Configuración de un cliente de ciencia de datos para el desarrollo de Python en SQL Server Machine Learning Services
Se aplica a: ![]() SQL Server 2016 (13.x),
SQL Server 2016 (13.x), ![]() SQL Server 2017 (14.x) y
SQL Server 2017 (14.x) y ![]() SQL Server 2019 (15.x),
SQL Server 2019 (15.x), ![]() SQL Server 2019 (15.x) - Linux
SQL Server 2019 (15.x) - Linux
La integración de Python está disponible en SQL Server 2017 y posterior cuando se incluye la opción de Python en una Instalación de Machine Learning Services (en base de datos).
Nota:
Actualmente, este artículo se aplica a SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) y SQL Server 2019 (15.x) solo para Linux.
Para desarrollar e implementar soluciones de Python para SQL Server, instale revoscalepy de Microsoft y otras bibliotecas de Python en la estación de trabajo de desarrollo. La biblioteca revoscalepy, que también se encuentra en la instancia de SQL Server remota, coordina las solicitudes de procesamiento entre ambos sistemas.
En este artículo se aprende a configurar una estación de trabajo de desarrollo de Python que permite interactuar con una instancia de SQL Server remota habilitada para el aprendizaje automático y la integración de Python. Después de realizar los pasos de este artículo, dispondrá de las mismas bibliotecas de Python que en SQL Server. También se sabe cómo enviar procesamientos de inserción desde una sesión de Python local a una sesión remota de Python en SQL Server.
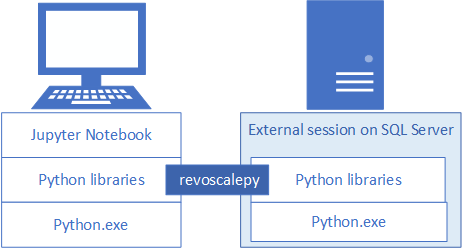
Para validar la instalación, puede usar cuadernos integrados de Jupyter Notebook, como se explica en este artículo, o vincular las bibliotecas a PyCharm o a cualquier otro IDE que use normalmente.
Sugerencia
Para ver una demostración en vídeo de estos ejercicios, vea Ejecución remota de R y Python en SQL Server desde cuadernos de Jupyter Notebook.
Herramientas de uso común
Tanto si es un desarrollador de Python nuevo en SQL como si es un desarrollador de SQL nuevo en Python y el análisis en base de datos, necesita una herramienta de desarrollo de Python y un editor de consultas de T-SQL como SQL Server Management Studio (SSMS) para usar todas las capacidades de análisis en base de datos.
Para el desarrollo de Python puede usar cuadernos de Jupyter Notebook, que se incluyen en la distribución de Anaconda instalada por SQL Server. En este artículo se explica cómo iniciar cuadernos de Jupyter Notebook para poder ejecutar el código de Python de forma local y remota en SQL Server.
SSMS es una descarga independiente que resulta útil para crear y ejecutar procedimientos almacenados en SQL Server, incluidos aquellos que contienen código de Python. Prácticamente cualquier código de Python que escriba en cuadernos de Jupyter Notebook se puede insertar en un procedimiento almacenado. Puede ejecutar paso a paso otros inicios rápidos para obtener información sobre SSMS y Python insertado.
1 - Instalar paquetes de Python
Las estaciones de trabajo locales deben tener las mismas versiones de paquete de Python que las de SQL Server, incluida la distribución base de Anaconda 4.2.0 con Python 3.5.2, y los paquetes específicos de Microsoft.
Un script de instalación agrega tres bibliotecas específicas de Microsoft al cliente de Python. El script instala lo siguiente:
- revoscalepy, se usa para definir los objetos de origen de datos y el contexto de proceso.
- microsoftml, que proporciona algoritmos de aprendizaje automático.
- azureml, que se aplica a tareas de operatividad asociadas a un contexto de servidor independiente y puede tener un uso limitado en el análisis en la base de datos.
Descargue un script de instalación. En la página de GitHub adecuada, selecciona Descargar archivo sin formato.
https://aka.ms/mls-py instala la versión 9.2.1 de los paquetes de Python de Microsoft. Esta versión corresponde a una instancia de SQL Server predeterminada.
https://aka.ms/mls93-py instala la versión 9.3 de los paquetes de Python de Microsoft.
Abra una ventana de PowerShell con permisos de administrador elevados (haga clic con el botón derecho en Ejecutar como administrador).
Vaya a la carpeta en la que ha descargado el instalador y ejecute el script. Agregue el argumento de línea de comandos
-InstallFolderpara especificar una ubicación de carpeta para las bibliotecas. Por ejemplo:cd {{download-directory}} .\Install-PyForMLS.ps1 -InstallFolder "C:\path-to-python-for-mls"
Si omite la carpeta de instalación, el valor predeterminado es %ProgramFiles%\Microsoft\PyForMLS.
La instalación tarda algún tiempo en completarse. Puede supervisar el progreso en la ventana de PowerShell. Una vez finalizada la instalación, tiene un conjunto completo de paquetes.
Sugerencia
Se recomienda leer las Preguntas más frecuentes sobre Python para Windows a fin de obtener información general sobre la ejecución de programas de Python en Windows.
2 - Buscar los archivos ejecutables
Todavía en PowerShell, vea el contenido de la carpeta de instalación para confirmar que se han instalado Python.exe, los scripts y otros paquetes.
Escriba
cd \para ir a la unidad raíz y luego escriba la ruta de acceso especificada para-InstallFolderen el paso anterior. Si ha omitido este parámetro durante la instalación, el valor predeterminado escd %ProgramFiles%\Microsoft\PyForMLS.Escriba
dir *.exepara ver los archivos ejecutables. Debería ver python.exe, pythonw.exe y uninstall-anaconda.exe.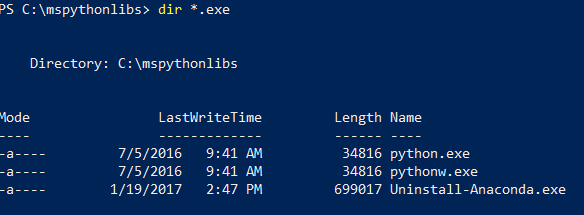
En los sistemas que tienen varias versiones de Python, no olvide usar este archivo Python.exe concreto si quiere cargar revoscalepy y otros paquetes de Microsoft.
Nota:
El script de instalación no modifica la variable de entorno PATH en el equipo, lo que significa que el nuevo intérprete y los módulos de Python que acaba de instalar no están disponibles automáticamente para otras herramientas que pueda tener. Para obtener ayuda para vincular las bibliotecas y el intérprete de Python a las herramientas, vea Instalar un IDE.
3 - Abrir cuadernos de Jupyter Notebook
Anaconda incluye cuadernos de Jupyter Notebook. Como paso siguiente, cree un cuaderno y ejecute el código de Python que contenga las bibliotecas que acaba de instalar.
En el símbolo del sistema de PowerShell, en el directorio
%ProgramFiles%\Microsoft\PyForMLS, abra cuadernos de Jupyter Notebook desde la carpeta Scripts:.\Scripts\jupyter-notebookDebe abrirse un cuaderno en el explorador predeterminado en
https://localhost:8889/tree.Otra manera de empezar es hacer doble clic en jupyter-notebook.exe.
Seleccione Nuevo y, a continuación, seleccione Python 3.
Escriba
import revoscalepyy ejecute el comando para cargar una de las bibliotecas específicas de Microsoft.Escriba y ejecute
print(revoscalepy.__version__)para devolver la información de versión. Debería ver 9.2.1 o 9.3.0. Puede usar cualquiera de estas versiones con revoscalepy en el servidor.Escriba una serie más compleja de instrucciones. Este ejemplo genera estadísticas de resumen mediante rx_summary sobre un conjunto de datos local. Otras funciones obtienen la ubicación de los datos de ejemplo y crean un objeto de origen de datos para un archivo .xdf local.
import os from revoscalepy import rx_summary from revoscalepy import RxXdfData from revoscalepy import RxOptions sample_data_path = RxOptions.get_option("sampleDataDir") print(sample_data_path) ds = RxXdfData(os.path.join(sample_data_path, "AirlineDemoSmall.xdf")) summary = rx_summary("ArrDelay+DayOfWeek", ds) print(summary)
En la captura de pantalla siguiente se muestra la entrada y una parte de la salida, recortada por motivos de brevedad.

4 - Obtener permisos SQL
Para conectarse a una instancia de SQL Server a fin de ejecutar scripts y cargar datos, debe tener un inicio de sesión válido en el servidor de base de datos. Puede usar un inicio de sesión de SQL o la autenticación integrada de Windows. Por lo general, se recomienda usar la autenticación integrada de Windows, pero el inicio de sesión de SQL es más sencillo en algunos escenarios, especialmente si el script contiene cadenas de conexión a datos externos.
Como mínimo, la cuenta usada para ejecutar código debe tener permiso para leer en las bases de datos con las que se está trabajando, además del permiso especial EXECUTE ANY EXTERNAL SCRIPT. La mayoría de los desarrolladores también necesitan permisos para crear procedimientos almacenados y para escribir datos en tablas que contienen datos de entrenamiento o datos puntuados.
Pida al administrador de bases de datos que configure los siguientes permisos para la cuenta en la base de datos donde usa Python:
- EXECUTE ANY EXTERNAL SCRIPT para ejecutar Python en el servidor.
- Privilegios db_datareader para ejecutar las consultas usadas para entrenar el modelo.
- db_datawriter para escribir datos de entrenamiento o datos puntuados.
- db_owner para crear objetos como procedimientos almacenados, tablas y funciones. También necesita db_owner para crear bases de datos de prueba y ejemplo.
Si el código requiere paquetes que no se instalan de forma predeterminada con SQL Server, hable con el administrador de bases de datos para que los paquetes se instalen con la instancia. SQL Server es un entorno protegido y hay restricciones sobre la ubicación donde se pueden instalar los paquetes. No se recomienda la instalación ad hoc de paquetes como parte del código, aunque tenga derechos. Además, considere siempre cuidadosamente las implicaciones de seguridad antes de instalar nuevos paquetes en la biblioteca de servidores.
5 - Crear datos de prueba
Si tiene permisos para crear una base de datos en el servidor remoto, puede ejecutar el código siguiente para crear la base de datos de demostración Iris que se usa en los pasos restantes de este artículo.
5-1 - Crear la base de datos irissql de forma remota
import pyodbc
# creating a new db to load Iris sample in
new_db_name = "irissql"
connection_string = "Driver=SQL Server;Server=localhost;Database={0};Trusted_Connection=Yes;"
# you can also swap Trusted_Connection for UID={your username};PWD={your password}
cnxn = pyodbc.connect(connection_string.format("master"), autocommit=True)
cnxn.cursor().execute("IF EXISTS(SELECT * FROM sys.databases WHERE [name] = '{0}') DROP DATABASE {0}".format(new_db_name))
cnxn.cursor().execute("CREATE DATABASE " + new_db_name)
cnxn.close()
print("Database created")
5-2 - Importar el ejemplo Iris desde SkLearn
from sklearn import datasets
import pandas as pd
# SkLearn has the Iris sample dataset built in to the package
iris = datasets.load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
5-3 - Usar las API de Revoscalepy para crear una tabla y cargar los datos de Iris
from revoscalepy import RxSqlServerData, rx_data_step
# Example of using RX APIs to load data into SQL table. You can also do this with pyodbc
table_ref = RxSqlServerData(connection_string=connection_string.format(new_db_name), table="iris_data")
rx_data_step(input_data = df, output_file = table_ref, overwrite = True)
print("New Table Created: Iris")
print("Sklearn Iris sample loaded into Iris table")
6 - Probar la conexión remota
Antes de probar el paso siguiente, asegúrese de que tiene permisos en la instancia de SQL Server y una cadena de conexión a la base de datos de ejemplo Iris. Si la base de datos no existe y tiene permisos suficientes, puede crear una base de datos con estas instrucciones en línea.
Reemplace la cadena de conexión por valores válidos. En el código de ejemplo se usa "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;", pero el código debe especificar un servidor remoto, posiblemente con un nombre de instancia, y una opción de credencial que se asigne al inicio de sesión de base de datos.
6-1 Definir una función
En el código siguiente se define una función que se envía a SQL Server en un paso posterior. Cuando se ejecuta, usa los datos y las bibliotecas (revoscalepy, pandas, matplotlib) en el servidor remoto para crear gráficos de dispersión del conjunto de datos Iris. Devuelve la secuencia de bytes del archivo .png a los cuadernos de Jupyter Notebook para que se represente en el explorador.
def send_this_func_to_sql():
from revoscalepy import RxSqlServerData, rx_import
from pandas.tools.plotting import scatter_matrix
import matplotlib.pyplot as plt
import io
# remember the scope of the variables in this func are within our SQL Server Python Runtime
connection_string = "Driver=SQL Server;Server=localhost;Database=irissql;Trusted_Connection=Yes;"
# specify a query and load into pandas dataframe df
sql_query = RxSqlServerData(connection_string=connection_string, sql_query = "select * from iris_data")
df = rx_import(sql_query)
scatter_matrix(df)
# return bytestream of image created by scatter_matrix
buf = io.BytesIO()
plt.savefig(buf, format="png")
buf.seek(0)
return buf.getvalue()
6-2 Enviar la función a SQL Server
En este ejemplo, cree el contexto de proceso remoto y luego envíe la ejecución de la función a SQL Server con rx_exec. La función rx_exec es útil porque acepta un contexto de proceso como argumento. Cualquier función que quiera ejecutar de forma remota debe tener un argumento de contexto de proceso. Algunas funciones, como rx_lin_mod, admiten este argumento directamente. En el caso de las operaciones que no lo hacen, puede usar rx_exec para entregar el código en un contexto de proceso remoto.
En este ejemplo no es necesario transferir ningún dato sin procesar desde SQL Server a Jupyter Notebook. Todo el procesamiento se produce en la base de datos Iris y solo el archivo de imagen se devuelve al cliente.
from IPython import display
import matplotlib.pyplot as plt
from revoscalepy import RxInSqlServer, rx_exec
# create a remote compute context with connection to SQL Server
sql_compute_context = RxInSqlServer(connection_string=connection_string.format(new_db_name))
# use rx_exec to send the function execution to SQL Server
image = rx_exec(send_this_func_to_sql, compute_context=sql_compute_context)[0]
# only an image was returned to my jupyter client. All data remained secure and was manipulated in my db.
display.Image(data=image)
En la captura de pantalla siguiente se muestra la entrada y la salida del gráfico de dispersión.

7 - Iniciar Python desde herramientas
Dado que los desarrolladores suelen trabajar con varias versiones de Python, el programa de instalación no agrega Python a PATH. Para usar el archivo ejecutable y las bibliotecas de Python instalados por el programa de instalación, vincule el IDE a Python.exe en la ruta de acceso que también proporciona revoscalepy y microsoftml.
Línea de comandos
Al ejecutar Python.exe desde %ProgramFiles%\Microsoft\PyForMLS (o cualquier ubicación especificada para la instalación de la biblioteca cliente de Python), tiene acceso a la distribución completa de Anaconda más los módulos de Python de Microsoft, revoscalepy y microsoftml.
- Vaya a
%ProgramFiles%\Microsoft\PyForMLSy ejecute Python.exe. - Abra la ayuda interactiva:
help(). - Escriba el nombre de un módulo en el cuadro de la ayuda:
help> revoscalepy. La ayuda devuelve el nombre, el contenido del paquete, la versión y la ubicación del archivo. - Se devuelve la información de paquete y versión en el cuadro help>:
revoscalepy. Presione Entrar varias veces para salir de la ayuda. - Importe un módulo:
import revoscalepy.
Cuadernos de Jupyter Notebook
En este artículo se usan cuadernos integrados de Jupyter Notebook para mostrar las llamadas de función a revoscalepy. Si no está familiarizado con esta herramienta, en la captura de pantalla siguiente se muestra cómo encajan las piezas y por qué todo "simplemente funciona".
La carpeta principal %ProgramFiles%\Microsoft\PyForMLS contiene Anaconda más los paquetes de Microsoft. Los Jupyter Notebook se incluyen en Anaconda, en la carpeta Scripts, y los ejecutables de Python se registran automáticamente en Jupyter Notebook. Los paquetes que se encuentran en paquetes del sitio se pueden importar en un cuaderno, incluidos los tres paquetes de Microsoft que se usan para la ciencia de datos y el aprendizaje automático.
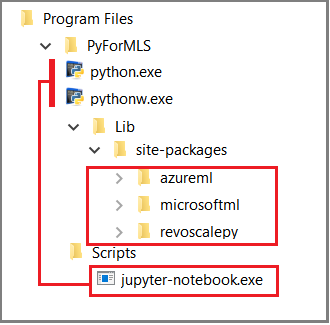
Si usa otro IDE, tiene que vincular los ejecutables de Python y las bibliotecas de funciones a la herramienta. En las secciones siguientes se proporcionan instrucciones para herramientas de uso común.
Visual Studio
Si tiene Python en Visual Studio, use las siguientes opciones de configuración para crear un entorno de Python que incluya los paquetes de Python de Microsoft.
| Opción de configuración | valor |
|---|---|
| Prefix path (Ruta de acceso de prefijo) | %ProgramFiles%\Microsoft\PyForMLS |
| Interpreter path (Ruta de acceso del intérprete) | %ProgramFiles%\Microsoft\PyForMLS\python.exe |
| Windowed interpreter (Intérprete en ventanas) | %ProgramFiles%\Microsoft\PyForMLS\pythonw.exe |
Para obtener ayuda para configurar un entorno de Python, consulte Administración de entornos de Python en Visual Studio.
PyCharm
En PyCharm, establezca el intérprete en el ejecutable de Python instalado.
En un nuevo proyecto, en Configuración, seleccione Agregar local.
Escriba
%ProgramFiles%\Microsoft\PyForMLS\.
Ahora puede importar los módulos revoscalepy, microsoftml o azureml. También puede seleccionar Herramientas>Consola de Python para abrir una ventana interactiva.