Escenarios de uso de tablas temporales
se aplica a:![]() SQL Server 2016 (13.x) y versiones posteriores
SQL Server 2016 (13.x) y versiones posteriores ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() SQL Database en Microsoft Fabric
SQL Database en Microsoft Fabric
Las tablas temporales con control de versiones del sistema son útiles en escenarios en los que es necesario el historial de seguimiento de cambios de datos. Debido a las enormes ventajas de productividad, se recomienda tener en cuenta las tablas temporales en los siguientes casos de uso.
Auditoría de datos
Puede usar el control de versiones del sistema temporal en tablas que almacenan información crítica, para realizar el seguimiento de qué ha cambiado y cuándo, y para realizar análisis forense de datos en cualquier momento.
Las tablas temporales permiten planear escenarios de auditoría de datos en las primeras fases del ciclo de desarrollo, o bien agregar auditoría de datos a aplicaciones o soluciones existentes cuando se necesita.
En el siguiente diagrama se muestra una tabla Employee con una muestra de datos que incluye versiones de fila actuales (marcadas en color azul) e históricas (marcadas en color gris).
En la parte derecha del diagrama se visualizan las versiones de fila en el eje de tiempo y las filas que selecciona con diferentes tipos de consulta en una tabla temporal, con o sin la cláusula SYSTEM_TIME.

Habilitación del control de versiones del sistema en una nueva tabla para auditoría de datos
Si identifica información que necesita datos de auditoría, cree tablas de base de datos como tablas temporales con control de versiones del sistema. En el ejemplo siguiente se muestra un escenario con una tabla denominada Employee en la hipotética base de datos RR. HH:
CREATE TABLE Employee (
[EmployeeID] INT NOT NULL PRIMARY KEY CLUSTERED,
[Name] NVARCHAR(100) NOT NULL,
[Position] VARCHAR(100) NOT NULL,
[Department] VARCHAR(100) NOT NULL,
[Address] NVARCHAR(1024) NOT NULL,
[AnnualSalary] DECIMAL(10, 2) NOT NULL,
[ValidFrom] DATETIME2(2) GENERATED ALWAYS AS ROW START,
[ValidTo] DATETIME2(2) GENERATED ALWAYS AS ROW END,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
En Creación de una tabla temporal con control de versiones del sistema se describen varias opciones para crear una tabla temporal con control de versiones del sistema.
Habilitación del control de versiones del sistema en una tabla existente para auditoría de datos
Si necesita realizar auditoría de datos en bases de datos existentes, utilice ALTER TABLE para extender las tablas no temporales y convertirlas en tablas con control de versiones del sistema. Para evitar cambios importantes en la aplicación, agregue las columnas de periodo como HIDDEN, como se explica en Creación de una tabla temporal con control de versiones del sistema.
En el ejemplo siguiente se muestra cómo habilitar el control de versiones del sistema en una tabla Employee existente en una hipotética base de datos de recursos humanos. Habilita el control de versiones del sistema en la tabla Employee en dos pasos. En primer lugar, las nuevas columnas de periodo se agregan como HIDDEN. Después, se crea la tabla de historial predeterminada.
ALTER TABLE Employee ADD
ValidFrom DATETIME2(2) GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2(2) GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
Importante
La precisión del tipo de datos datetime2 es la misma en la tabla de origen y en la tabla de historial con control de versiones del sistema.
Después de ejecutar el script anterior, todos los cambios de datos se recopilarán de forma transparente en la tabla de historial. En un escenario de auditoría de datos típico, consultaría todos los cambios que se aplicaron a una fila individual en un período de tiempo de interés. La tabla de historial predeterminada se crea con un árbol B de almacén de filas agrupado para tratar eficazmente este caso de uso.
Nota:
La documentación utiliza el término árbol B generalmente en referencia a los índices. En los índices del almacén de filas, el motor de la base de datos implementa un árbol B+. Esto no se aplica a los índices de almacén de columnas ni a los índices de tablas optimizadas para memoria. Para obtener más información, consulte la guía de diseño y arquitectura de índices de SQL Server y Azure SQL.
Realización de análisis de datos
Después de habilitar el control de versiones mediante cualquier de los enfoques anteriores, basta una consulta para realizar la auditoría de datos. La siguiente consulta busca versiones de fila para los registros de la tabla Employee con EmployeeID = 1000 que estaban activas al menos durante una parte del periodo comprendido entre el 1 de enero de 2021 y el 1 de enero de 2022 (incluido el límite superior):
SELECT * FROM Employee
FOR SYSTEM_TIME BETWEEN '2021-01-01 00:00:00.0000000'
AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Reemplace FOR SYSTEM_TIME BETWEEN...AND por FOR SYSTEM_TIME ALL para analizar todo el historial de cambios de datos de ese empleado en particular:
SELECT * FROM Employee
FOR SYSTEM_TIME ALL
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Para buscar versiones de fila que estaban activas solo dentro de un período (y no fuera de él), use CONTAINED IN. Esta consulta es eficaz porque solo consulta la tabla de historial:
SELECT * FROM Employee
FOR SYSTEM_TIME CONTAINED IN (
'2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000'
)
WHERE EmployeeID = 1000
ORDER BY ValidFrom;
Por último, en algunos escenarios de auditoría, es posible que quiera ver el aspecto de toda la tabla en un momento dado en el pasado:
SELECT * FROM Employee
FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
Las tablas temporales con control de versiones del sistema almacenan valores para columnas de periodo en la zona horaria UTC, aunque es posible que compruebe que es más conveniente trabajar con la zona horaria local, tanto para filtrar datos como para mostrar resultados. En el ejemplo de código siguiente se muestra cómo aplicar una condición de filtrado, que se ha especificado en la zona horaria local y después se ha convertido a UTC mediante la cláusula AT TIME ZONE, introducida en SQL Server 2016 (13.x):
/* Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time';
/* Convert AS OF filter to UTC*/
SET @asOf = DATEADD(HOUR, - 9, @asOf) AT TIME ZONE 'UTC';
SELECT EmployeeID,
[Name],
Position,
Department,
[Address],
[AnnualSalary],
ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT,
ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf
WHERE EmployeeId = 1000;
El uso de AT TIME ZONE es útil para todos los demás escenarios donde se usan tablas con versión del sistema.
Las condiciones de filtrado especificadas en cláusulas temporales con FOR SYSTEM_TIME son compatibles con SAR. SARG significa argumento de búsqueda, y compatible con SARG significa que SQL Server puede usar el índice agrupado subyacente para realizar una búsqueda en lugar de una operación de examen. Para más información, vea la Guía de diseño y de arquitectura de índices de SQL Server.
Si consulta directamente la tabla de historial, asegúrese de que la condición de filtrado también sea compatible con SARG, mediante la especificación de los filtros en formato <period column> { < | > | =, ... } date_condition AT TIME ZONE 'UTC'.
Si aplica AT TIME ZONE a columnas de periodo, SQL Server realiza un examen de tabla o índice, lo que puede resultar muy costoso. Evite este tipo de condición en las consultas:
<period column> AT TIME ZONE '<your time zone>' > {< | > | =, ...} date_condition.
Para más información, vea Consulta de los datos de una tabla temporal con control de versiones del sistema.
Análisis a un momento dado (viaje en el tiempo)
En lugar de centrarse en los cambios en registros individuales, los escenarios de desplazamiento en el tiempo muestran cómo cambian conjuntos de datos completos en el tiempo. A veces, el viaje en el tiempo incluye varias tablas temporales relacionadas, cada una de ellas cambiando a un ritmo independiente, para las que desea analizar:
- Tendencias de los indicadores importantes en los datos históricos y actuales
- Instantánea exacta de todos los datos "a partir de" cualquier momento dado del pasado (ayer, hace un mes, etc.)
- Diferencias entre dos momentos dados de interés (hace un mes frente a hace tres meses, por ejemplo)
Hay muchos escenarios reales en los que es necesario el análisis de viaje en el tiempo. Para ilustrar este escenario de uso, se examinará OLTP con el historial generado automáticamente.
OLTP con historial de datos generado automáticamente
En sistemas de procesamiento de transacciones, puede analizar cómo cambian las métricas importantes en el tiempo. Idealmente, analizar el historial no debería afectar al rendimiento de la aplicación OLTP donde el acceso al estado más reciente de los datos debe producirse con una latencia y bloqueo de datos mínimos. Puede usar tablas temporales con versión del sistema a fin de mantener de forma transparente el historial completo de cambios para su análisis posterior, independientemente de los datos actuales, con un impacto mínimo en la carga de trabajo OLTP principal.
Para cargas de trabajo de procesamiento transaccional elevadas en SQL Server e Instancia administrada de Azure SQL, recomendamos utilizar tablas temporales versionadas por el sistema junto con tablas optimizadas para memoria. Estas opciones permiten almacenar los datos actuales en memoria y mantener todo el historial de cambios en disco de manera rentable.
Para la tabla de historial, se recomienda utilizar un índice de almacén de columnas agrupado por las razones siguientes:
El análisis de tendencias típico aprovecha el rendimiento de las consultas que proporciona un índice de almacén de columnas agrupado.
La tarea de vaciado de datos con tablas optimizadas para memoria funciona mejor con mucha carga de trabajo OLTP cuando la tabla de historial tiene un índice de almacén de columnas agrupado.
Un índice de almacén de columnas agrupado proporciona una compresión excelente, especialmente en escenarios donde no todas las columnas se cambian al mismo tiempo.
El uso de tablas temporales con OLTP en memoria reduce la necesidad de mantener todo el conjunto de datos en memoria y permite distinguir fácilmente entre los datos activos e inactivos.
Ejemplos de escenarios reales que encajan bien en esta categoría son la administración de inventarios o la compraventa de divisas, entre otros.
El diagrama siguiente muestra el modelo de datos simplificado utilizado para la administración de inventarios:

En el ejemplo de código siguiente se crea ProductInventory como una tabla temporal con control de versiones del sistema, con un índice de almacén de columnas agrupado en la tabla de historial (que realmente reemplaza al índice de almacén de filas que se crea de manera predeterminada):
Nota:
Asegúrese de que la base de datos permite la creación de tablas optimizadas para memoria. Vea Crear una tabla con optimización para memoria y un procedimiento almacenado compilado de forma nativa.
USE TemporalProductInventory;
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type
FROM SYS.TABLES
WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory]
SET (SYSTEM_VERSIONING = OFF);
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory] (
ProductId INT NOT NULL,
LocationID INT NOT NULL,
Quantity INT NOT NULL CHECK (Quantity >= 0),
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START NOT NULL,
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (
ProductId,
LocationId
)
)
WITH (
MEMORY_OPTIMIZED = ON,
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory
ON [ProductInventoryHistory] WITH (DROP_EXISTING = ON);
Para el modelo anterior, este puede ser el aspecto del procedimiento para mantener el inventario:
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId INT,
@locationId INT,
@quantityIncrement INT
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId
AND LocationId = @locationId
-- If zero rows were updated then this is an insert
-- of the new product for a given location
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory] (
[ProductId], [LocationID], [Quantity]
)
VALUES (@productId, @locationId, @quantityIncrement)
END
END;
El procedimiento almacenado spUpdateInventory inserta un nuevo producto en el inventario o actualiza la cantidad de productos para la ubicación específica. La lógica de negocios es muy sencilla y se centra en mantener la precisión del estado más reciente en todo momento incrementando o disminuyendo el campo Quantity en la actualización de la tabla, mientras que las tablas con control de versiones del sistema agregan de forma transparente la dimensión de historial a los datos, como se muestra en el diagrama siguiente.

Ahora, la consulta del estado más reciente puede realizarse eficazmente desde el módulo compilado de forma nativa:
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC
WITH (
TRANSACTION ISOLATION LEVEL = SNAPSHOT,
LANGUAGE = N'English'
)
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
El análisis de los cambios de datos en el tiempo pasa a ser una tarea sencilla con la cláusula FOR SYSTEM_TIME ALL, como se muestra en el ejemplo siguiente:
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId,
LocationId,
Quantity,
ValidFrom,
ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
En el diagrama siguiente se muestra el historial de datos de un producto que se puede representar fácilmente si se importa la vista anterior en Power Query, Power BI o una herramienta de inteligencia empresarial similar:

Las tablas temporales se pueden utilizar en este escenario para realizar otros tipos de análisis de recorrido en el tiempo, como reconstruir el estado del inventario AS OF a cualquier momento dado del pasado o comparar instantáneas que pertenecen a diferentes momentos en el tiempo.
Para este escenario de uso, también puede extender las tablas Product y Location para convertirlas en tablas temporales y permitir así un análisis posterior del historial de cambios de UnitPrice y NumberOfEmployee.
ALTER TABLE Product ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DF_ValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DF_ValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location] ADD
ValidFrom DATETIME2 GENERATED ALWAYS AS ROW START HIDDEN
CONSTRAINT DFValidFrom DEFAULT DATEADD (SECOND, -1, SYSUTCDATETIME()),
ValidTo DATETIME2 GENERATED ALWAYS AS ROW END HIDDEN
CONSTRAINT DFValidTo DEFAULT '9999.12.31 23:59:59.99',
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
Como el modelo de datos ahora implica varias tablas temporales, el procedimiento recomendada para el análisis de AS OF consiste en crear una vista que extraiga los datos necesarios de las tablas relacionadas y aplicar FOR SYSTEM_TIME AS OF a la vista, ya que esto simplifica considerablemente la reconstrucción del estado de todo el modelo de datos:
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId,
PrInv.LocationId,
P.ProductName,
L.LocationName,
PrInv.Quantity,
P.UnitPrice,
L.NumberOfEmployees,
P.ValidFrom AS ProductStartTime,
P.ValidTo AS ProductEndTime,
L.ValidFrom AS LocationStartTime,
L.ValidTo AS LocationEndTime,
PrInv.ValidFrom AS InventoryStartTime,
PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory AS PrInv
INNER JOIN dbo.Product AS P
ON PrInv.ProductId = P.ProductID
INNER JOIN dbo.Location AS L
ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
En la captura de pantalla siguiente se muestra el plan de ejecución generado para la consulta SELECT. Esto ilustra que el motor de bases de datos controla toda la complejidad de trabajar con las relaciones temporales:

Utilice el código siguiente para comparar el estado del inventario de productos entre dos momentos dados (hace un día y hace un mes):
DECLARE @dayAgo DATETIME2 = DATEADD (DAY, -1, SYSUTCDATETIME());
DECLARE @monthAgo DATETIME2 = DATEADD (MONTH, -1, SYSUTCDATETIME());
SELECT inventoryDayAgo.ProductId,
inventoryDayAgo.ProductName,
inventoryDayAgo.LocationName,
inventoryDayAgo.Quantity AS QuantityDayAgo,
inventoryMonthAgo.Quantity AS QuantityMonthAgo,
inventoryDayAgo.UnitPrice AS UnitPriceDayAgo,
inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
INNER JOIN vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId
AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
Detección de anomalías
La detección de anomalías (o detección de valores atípicos) es la identificación de los elementos que no se ajustan a un patrón esperado u otros elementos en un conjunto de datos. Puede utilizar tablas temporales con versión del sistema para detectar anomalías que se producen periódica o irregularmente como puede usar consultas temporales para encontrar rápidamente patrones específicos. De qué anomalías se trata depende del tipo de datos que se recopilan y de la lógica de negocios.
En el ejemplo siguiente se muestra una lógica simplificada para detectar "picos" en las cifras de ventas. Supongamos que trabaja con una tabla temporal que recopila el historial de los productos comprados:
CREATE TABLE [dbo].[Product] (
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED,
[ProductName] [varchar](100) NOT NULL,
[DailySales] INT NOT NULL,
[ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL,
[ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL,
PERIOD FOR SYSTEM_TIME([ValidFrom], [ValidTo])
)
WITH (
SYSTEM_VERSIONING = ON (
HISTORY_TABLE = [dbo].[ProductHistory],
DATA_CONSISTENCY_CHECK = ON
)
);
El diagrama siguiente muestra las compras a lo largo del tiempo:

Si durante los días normales el número de productos comprados tiene una pequeña variación, la siguiente consulta identifica los valores atípicos de singleton: muestras cuya diferencia en comparación con sus vecinos inmediatos es considerable (el doble), mientras que las muestras adyacentes no difieren significativamente (menos del 20 %):
WITH CTE (
ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo
)
AS (
SELECT ProdId,
LAG(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS PrevValue,
DailySales,
LEAD(DailySales, 1, 1) OVER (PARTITION BY ProdId ORDER BY ValidFrom) AS NextValue,
ValidFrom,
ValidTo
FROM Product
FOR SYSTEM_TIME ALL
)
SELECT ProdId,
PrevValue,
CurrentValue,
NextValue,
ValidFrom,
ValidTo,
ABS(PrevValue - NextValue) / convert(FLOAT, (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END)) AS PrevToNextDiff,
ABS(CurrentValue - PrevValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END)) AS CurrentToPrevDiff,
ABS(CurrentValue - NextValue) / convert(FLOAT, (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END)) AS CurrentToNextDiff
FROM CTE
WHERE ABS(PrevValue - NextValue) / (
CASE
WHEN NextValue > PrevValue THEN PrevValue
ELSE NextValue
END) < 0.2
AND ABS(CurrentValue - PrevValue) / (
CASE
WHEN CurrentValue > PrevValue THEN PrevValue
ELSE CurrentValue
END) > 2
AND ABS(CurrentValue - NextValue) / (
CASE
WHEN CurrentValue > NextValue THEN NextValue
ELSE CurrentValue
END) > 2;
Nota:
Este ejemplo está simplificado deliberadamente. En los escenarios de producción, probablemente use métodos estadísticos avanzados para identificar las muestras que no siguen el patrón común.
Dimensiones de variación lenta
Las dimensiones de almacenamiento de datos normalmente contienen datos relativamente estáticos sobre entidades como ubicaciones geográficas, clientes o productos. Sin embargo, algunos escenarios también requieren realizar el seguimiento de cambios de datos en tablas de dimensiones. Dado que la modificación en las dimensiones ocurre con mucha menos frecuencia, de una forma impredecible y fuera de la programación de actualizaciones normal que se aplica a tablas de hechos, estos tipos de tablas de dimensiones se denominan dimensiones de variación lenta (DVL).
Existen varias categorías de dimensiones de variación lenta basadas en la forma de conservar el historial de cambios:
| Tipo de dimensión | Detalles |
|---|---|
| Tipo 0 | No se conserva el historial. Los atributos de dimensión reflejan los valores originales. |
| Tipo 1 | Los atributos de dimensión reflejan los valores más recientes (los valores anteriores se sobrescriben). |
| Tipo 2 | Cada versión de miembro de dimensión se representa con una fila independiente en la tabla normalmente con columnas que representan el período de validez. |
| Tipo 3 | Mantenimiento del historial limitado para los atributos seleccionados mediante columnas adicionales en la misma fila |
| Tipo 4 | Mantener el historial en la tabla independiente mientras la tabla de dimensiones original mantiene las versiones de miembro de dimensión más recientes (actual). |
Cuando se elige una estrategia de DVL, es responsabilidad de la capa ETL, (extracción, transformación y carga) mantener la precisión de las tablas de dimensiones, para lo que normalmente se necesita código más complejo y un mantenimiento adicional.
Las tablas temporales con versión del sistema se pueden usar para reducir considerablemente la complejidad del código, ya que el historial de los datos se conserva automáticamente. Dada su implementación con dos tablas, las tablas temporales son las más próximas a DVL de tipo 4. Pero como las consultas temporales solo permiten hacer referencia a la tabla actual, también puede plantearse el uso de tablas temporales en entornos donde piensa usar DVL de tipo 2.
Para convertir la dimensión normal en DVL, puede crear una o modificar una existente para convertirla en una tabla temporal con versión del sistema. Si la tabla de dimensiones existente contiene datos históricos, cree una tabla independiente y mueva los datos históricos allí, y mantenga las versiones de dimensión actuales (reales) en la tabla de dimensiones original. Después, utilice la sintaxis ALTER TABLE para convertir la tabla de dimensiones en una tabla temporal con control de versiones del sistema con una tabla de historial predefinida.
En el ejemplo siguiente se ilustra el proceso y se supone que la tabla de dimensiones DimLocation ya tiene ValidFrom y ValidTo como columnas datetime2 que no aceptan valores NULL y que el proceso ETL rellena:
/* Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/* Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory;
/* Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/* Add period definition*/
ALTER TABLE DimLocation
ADD PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo);
/* Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
No se necesita código adicional para mantener DVL durante el proceso de carga de almacenamiento de datos una vez que se ha creado.
En la siguiente ilustración se muestra cómo puede utilizar las tablas temporales en un escenario sencillo que implica dos DVL (DimLocation y DimProduct), y una tabla de hechos.

Para poder utilizar DVL anteriores en los informes, debe ajustar eficazmente las consultas. Por ejemplo, puede que le interese calcular la cantidad total de ventas y el promedio de productos vendidos per cápita durante los últimos seis meses. Las dos métricas necesitan la correlación de datos de la tabla de hechos y las dimensiones que podrían haber cambiado sus atributos importantes para el análisis (DimLocation.NumOfCustomers, DimProduct.UnitPrice). La siguiente consulta calcula correctamente las métricas requeridas:
DECLARE @now DATETIME2 = SYSUTCDATETIME();
DECLARE @sixMonthsAgo DATETIME2;
SET @sixMonthsAgo = DATEADD(month, - 12, SYSUTCDATETIME());
SELECT DimProduct_History.ProductId,
DimLocation_History.LocationId,
SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount,
AVG(F.Quantity / DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimLocation
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
INNER JOIN DimProduct
FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId;
Consideraciones
El uso de tablas temporales con versión del sistema para DVL es aceptable si el período de validez calculado en función del tiempo de transacción de base de datos está bien con la lógica de negocios. Si carga los datos con un retraso importante, el tiempo de la transacción puede no ser aceptable.
De manera predeterminada, las tablas temporales con control de versiones del sistema no permiten cambiar los datos históricos después de la carga (puede modificar el historial después de establecer SYSTEM_VERSIONING en OFF). Esto podría ser una limitación en casos donde el cambio de datos históricos se produce con regularidad.
Las tablas temporales con versión del sistema generan versión de fila en cualquier cambio de columna. Si quiere suprimir nuevas versiones en ciertos cambios de columna, debe incorporar esa limitación en la lógica de ETL.
Si espera un número significativo de filas históricas en tablas de DVL, considere el uso de un índice de almacén de columnas agrupado como la opción de almacenamiento principal para la tabla de historial. El uso de un índice de almacén de columnas reduce la superficie de la tabla de historial y acelera las consultas analíticas.
Reparación de daños en los datos de nivel de fila
Puede basarse en los datos históricos de las tablas temporales con versión del sistema para reparar rápidamente filas individuales a cualquiera de los estados capturados anteriormente. Esta propiedad de las tablas temporales es útil cuando puede localizar filas afectadas o cuando conoce la hora del cambio de datos no deseado. Este conocimiento le permite realizar reparaciones de forma eficaz sin trabajar con copias de seguridad.
Este enfoque tiene varias ventajas:
Es posible controlar el ámbito de la reparación de manera precisa. Los registros que no se ven afectados deben permanecer en el estado más reciente, que suele ser un requisito crítico.
La operación es eficaz y la base de datos permanece en línea para todas las cargas de trabajo que usan los datos.
La propia operación de reparación es con versiones. Tendrá la pista de auditoría de la propia operación de reparación, por lo que puede analizar qué ocurrió posteriormente si es necesario.
La acción de reparación se puede automatizar con relativa facilidad. En el ejemplo de código siguiente se muestra un procedimiento almacenado que realiza la reparación de datos para la tabla Employee usada en un escenario de auditoría de datos.
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
WITH History
AS (
/* Order historical rows by their age in DESC order*/
SELECT
ROW_NUMBER() OVER (PARTITION BY EmployeeID
ORDER BY [ValidTo] DESC) AS RN,
*
FROM Employee FOR SYSTEM_TIME ALL
WHERE YEAR(ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/* Update current row by using N-th row version from history (default is 1 - i.e. last version) */
UPDATE Employee
SET [Position] = H.[Position],
[Department] = H.Department,
[Address] = H.[Address],
AnnualSalary = H.AnnualSalary
FROM Employee E
INNER JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID;
Este procedimiento almacenado toma @EmployeeID y @versionNumber como parámetros de entrada. Este procedimiento restaura de manera predeterminada el estado de fila a la versión más reciente a partir del historial (@versionNumber = 1).
La siguiente imagen muestra el estado de la fila antes y después de la invocación del procedimiento. El rectángulo rojo marca la versión de fila actual que no es correcta, mientras que el rectángulo verde marca la versión correcta del historial.

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1;

Este procedimiento almacenado de reparación puede definirse para aceptar una marca de tiempo exacta en lugar de la versión de fila. Restaura la fila a cualquier versión que estuviera activa para el momento dado proporcionado (es decir, el momento dado AS OF).
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf DATETIME2
AS
/* Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position],
[Department] = History.Department,
[Address] = History.[Address],
AnnualSalary = History.AnnualSalary
FROM Employee AS E
INNER JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History
ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID;
Para el mismo ejemplo de datos, en la siguiente imagen se ilustra un escenario de reparación con una condición de tiempo. Se resaltan el parámetro @asOf, la fila seleccionada en el historial que era real en el momento dado proporcionado y la nueva versión de fila en la tabla actual después de la operación de reparación:

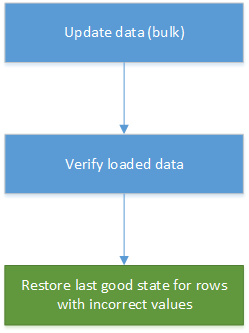
La corrección de datos puede convertirse en parte de la carga de datos automatizada en el almacenamiento de datos y los sistemas de informes. Si un valor recién actualizado no es correcto, en muchos escenarios, la restauración de la versión anterior a partir de historial es una mitigación suficientemente buena. En el siguiente diagrama se muestra cómo se puede automatizar este proceso:
Contenido relacionado
- Tablas temporales
- Introducción a las tablas temporales con control de versiones del sistema
- Comprobaciones de coherencia del sistema de la tabla temporal
- Creación de particiones con tablas temporales
- Consideraciones y limitaciones de las tablas temporales
- Seguridad de la tabla temporal
- Tablas temporales con control de versiones del sistema con tablas optimizadas para memoria
- Funciones y vistas de metadatos de la tabla temporal