Recursos implementados con Clústeres de macrodatos de SQL Server
Se aplica a: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
En este artículo se describen los recursos que implementa un clúster de macrodatos de SQL Server.
Un clúster de macrodatos implementa pods en función del perfil de implementación. Para obtener más información, vea Configuraciones predeterminadas.
En este artículo se describen los pods implementados con el perfil aks-dev-test-ha y se incluye un grupo de Spark. Consulte Kubernetes para ver los pods implementados en el clúster. En el ejemplo siguiente se devuelve una lista de pods en un espacio de nombres específico.
kubectl get pods -n <namespace>
Reemplace <namespace> por el nombre del clúster de macrodatos.
Para obtener más información, vea Cómo implementar Clústeres de macrodatos de SQL Server en Kubernetes.
En el diagrama siguiente se muestran los componentes implementados en un clúster de macrodatos:
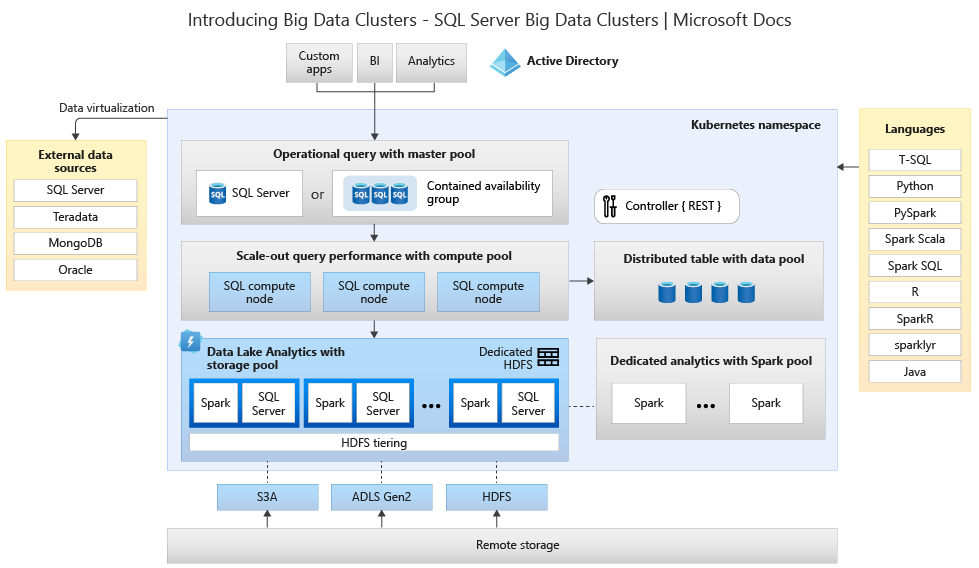
Para obtener información sobre la arquitectura, vea Presentación de Clústeres de macrodatos de SQL Server.
Pods implementados
En la tabla siguiente se enumeran los pods implementados en un clúster de macrodatos.
| Nombre | Área |
|---|---|
control-<nnnn> |
Control |
controldb-<#> |
Control |
controlwd-<nnnn> |
Control |
logsdb-<#> |
Control |
logsui-<nnnn> |
Control |
metricsdb-<#> |
Control |
metricsdc-<nnnn> |
Control |
metricsui-<nnnn> |
Control |
mgmtproxy-<nnnn> |
Control |
zookeeper-<#> |
Control |
dns-<nnnn> |
Control |
master-<#n> |
Instancia principal |
operator-<nnnn> |
Instancia principal |
compute-<#n>-<#m> |
Grupo de proceso |
data-<#>-<#> |
Grupo de datos |
storage-<#>-<#> |
Grupo de almacenamiento |
nmnode-<#>-<#> |
Grupo de almacenamiento |
sparkhead-<#> |
Grupo de almacenamiento |
appproxy-<#m> |
Grupo de aplicaciones |
gateway-<#> |
Servicio de puerta de enlace |
No todos los pods se incluyen en todos los clústeres de macrodatos. Las implementaciones con alta disponibilidad o la integración con Active Directory incluyen pods específicos.
Pods específicos de alta disponibilidad:
operator-<nnnn>zookeeper-<#>
Pods específicos de Active Directory:
dns-<nnnn>
En las secciones siguientes se describen los pods y se enumeran los contenedores de cada pod.
Control
Los pods de control proporcionan el servicio de control.
| Nombre del pod | Count | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|---|
control-# |
1 | ReplicaSet | - controller- security-support- fluentbit |
controldb |
1 | StatefulSet | - mssql-server- fluentbit |
controlwd |
1 | ReplicaSet | - controlwatchdog |
logsdb-# |
1 | StatefulSet | - elasticsearch |
logsui |
1 | ReplicaSet | - kibana |
metricsdb-# |
1 | StatefulSet | - influxdb |
metricsdc |
1 por nodo de Kubernetes. | DaemonSet | - telegraf |
metricsui-nnnn |
1 | ReplicaSet | - grafana |
mgmtproxy-nnnn |
1 | ReplicaSet | - service-proxy- fluentbit |
dns-nnnn |
0 o 1 para la integración de Active Directory | ReplicaSet | - dns- fluentbit |
Instancia principal
master-<#n> es la instancia maestra de SQL Server.
- Administra el grupo de datos a través de DDL.
- Manipula los datos del grupo de datos a través de DML.
- Descarga la ejecución de consultas de análisis en el grupo de datos.
| Nombre del pod | Count | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|---|
master-<#n> |
1 o más para alta disponibilidad. | StatefulSet | - mssql-server- fluentbit- collectd- mssql-ha-supervisor * |
operator* |
0 o 1 para alta disponibilidad | ReplicaSet | - mssql-ha-operator |
* Solo implementaciones de alta disponibilidad. El operador implementa y registra la definición de recursos personalizada para SQL Server y los recursos del grupo de disponibilidad. Cuando se implementa el operador, se registra a sí mismo como un cliente de escucha de notificaciones sobre los recursos de SQL Server que se implementan en el clúster de Kubernetes. mssql-ha-supervisor admite el grupo de disponibilidad.
Cada pod master contiene una instancia de SQL Server. Un implementación de alta disponibilidad incluye tres pods. Cada pod incluye una instancia de SQL Server con bases de datos en un grupo de disponibilidad AlwaysOn de SQL Server.
Incluya pods adicionales en el momento de la implementación, en función de la carga de trabajo.
Grupo de proceso
El grupo de proceso proporciona una instancia de SQL Server para el cálculo.
| Nombre del pod | Count | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|---|
compute-<#n>-<#m> |
1 o más. | StatefulSet | - mssql-server- fluentbit- collectd |
#nidentifica el grupo de proceso.#midentifica el id. de instancia en el grupo.
Las instancias de SQL Server del grupo de proceso no tienen estado. Solo necesitan almacenamiento para tempdb.
Incluya pods adicionales en el momento de la implementación, en función de la carga de trabajo.
Grupo de datos
El grupo de datos proporciona instancias de SQL Server para el almacenamiento y el proceso.
| Nombre del pod | Count | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|---|
data-<#n>-<#m> |
0 o más | StatefulSet | - mssql-server - fluentbit- collectd |
#nidentifica el grupo de datos.#midentifica el id. de instancia en el grupo.
Incluya pods adicionales en el momento de la implementación, en función de la carga de trabajo.
Bloque de almacenamiento
El bloque de almacenamiento proporciona ingesta de datos a través de Spark, almacenamiento en HDFS, acceso a datos a través de HDFS y puntos de conexión de SQL Server.
| Nombre del pod | Count | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|---|
storage-0-# |
1 o más. Incluya pods adicionales en el momento de la implementación, en función de la carga de trabajo. | StatefulSet | - hadoop- mssql-server- fluentbit |
nmnode-0-# |
1 o más para alta disponibilidad | StatefulSet | - hadoop- fluentbit |
sparkehead-# |
1 o más para alta disponibilidad | StatefulSet | - hadoop-yarn-jobhistory- hadoop-livy-sparkhistory- hadoop-hivemetastore-- fluentbit |
zookeeper |
0 o 3 para alta disponibilidad. | StatefulSet | - zookeeper- fluentbit |
Grupo de aplicaciones
El grupo de aplicaciones se incluye en algunos de los perfiles de configuración de pruebas. El grupo de aplicaciones hospeda los proxies del servicio de aplicación que se definen al implementar las aplicaciones para los clústeres de macrodatos.
appproxy es una API web que se sitúa delante de las aplicaciones del grupo de aplicaciones. Autentica a los usuarios y, después, enruta las solicitudes a las aplicaciones.
| Nombre del pod | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|
appproxy |
ReplicaSet | - app-service-proxy- fluentbit |
Para obtener más información, vea Introducción a la implementación de aplicaciones en un clúster de macrodatos.
Incluya pods adicionales en el momento de la implementación, en función de la carga de trabajo.
Servicio de puerta de enlace
Los servicios de puerta de enlace proporcionan la puerta de enlace Knox a Spark, HDFS, Yarn y las interfaces de usuario de Yarn y Spark.
| Nombre del pod | Tipo del controlador de Kubernetes | Contenedores |
|---|---|---|
gateway-<#> |
StatefulSet | - knox- fluentbit |
Solo se admite una puerta de enlace.
Referencias de contenedor de código abierto
Para obtener información sobre proyectos y versiones específicos de código abierto, consulte el artículo Referencia de software de código abierto.
Pasos siguientes
Para obtener más información sobre Clústeres de macrodatos de SQL Server, vea los recursos siguientes: