directo, el proceso es muy similar al reconocimiento de la voz previamente grabada. Por ejemplo:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
Al examinar este código con detalle, se crean varias variables privadas para controlar el proceso de reconocimiento:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
Usa AV Foundation para grabar audio que se pasará aSFSpeechAudioBufferRecognitionRequest para controlar la solicitud de reconocimiento:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
La aplicación intenta iniciar la grabación y se controlan los errores si no se puede iniciar la grabación:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
La tarea de reconocimiento se inicia y se mantiene un identificador en la tarea de reconocimiento (SFSpeechRecognitionTask):
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
La devolución de llamada se usa de forma similar a la usada anteriormente en voz grabada previamente.
Si el usuario interrumpe la grabación, se informa tanto al motor de audio como a la solicitud de reconocimiento de voz:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
Si el usuario cancela el reconocimiento, se informa a la tarea Motor de audio y reconocimiento:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
Es importante llamar a RecognitionTask.Cancel si el usuario cancela la traducción para liberar memoria y el procesador del dispositivo.
Importante
Si no se proporcionan las NSSpeechRecognitionUsageDescription teclas o NSMicrophoneUsageDescription Info.plist , se produce un error en la aplicación sin advertencia al intentar acceder al reconocimiento de voz o al micrófono para el audio en directo (var node = AudioEngine.InputNode;). Consulte la sección Proporcionar una descripción de uso anterior para obtener más información.
Límites de reconocimiento de voz
Apple impone las siguientes limitaciones al trabajar con el reconocimiento de voz en una aplicación de iOS:
- El reconocimiento de voz es gratuito para todas las aplicaciones, pero su uso no es ilimitado:
- Los dispositivos iOS individuales tienen un número limitado de reconocimientos que se pueden realizar al día.
- Las aplicaciones serán limitadas globalmente en función de las solicitudes por día.
- La aplicación debe estar preparada para controlar los errores de conexión de red de Reconocimiento de voz y límite de frecuencia de uso.
- El reconocimiento de voz puede tener un alto costo en el drenaje de la batería y el tráfico de red elevado en el dispositivo iOS del usuario, debido a esto, Apple impone un límite de duración de audio estricto de aproximadamente un minuto de voz máximo.
Si una aplicación alcanza de forma rutinaria sus límites de velocidad, Apple le pide al desarrollador que se comunique con ellos.
Consideraciones de privacidad y facilidad de uso
Apple tiene la siguiente sugerencia para ser transparente y respetar la privacidad del usuario al incluir el reconocimiento de voz en una aplicación de iOS:
- Al grabar la voz del usuario, asegúrese de indicar claramente que la grabación está teniendo lugar en la interfaz de usuario de la aplicación. Por ejemplo, la aplicación podría reproducir un sonido de "grabación" y mostrar un indicador de grabación.
- No use reconocimiento de voz para información confidencial del usuario, como contraseñas, datos de estado o información financiera.
- Mostrar los resultados del reconocimiento antes de actuar en ellos. Esto no solo proporciona comentarios sobre lo que hace la aplicación, sino que permite al usuario controlar los errores de reconocimiento a medida que se realizan.
Resumen
En este artículo se ha presentado la nueva API de Voz y se ha mostrado cómo implementarla en una aplicación de Xamarin.iOS para admitir el reconocimiento continuo de voz y transcribir la voz (de secuencias de audio grabadas o en directo) en texto.